 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-inspired Robustness: A Review
Paper and Code
Mar 16, 2021
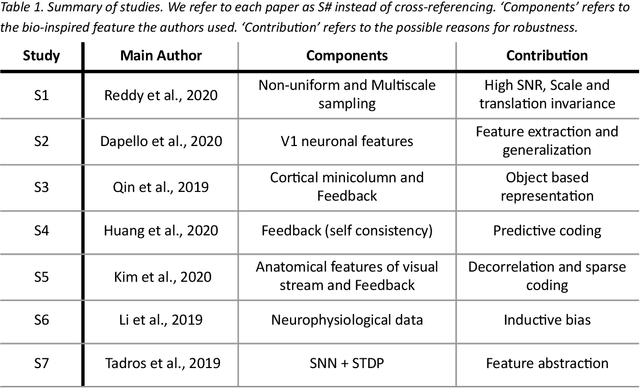
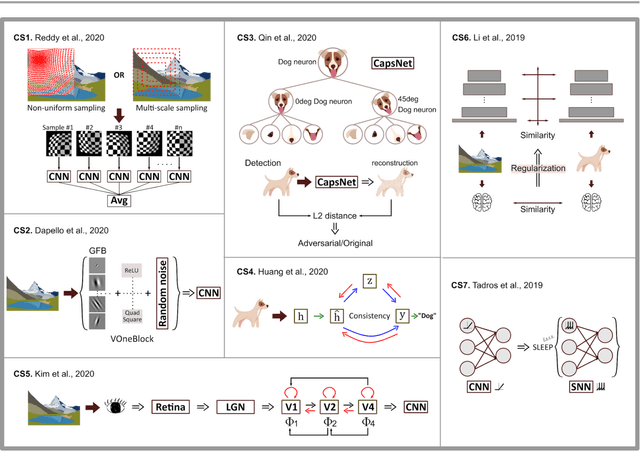
Deep convolutional neural networks (DCNNs) have revolutionized computer vision and are often advocated as good models of the human visual system. However, there are currently many shortcomings of DCNNs, which preclude them as a model of human vision. For example, in the case of adversarial attacks, where adding small amounts of noise to an image, including an object, can lead to strong misclassification of that object. But for humans, the noise is often invisible. If vulnerability to adversarial noise cannot be fixed, DCNNs cannot be taken as serious models of human vision. Many studies have tried to add features of the human visual system to DCNNs to make them robust against adversarial attacks. However, it is not fully clear whether human vision inspired components increase robustness because performance evaluations of these novel components in DCNNs are often inconclusive. We propose a set of criteria for proper evaluation and analyze different models according to these criteria. We finally sketch future efforts to make DCCNs one step closer to the model of human vision.