 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Recognition in Deep Convolutional Neural Networks is Fundamentally Different to That in Humans
Mar 01, 2019

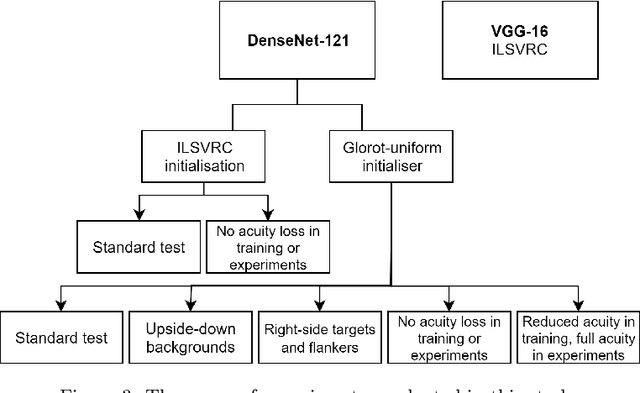
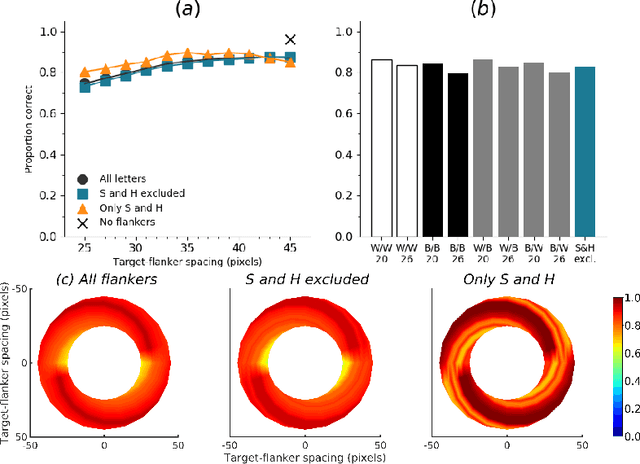
Object recognition is a primary function of the human visual system. It has recently been claimed that the highly successful ability to recognise objects in a set of emergent computer vision systems---Deep Convolutional Neural Networks (DCNNs)---can form a useful guide to recognition in humans. To test this assertion, we systematically evaluated visual crowding, a dramatic breakdown of recognition in clutter, in DCNNs and compared their performance to extant research in humans. We examined crowding in two architectures of DCNNs with the same methodology as that used among humans. We manipulated multiple stimulus factors including inter-letter spacing, letter colour, size, and flanker location to assess the extent and shape of crowding in DCNNs to establish a clear picture of crowding in DCNNs. We found that crowding followed a predictable pattern across DCNN architectures that was fundamentally different from that in humans. Some characteristic hallmarks of human crowding, such as invariance to size, the effect of target-flanker similarity, and confusions between target and flanker identities, were completely missing, minimised or even reversed in DCNNs. These data show that DCNNs, while proficient in object recognition, likely achieve this competence through a set of mechanisms that are distinct from those in humans. They are not equivalent models of human or primate object recognition and caution must be exercised when inferring mechanisms derived from their operation.