 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContour Integration Underlies Human-Like Vision
Apr 07, 2025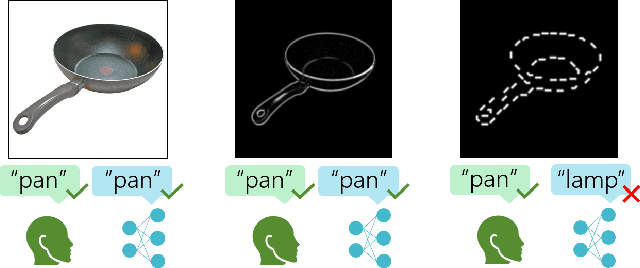
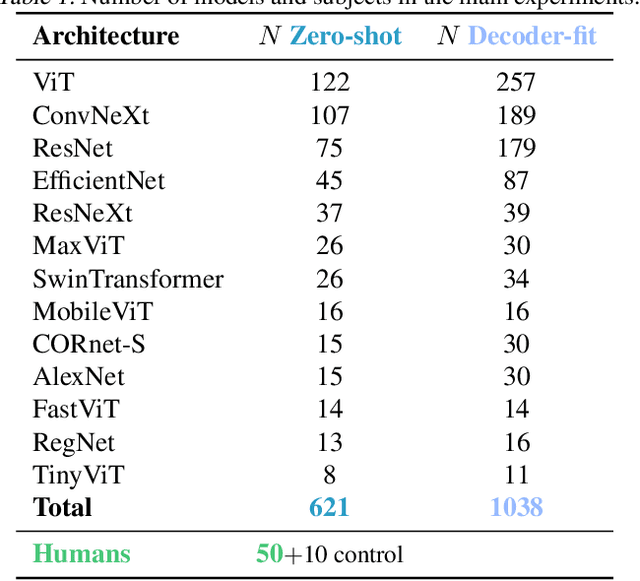

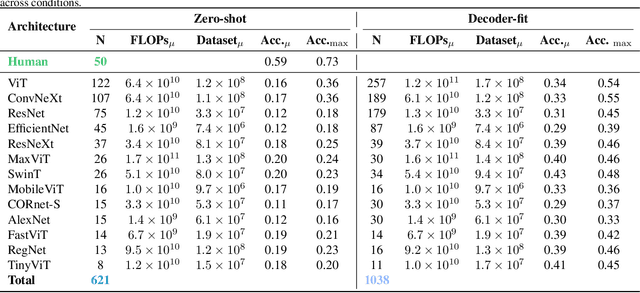
Despite the tremendous success of deep learning in computer vision, models still fall behind humans in generalizing to new input distributions. Existing benchmarks do not investigate the specific failure points of models by analyzing performance under many controlled conditions. Our study systematically dissects where and why models struggle with contour integration -- a hallmark of human vision -- by designing an experiment that tests object recognition under various levels of object fragmentation. Humans (n=50) perform at high accuracy, even with few object contours present. This is in contrast to models which exhibit substantially lower sensitivity to increasing object contours, with most of the over 1,000 models we tested barely performing above chance. Only at very large scales ($\sim5B$ training dataset size) do models begin to approach human performance. Importantly, humans exhibit an integration bias -- a preference towards recognizing objects made up of directional fragments over directionless fragments. We find that not only do models that share this property perform better at our task, but that this bias also increases with model training dataset size, and training models to exhibit contour integration leads to high shape bias. Taken together, our results suggest that contour integration is a hallmark of object vision that underlies object recognition performance, and may be a mechanism learned from data at scale.
Latent Noise Segmentation: How Neural Noise Leads to the Emergence of Segmentation and Grouping
Sep 28, 2023



Deep Neural Networks (DNNs) that achieve human-level performance in general tasks like object segmentation typically require supervised labels. In contrast, humans are able to perform these tasks effortlessly without supervision. To accomplish this, the human visual system makes use of perceptual grouping. Understanding how perceptual grouping arises in an unsupervised manner is critical for improving both models of the visual system, and computer vision models. In this work, we propose a counterintuitive approach to unsupervised perceptual grouping and segmentation: that they arise because of neural noise, rather than in spite of it. We (1) mathematically demonstrate that under realistic assumptions, neural noise can be used to separate objects from each other, and (2) show that adding noise in a DNN enables the network to segment images even though it was never trained on any segmentation labels. Interestingly, we find that (3) segmenting objects using noise results in segmentation performance that aligns with the perceptual grouping phenomena observed in humans. We introduce the Good Gestalt (GG) datasets -- six datasets designed to specifically test perceptual grouping, and show that our DNN models reproduce many important phenomena in human perception, such as illusory contours, closure, continuity, proximity, and occlusion. Finally, we (4) demonstrate the ecological plausibility of the method by analyzing the sensitivity of the DNN to different magnitudes of noise. We find that some model variants consistently succeed with remarkably low levels of neural noise ($\sigma<0.001$), and surprisingly, that segmenting this way requires as few as a handful of samples. Together, our results suggest a novel unsupervised segmentation method requiring few assumptions, a new explanation for the formation of perceptual grouping, and a potential benefit of neural noise in the visual system.
A comment on Guo et al. [arXiv:2206.11228]
Aug 02, 2022In a recent article, Guo et al. [arXiv:2206.11228] report that adversarially trained neural representations in deep networks may already be as robust as corresponding primate IT neural representations. While we find the paper's primary experiment illuminating, we have doubts about the interpretation and phrasing of the results presented in the paper.
Object Recognition in Deep Convolutional Neural Networks is Fundamentally Different to That in Humans
Mar 01, 2019

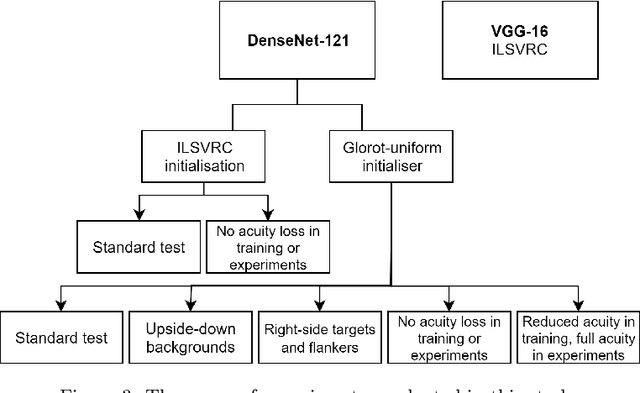
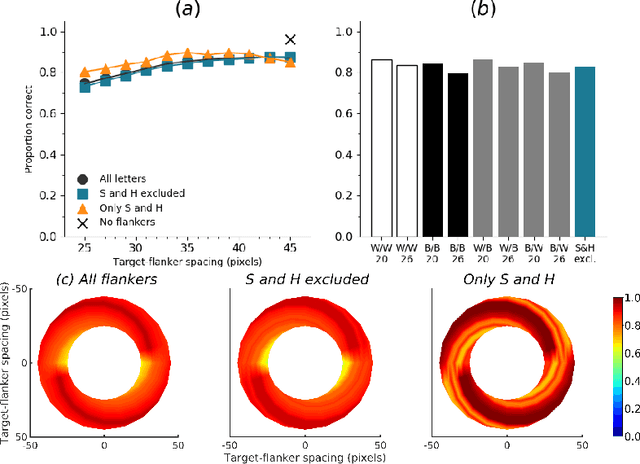
Object recognition is a primary function of the human visual system. It has recently been claimed that the highly successful ability to recognise objects in a set of emergent computer vision systems---Deep Convolutional Neural Networks (DCNNs)---can form a useful guide to recognition in humans. To test this assertion, we systematically evaluated visual crowding, a dramatic breakdown of recognition in clutter, in DCNNs and compared their performance to extant research in humans. We examined crowding in two architectures of DCNNs with the same methodology as that used among humans. We manipulated multiple stimulus factors including inter-letter spacing, letter colour, size, and flanker location to assess the extent and shape of crowding in DCNNs to establish a clear picture of crowding in DCNNs. We found that crowding followed a predictable pattern across DCNN architectures that was fundamentally different from that in humans. Some characteristic hallmarks of human crowding, such as invariance to size, the effect of target-flanker similarity, and confusions between target and flanker identities, were completely missing, minimised or even reversed in DCNNs. These data show that DCNNs, while proficient in object recognition, likely achieve this competence through a set of mechanisms that are distinct from those in humans. They are not equivalent models of human or primate object recognition and caution must be exercised when inferring mechanisms derived from their operation.