 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContour Integration Underlies Human-Like Vision
Apr 07, 2025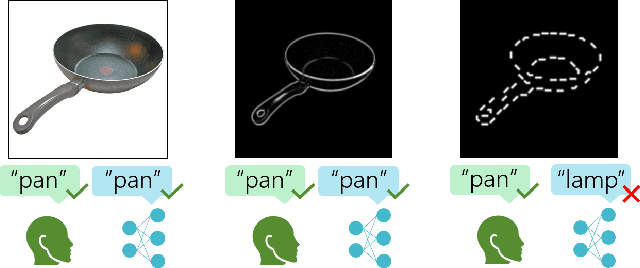
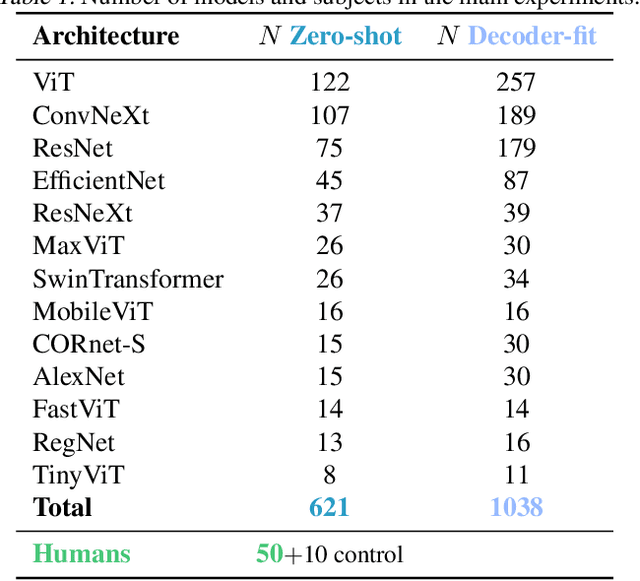

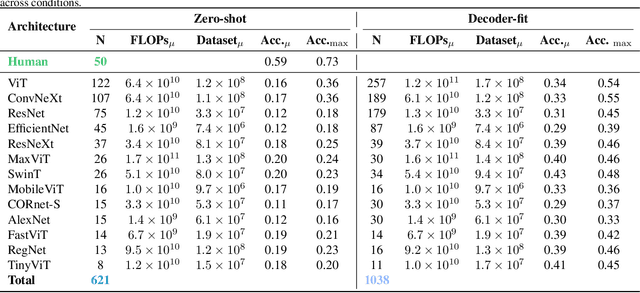
Despite the tremendous success of deep learning in computer vision, models still fall behind humans in generalizing to new input distributions. Existing benchmarks do not investigate the specific failure points of models by analyzing performance under many controlled conditions. Our study systematically dissects where and why models struggle with contour integration -- a hallmark of human vision -- by designing an experiment that tests object recognition under various levels of object fragmentation. Humans (n=50) perform at high accuracy, even with few object contours present. This is in contrast to models which exhibit substantially lower sensitivity to increasing object contours, with most of the over 1,000 models we tested barely performing above chance. Only at very large scales ($\sim5B$ training dataset size) do models begin to approach human performance. Importantly, humans exhibit an integration bias -- a preference towards recognizing objects made up of directional fragments over directionless fragments. We find that not only do models that share this property perform better at our task, but that this bias also increases with model training dataset size, and training models to exhibit contour integration leads to high shape bias. Taken together, our results suggest that contour integration is a hallmark of object vision that underlies object recognition performance, and may be a mechanism learned from data at scale.