 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining error accumulation in ML atmospheric simulators
Paper and Code
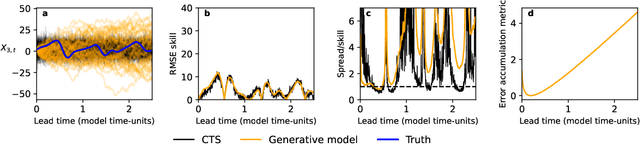
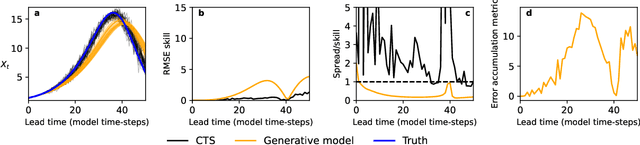
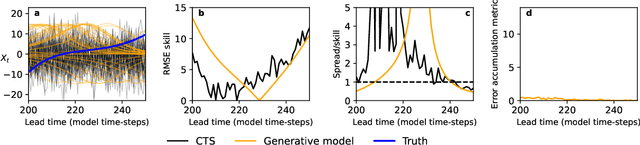
Machine learning (ML) has recently shown significant promise in modelling atmospheric systems, such as the weather. Many of these ML models are autoregressive, and error accumulation in their forecasts is a key problem. However, there is no clear definition of what `error accumulation' actually entails. In this paper, we propose a definition and an associated metric to measure it. Our definition distinguishes between errors which are due to model deficiencies, which we may hope to fix, and those due to the intrinsic properties of atmospheric systems (chaos, unobserved variables), which are not fixable. We illustrate the usefulness of this definition by proposing a simple regularization loss penalty inspired by it. This approach shows performance improvements (according to RMSE and spread/skill) in a selection of atmospheric systems, including the real-world weather prediction task.