 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing Diverse Paraphrases for Training Task-oriented Bots
Sep 20, 2021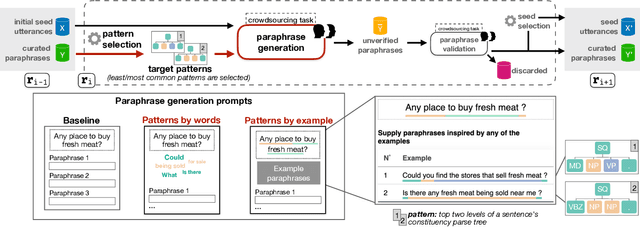
A prominent approach to build datasets for training task-oriented bots is crowd-based paraphrasing. Current approaches, however, assume the crowd would naturally provide diverse paraphrases or focus only on lexical diversity. In this WiP we addressed an overlooked aspect of diversity, introducing an approach for guiding the crowdsourcing process towards paraphrases that are syntactically diverse.
On how Cognitive Computing will plan your next Systematic Review
Dec 15, 2020Systematic literature reviews (SLRs) are at the heart of evidence-based research, setting the foundation for future research and practice. However, producing good quality timely contributions is a challenging and highly cognitive endeavor, which has lately motivated the exploration of automation and support in the SLR process. In this paper we address an often overlooked phase in this process, that of planning literature reviews, and explore under the lenses of cognitive process augmentation how to overcome its most salient challenges. In doing so, we report on the insights from 24 SLR authors on planning practices, its challenges as well as feedback on support strategies inspired by recent advances in cognitive computing. We frame our findings under the cognitive augmentation framework, and report on a prototype implementation and evaluation focusing on further informing the technical feasibility.
Bringing Cognitive Augmentation to Web Browsing Accessibility
Dec 07, 2020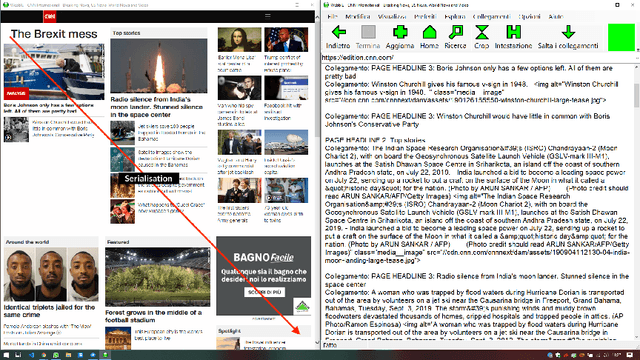
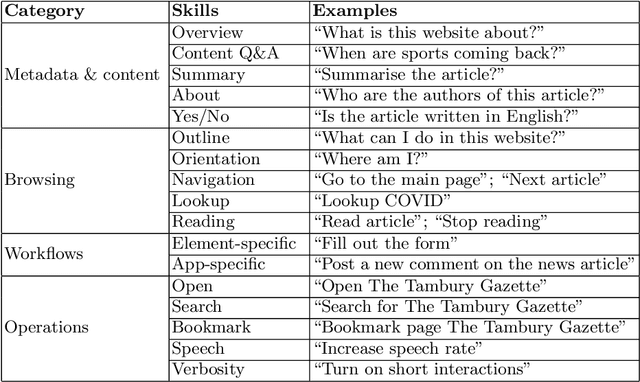
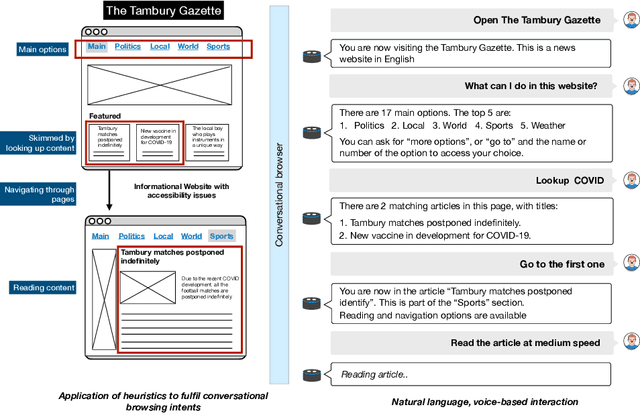
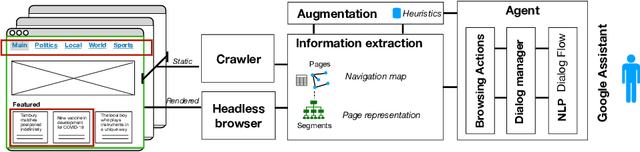
In this paper we explore the opportunities brought by cognitive augmentation to provide a more natural and accessible web browsing experience. We explore these opportunities through \textit{conversational web browsing}, an emerging interaction paradigm for the Web that enables blind and visually impaired users (BVIP), as well as regular users, to access the contents and features of websites through conversational agents. Informed by the literature, our previous work and prototyping exercises, we derive a conceptual framework for supporting BVIP conversational web browsing needs, to then focus on the challenges of automatically providing this support, describing our early work and prototype that leverage heuristics that consider structural and content features only.
Chatbots as conversational healthcare services
Nov 08, 2020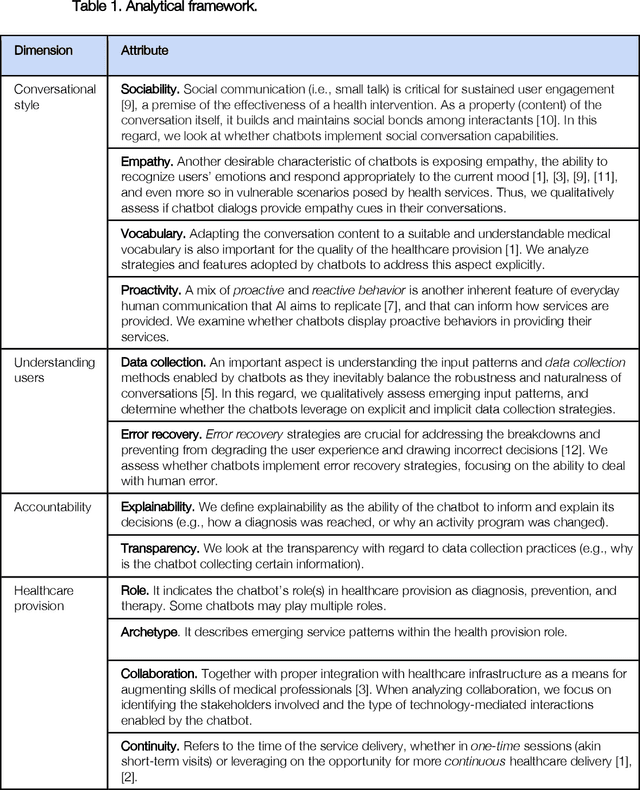
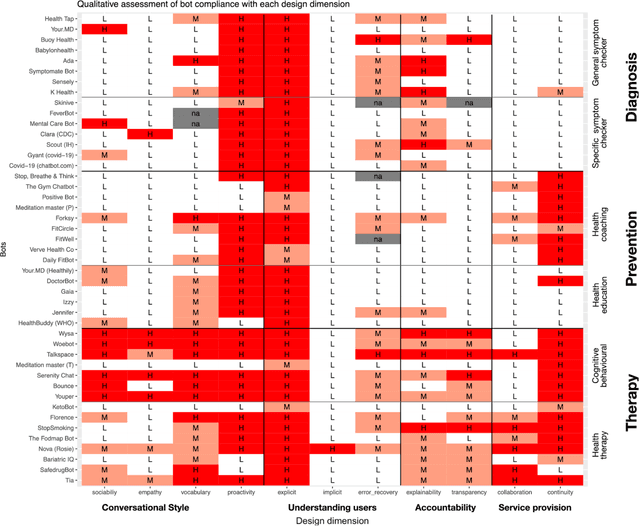
Chatbots are emerging as a promising platform for accessing and delivering healthcare services. The evidence is in the growing number of publicly available chatbots aiming at taking an active role in the provision of prevention, diagnosis, and treatment services. This article takes a closer look at how these emerging chatbots address design aspects relevant to healthcare service provision, emphasizing the Human-AI interaction aspects and the transparency in AI automation and decision making.
Automatic Generation of Chatbots for Conversational Web Browsing
Aug 19, 2020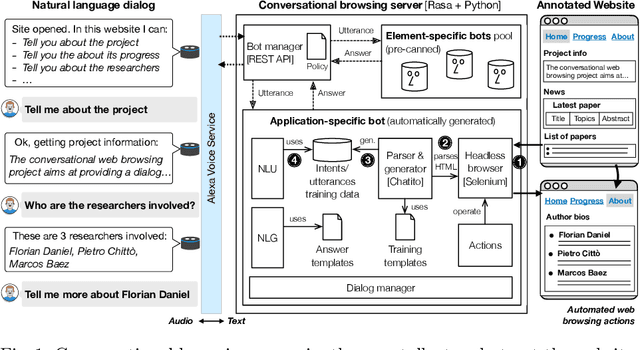
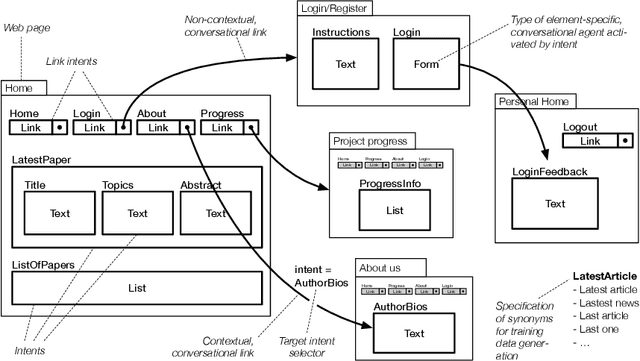

In this paper, we describe the foundations for generating a chatbot out of a website equipped with simple, bot-specific HTML annotations. The approach is part of what we call conversational web browsing, i.e., a dialog-based, natural language interaction with websites. The goal is to enable users to use content and functionality accessible through rendered UIs by "talking to websites" instead of by operating the graphical UI using keyboard and mouse. The chatbot mediates between the user and the website, operates its graphical UI on behalf of the user, and informs the user about the state of interaction. We describe the conceptual vocabulary and annotation format, the supporting conversational middleware and techniques, and the implementation of a demo able to deliver conversational web browsing experiences through Amazon Alexa.
Combining Crowd and Machines for Multi-predicate Item Screening
Apr 01, 2019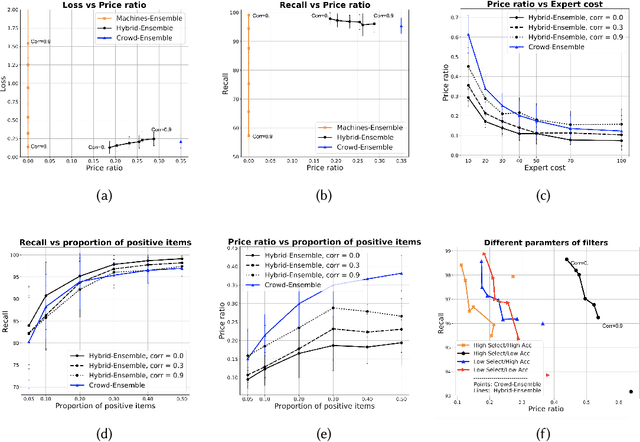

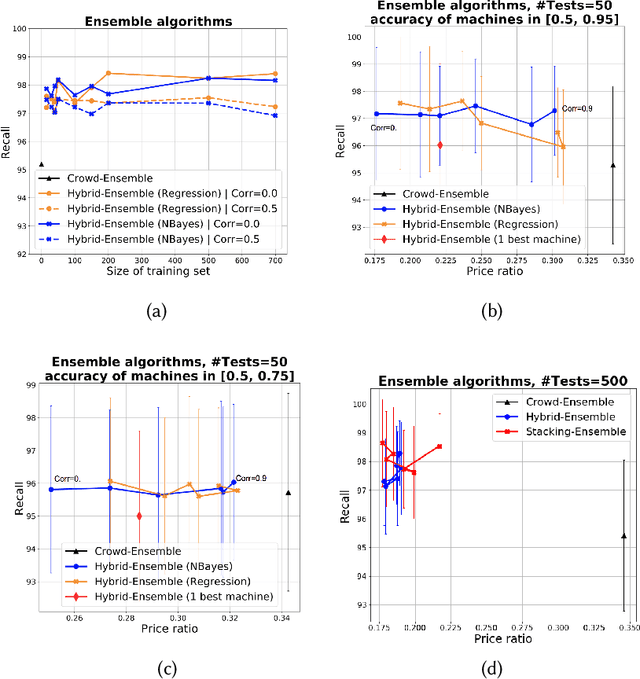
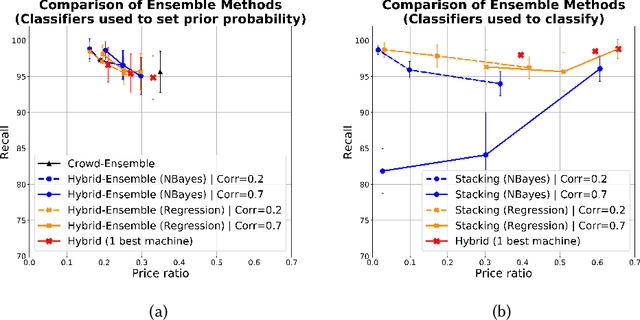
This paper discusses how crowd and machine classifiers can be efficiently combined to screen items that satisfy a set of predicates. We show that this is a recurring problem in many domains, present machine-human (hybrid) algorithms that screen items efficiently and estimate the gain over human-only or machine-only screening in terms of performance and cost. We further show how, given a new classification problem and a set of classifiers of unknown accuracy for the problem at hand, we can identify how to manage the cost-accuracy trade off by progressively determining if we should spend budget to obtain test data (to assess the accuracy of the given classifiers), or to train an ensemble of classifiers, or whether we should leverage the existing machine classifiers with the crowd, and in this case how to efficiently combine them based on their estimated characteristics to obtain the classification. We demonstrate that the techniques we propose obtain significant cost/accuracy improvements with respect to the leading classification algorithms.
Crowdsourcing for Reminiscence Chatbot Design
May 31, 2018
In this work-in-progress paper we discuss the challenges in identifying effective and scalable crowd-based strategies for designing content, conversation logic, and meaningful metrics for a reminiscence chatbot targeted at older adults. We formalize the problem and outline the main research questions that drive the research agenda in chatbot design for reminiscence and for relational agents for older adults in general.