 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining error accumulation in ML atmospheric simulators
May 23, 2024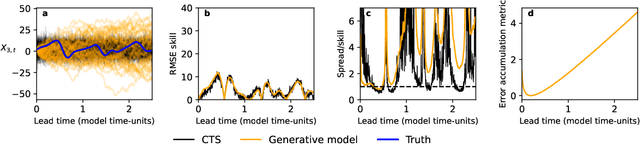
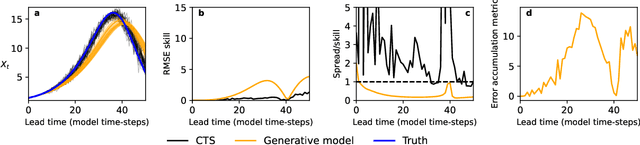
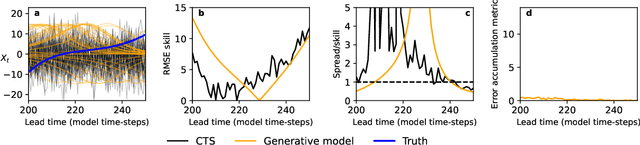
Machine learning (ML) has recently shown significant promise in modelling atmospheric systems, such as the weather. Many of these ML models are autoregressive, and error accumulation in their forecasts is a key problem. However, there is no clear definition of what `error accumulation' actually entails. In this paper, we propose a definition and an associated metric to measure it. Our definition distinguishes between errors which are due to model deficiencies, which we may hope to fix, and those due to the intrinsic properties of atmospheric systems (chaos, unobserved variables), which are not fixable. We illustrate the usefulness of this definition by proposing a simple regularization loss penalty inspired by it. This approach shows performance improvements (according to RMSE and spread/skill) in a selection of atmospheric systems, including the real-world weather prediction task.
Aardvark Weather: end-to-end data-driven weather forecasting
Mar 30, 2024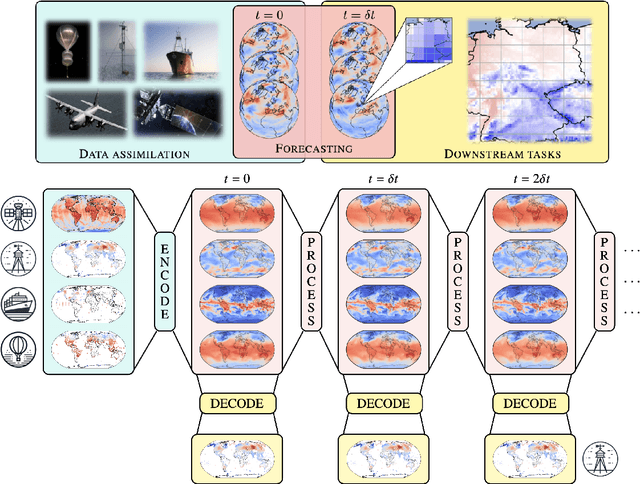
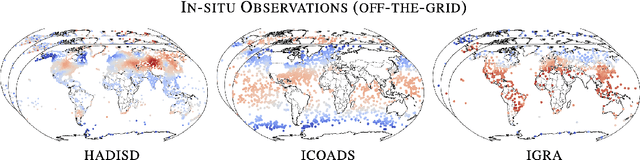
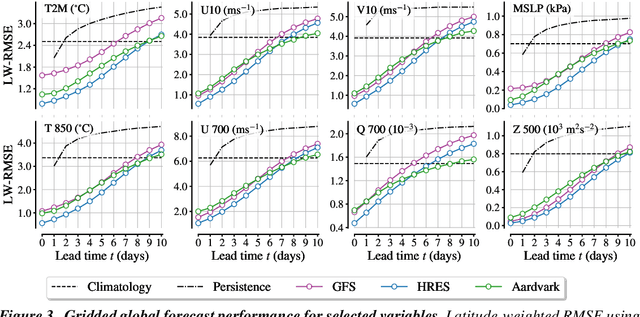
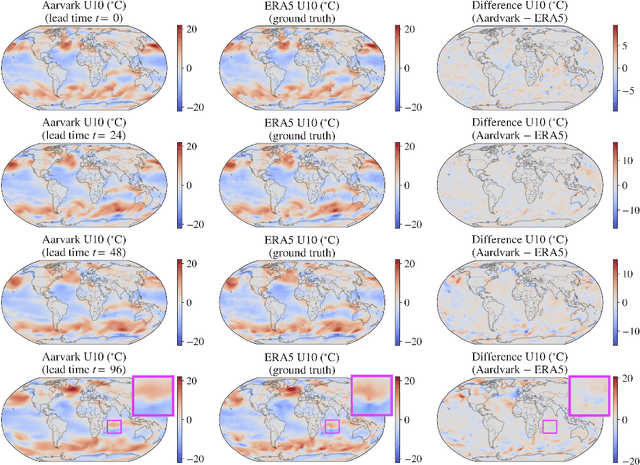
Machine learning is revolutionising medium-range weather prediction. However it has only been applied to specific and individual components of the weather prediction pipeline. Consequently these data-driven approaches are unable to be deployed without input from conventional operational numerical weather prediction (NWP) systems, which is computationally costly and does not support end-to-end optimisation. In this work, we take a radically different approach and replace the entire NWP pipeline with a machine learning model. We present Aardvark Weather, the first end-to-end data-driven forecasting system which takes raw observations as input and provides both global and local forecasts. These global forecasts are produced for 24 variables at multiple pressure levels at one-degree spatial resolution and 24 hour temporal resolution, and are skillful with respect to hourly climatology at five to seven day lead times. Local forecasts are produced for temperature, mean sea level pressure, and wind speed at a geographically diverse set of weather stations, and are skillful with respect to an IFS-HRES interpolation baseline at multiple lead-times. Aardvark, by virtue of its simplicity and scalability, opens the door to a new paradigm for performing accurate and efficient data-driven medium-range weather forecasting.
Sea ice detection using concurrent multispectral and synthetic aperture radar imagery
Jan 11, 2024Synthetic Aperture Radar (SAR) imagery is the primary data type used for sea ice mapping due to its spatio-temporal coverage and the ability to detect sea ice independent of cloud and lighting conditions. Automatic sea ice detection using SAR imagery remains problematic due to the presence of ambiguous signal and noise within the image. Conversely, ice and water are easily distinguishable using multispectral imagery (MSI), but in the polar regions the ocean's surface is often occluded by cloud or the sun may not appear above the horizon for many months. To address some of these limitations, this paper proposes a new tool trained using concurrent multispectral Visible and SAR imagery for sea Ice Detection (ViSual\_IceD). ViSual\_IceD is a convolution neural network (CNN) that builds on the classic U-Net architecture by containing two parallel encoder stages, enabling the fusion and concatenation of MSI and SAR imagery containing different spatial resolutions. The performance of ViSual\_IceD is compared with U-Net models trained using concatenated MSI and SAR imagery as well as models trained exclusively on MSI or SAR imagery. ViSual\_IceD outperforms the other networks, with a F1 score 1.60\% points higher than the next best network, and results indicate that ViSual\_IceD is selective in the image type it uses during image segmentation. Outputs from ViSual\_IceD are compared to sea ice concentration products derived from the AMSR2 Passive Microwave (PMW) sensor. Results highlight how ViSual\_IceD is a useful tool to use in conjunction with PMW data, particularly in coastal regions. As the spatial-temporal coverage of MSI and SAR imagery continues to increase, ViSual\_IceD provides a new opportunity for robust, accurate sea ice coverage detection in polar regions.
Autoregressive Conditional Neural Processes
Mar 25, 2023

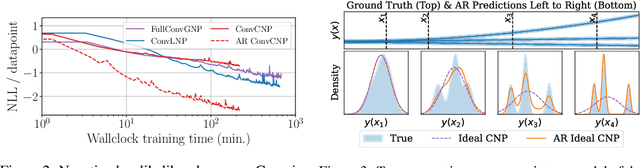
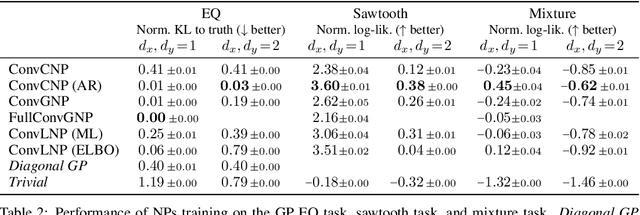
Conditional neural processes (CNPs; Garnelo et al., 2018a) are attractive meta-learning models which produce well-calibrated predictions and are trainable via a simple maximum likelihood procedure. Although CNPs have many advantages, they are unable to model dependencies in their predictions. Various works propose solutions to this, but these come at the cost of either requiring approximate inference or being limited to Gaussian predictions. In this work, we instead propose to change how CNPs are deployed at test time, without any modifications to the model or training procedure. Instead of making predictions independently for every target point, we autoregressively define a joint predictive distribution using the chain rule of probability, taking inspiration from the neural autoregressive density estimator (NADE) literature. We show that this simple procedure allows factorised Gaussian CNPs to model highly dependent, non-Gaussian predictive distributions. Perhaps surprisingly, in an extensive range of tasks with synthetic and real data, we show that CNPs in autoregressive (AR) mode not only significantly outperform non-AR CNPs, but are also competitive with more sophisticated models that are significantly more computationally expensive and challenging to train. This performance is remarkable given that AR CNPs are not trained to model joint dependencies. Our work provides an example of how ideas from neural distribution estimation can benefit neural processes, and motivates research into the AR deployment of other neural process models.
Active Learning with Convolutional Gaussian Neural Processes for Environmental Sensor Placement
Nov 22, 2022Deploying environmental measurement stations can be a costly and time-consuming procedure, especially in remote regions that are difficult to access, such as Antarctica. Therefore, it is crucial that sensors are placed as efficiently as possible, maximising the informativeness of their measurements. This can be tackled by fitting a probabilistic model to existing data and identifying placements that would maximally reduce the model's uncertainty. The models most widely used for this purpose are Gaussian processes (GPs). However, designing a GP covariance which captures the complex behaviour of non-stationary spatiotemporal data is a difficult task. Further, the computational cost of GPs makes them challenging to scale to large environmental datasets. In this work, we explore using a convolutional Gaussian neural process (ConvGNP) to address these issues. A ConvGNP is a meta-learning model that uses neural networks to parameterise a GP predictive. Our model is data-driven, flexible, efficient, and permits multiple input predictors of gridded or scattered modalities. Using simulated surface air temperature fields over Antarctica as ground truth, we show that a ConvGNP significantly outperforms a non-stationary GP baseline in terms of predictive performance. We then use the ConvGNP in an Antarctic sensor placement toy experiment, yielding promising results.
Ice Core Dating using Probabilistic Programming
Oct 29, 2022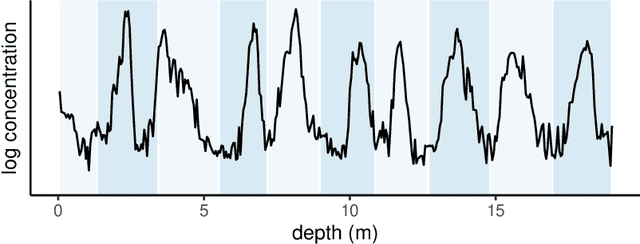
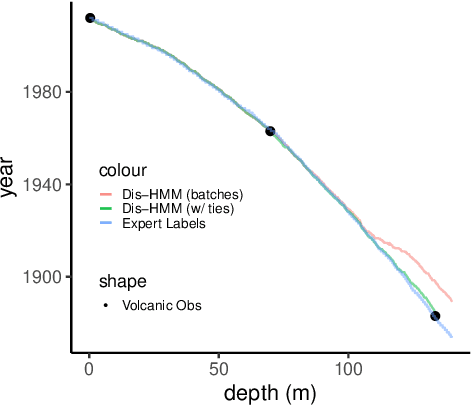
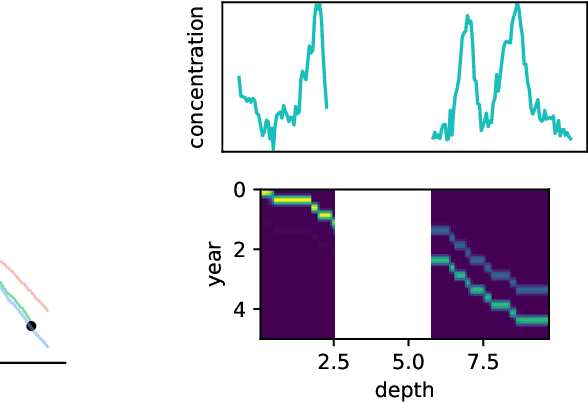
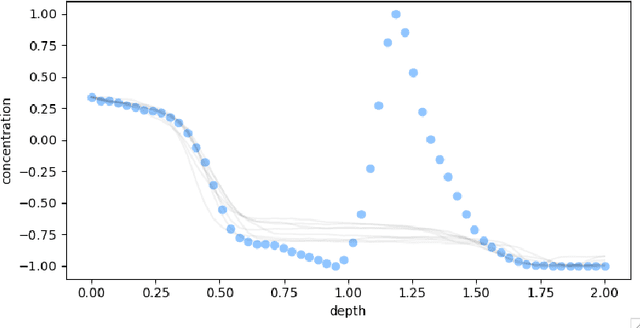
Ice cores record crucial information about past climate. However, before ice core data can have scientific value, the chronology must be inferred by estimating the age as a function of depth. Under certain conditions, chemicals locked in the ice display quasi-periodic cycles that delineate annual layers. Manually counting these noisy seasonal patterns to infer the chronology can be an imperfect and time-consuming process, and does not capture uncertainty in a principled fashion. In addition, several ice cores may be collected from a region, introducing an aspect of spatial correlation between them. We present an exploration of the use of probabilistic models for automatic dating of ice cores, using probabilistic programming to showcase its use for prototyping, automatic inference and maintainability, and demonstrate common failure modes of these tools.
Stochastic Parameterizations: Better Modelling of Temporal Correlations using Probabilistic Machine Learning
Mar 28, 2022

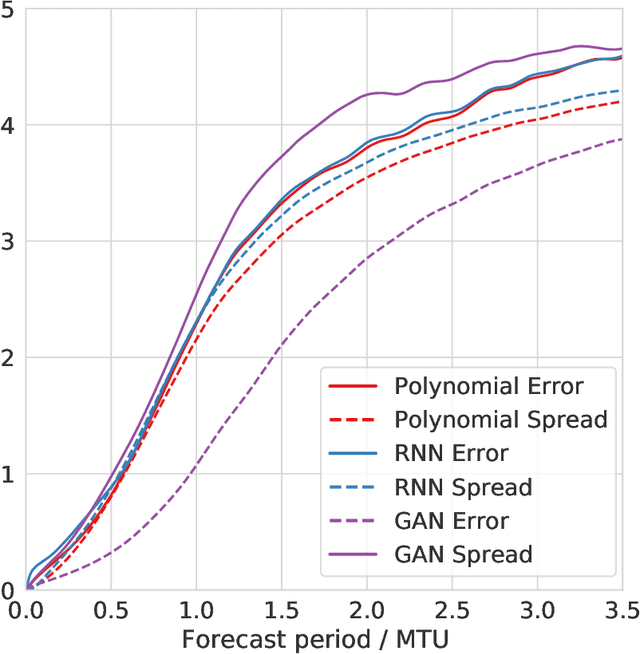
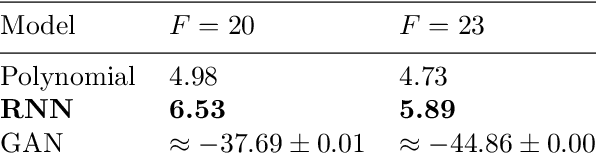
The modelling of small-scale processes is a major source of error in climate models, hindering the accuracy of low-cost models which must approximate such processes through parameterization. Using stochasticity and machine learning have led to better models but there is a lack of work on combining the benefits from both. We show that by using a physically-informed recurrent neural network within a probabilistic framework, our resulting model for the Lorenz 96 atmospheric simulation is competitive and often superior to both a bespoke baseline and an existing probabilistic machine-learning (GAN) one. This is due to a superior ability to model temporal correlations compared to standard first-order autoregressive schemes. The model also generalises to unseen regimes. We evaluate across a number of metrics from the literature, but also discuss how the probabilistic metric of likelihood may be a unifying choice for future probabilistic climate models.
Convolutional conditional neural processes for local climate downscaling
Jan 20, 2021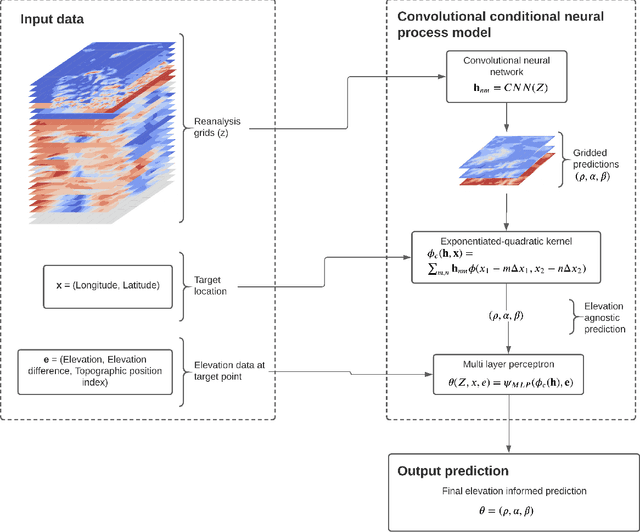
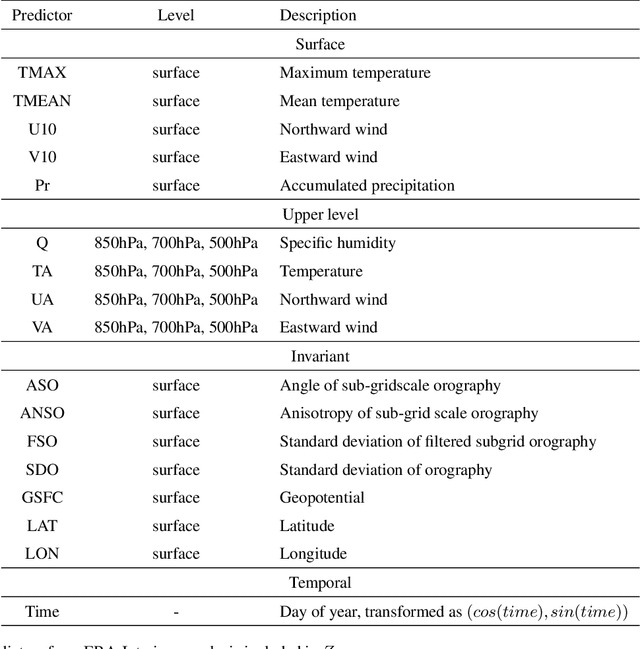
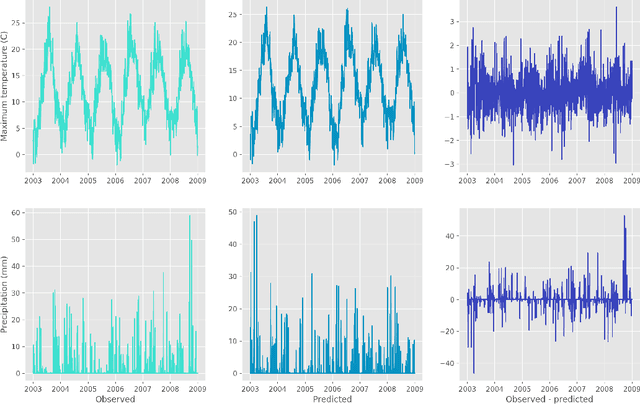
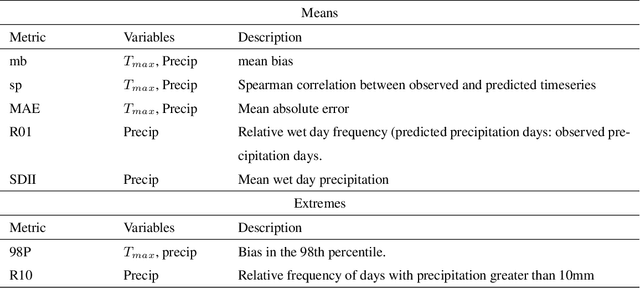
A new model is presented for multisite statistical downscaling of temperature and precipitation using convolutional conditional neural processes (convCNPs). ConvCNPs are a recently developed class of models that allow deep learning techniques to be applied to off-the-grid spatio-temporal data. This model has a substantial advantage over existing downscaling methods in that the trained model can be used to generate multisite predictions at an arbitrary set of locations, regardless of the availability of training data. The convCNP model is shown to outperform an ensemble of existing downscaling techniques over Europe for both temperature and precipitation taken from the VALUE intercomparison project. The model also outperforms an approach that uses Gaussian processes to interpolate single-site downscaling models at unseen locations. Importantly, substantial improvement is seen in the representation of extreme precipitation events. These results indicate that the convCNP is a robust downscaling model suitable for generating localised projections for use in climate impact studies, and motivates further research into applications of deep learning techniques in statistical downscaling.
Ensembling geophysical models with Bayesian Neural Networks
Oct 07, 2020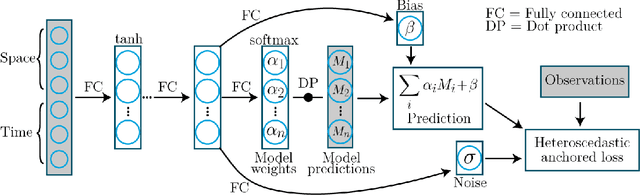
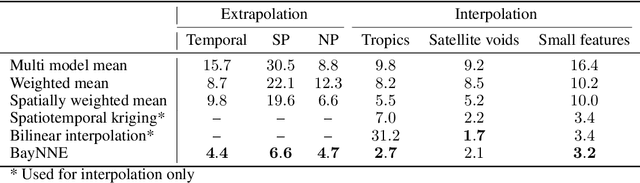
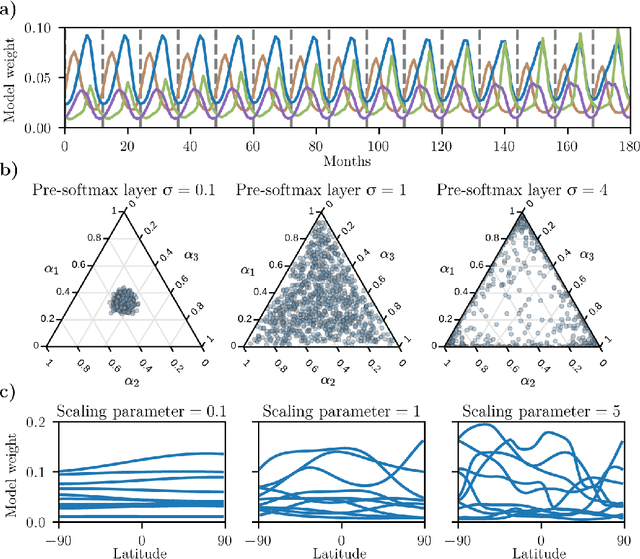
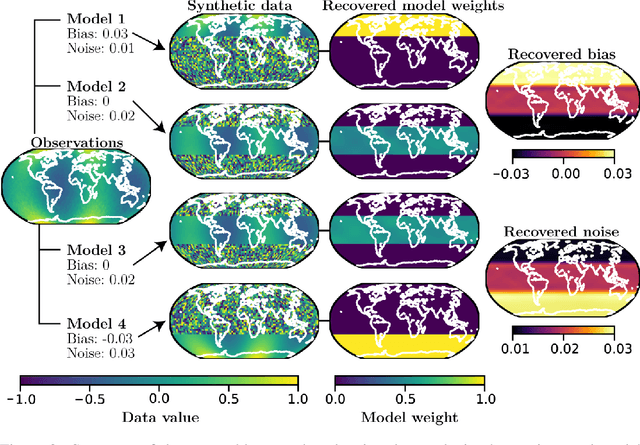
Ensembles of geophysical models improve projection accuracy and express uncertainties. We develop a novel data-driven ensembling strategy for combining geophysical models using Bayesian Neural Networks, which infers spatiotemporally varying model weights and bias while accounting for heteroscedastic uncertainties in the observations. This produces more accurate and uncertainty-aware projections without sacrificing interpretability. Applied to the prediction of total column ozone from an ensemble of 15 chemistry-climate models, we find that the Bayesian neural network ensemble (BayNNE) outperforms existing ensembling methods, achieving a 49.4% reduction in RMSE for temporal extrapolation, and a 67.4% reduction in RMSE for polar data voids, compared to a weighted mean. Uncertainty is also well-characterized, with 90.6% of the data points in our extrapolation validation dataset lying within 2 standard deviations and 98.5% within 3 standard deviations.
Scalable Exact Inference in Multi-Output Gaussian Processes
Nov 14, 2019
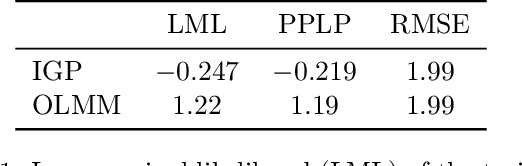
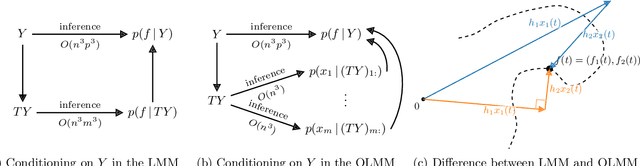
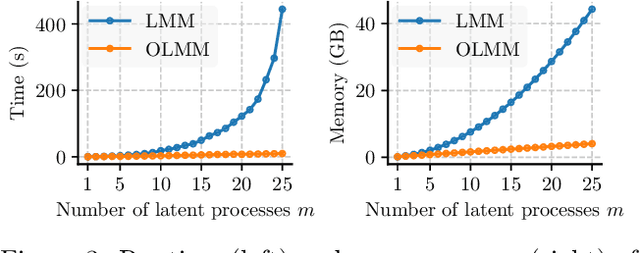
Multi-output Gaussian processes (MOGPs) leverage the flexibility and interpretability of GPs while capturing structure across outputs, which is desirable, for example, in spatio-temporal modelling. The key problem with MOGPs is the cubic computational scaling in the number of both inputs (e.g., time points or locations), n, and outputs, p. Current methods reduce this to O(n^3 m^3), where m < p is the desired degrees of freedom. This computational cost, however, is still prohibitive in many applications. To address this limitation, we present the Orthogonal Linear Mixing Model (OLMM), an MOGP in which exact inference scales linearly in m: O(n^3 m). This advance opens up a wide range of real-world tasks and can be combined with existing GP approximations in a plug-and-play way as demonstrated in the paper. Additionally, the paper organises the existing disparate literature on MOGP models into a simple taxonomy called the Mixing Model Hierarchy (MMH).