 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAD: A Contrastive Learning based Approach for Background Debiasing
Oct 06, 2022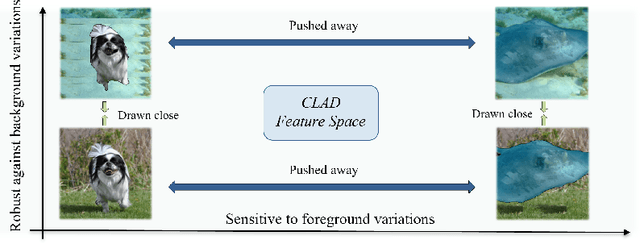


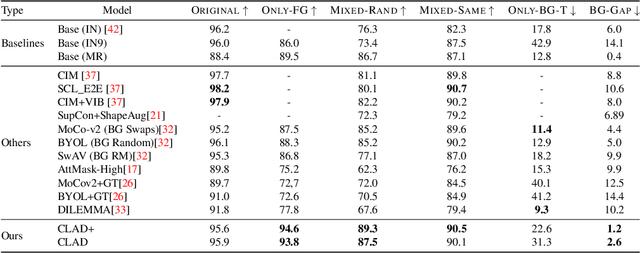
Convolutional neural networks (CNNs) have achieved superhuman performance in multiple vision tasks, especially image classification. However, unlike humans, CNNs leverage spurious features, such as background information to make decisions. This tendency creates different problems in terms of robustness or weak generalization performance. Through our work, we introduce a contrastive learning-based approach (CLAD) to mitigate the background bias in CNNs. CLAD encourages semantic focus on object foregrounds and penalizes learning features from irrelavant backgrounds. Our method also introduces an efficient way of sampling negative samples. We achieve state-of-the-art results on the Background Challenge dataset, outperforming the previous benchmark with a margin of 4.1\%. Our paper shows how CLAD serves as a proof of concept for debiasing of spurious features, such as background and texture (in supplementary material).
Empirical Advocacy of Bio-inspired Models for Robust Image Recognition
May 18, 2022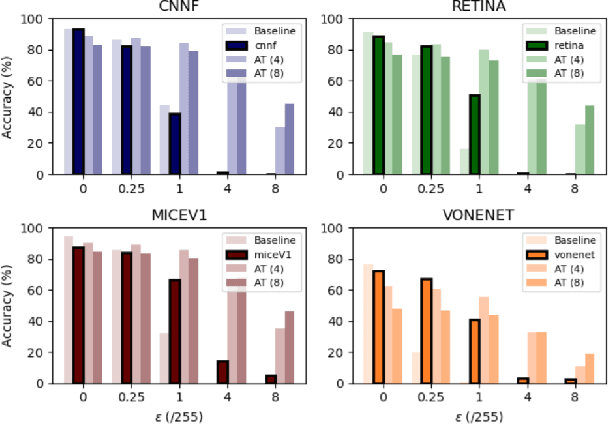
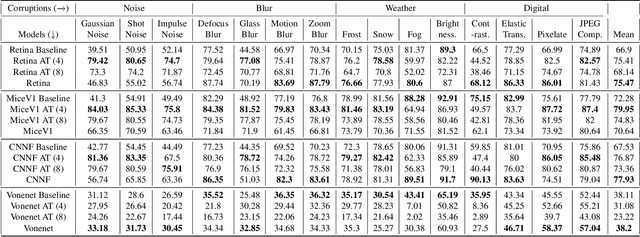
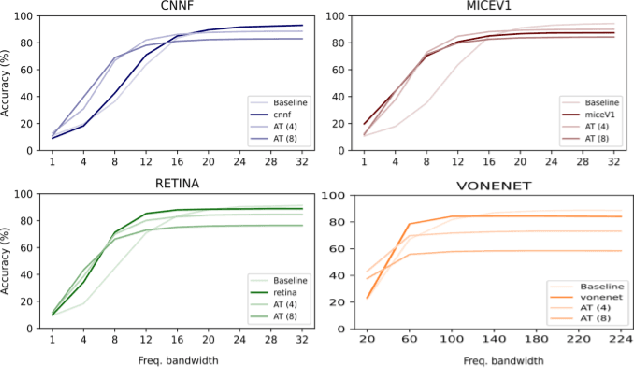
Deep convolutional neural networks (DCNNs) have revolutionized computer vision and are often advocated as good models of the human visual system. However, there are currently many shortcomings of DCNNs, which preclude them as a model of human vision. There are continuous attempts to use features of the human visual system to improve the robustness of neural networks to data perturbations. We provide a detailed analysis of such bio-inspired models and their properties. To this end, we benchmark the robustness of several bio-inspired models against their most comparable baseline DCNN models. We find that bio-inspired models tend to be adversarially robust without requiring any special data augmentation. Additionally, we find that bio-inspired models beat adversarially trained models in the presence of more real-world common corruptions. Interestingly, we also find that bio-inspired models tend to use both low and mid-frequency information, in contrast to other DCNN models. We find that this mix of frequency information makes them robust to both adversarial perturbations and common corruptions.
Bio-inspired Robustness: A Review
Mar 16, 2021
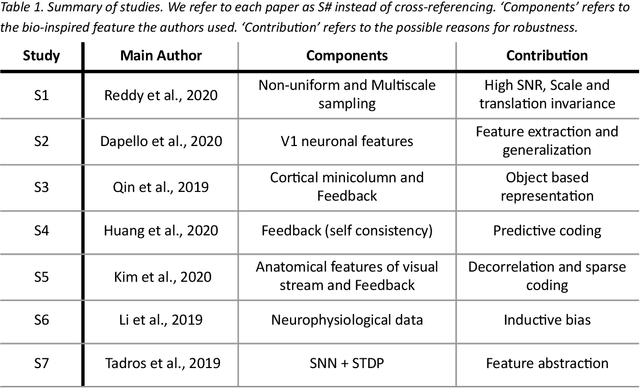
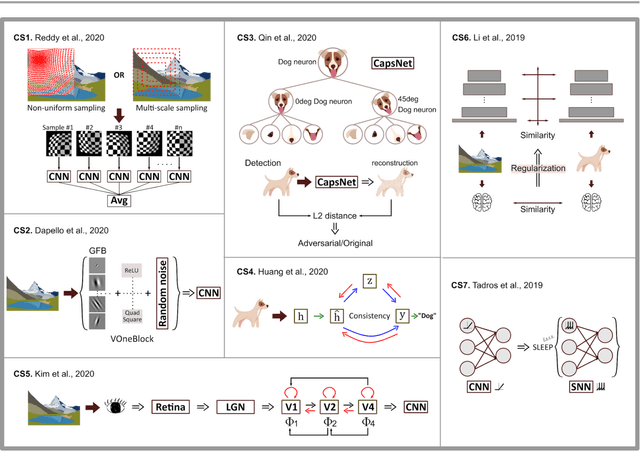
Deep convolutional neural networks (DCNNs) have revolutionized computer vision and are often advocated as good models of the human visual system. However, there are currently many shortcomings of DCNNs, which preclude them as a model of human vision. For example, in the case of adversarial attacks, where adding small amounts of noise to an image, including an object, can lead to strong misclassification of that object. But for humans, the noise is often invisible. If vulnerability to adversarial noise cannot be fixed, DCNNs cannot be taken as serious models of human vision. Many studies have tried to add features of the human visual system to DCNNs to make them robust against adversarial attacks. However, it is not fully clear whether human vision inspired components increase robustness because performance evaluations of these novel components in DCNNs are often inconclusive. We propose a set of criteria for proper evaluation and analyze different models according to these criteria. We finally sketch future efforts to make DCCNs one step closer to the model of human vision.