 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimCE: Simplifying Cross-Entropy Loss for Collaborative Filtering
Jun 23, 2024



The learning objective is integral to collaborative filtering systems, where the Bayesian Personalized Ranking (BPR) loss is widely used for learning informative backbones. However, BPR often experiences slow convergence and suboptimal local optima, partially because it only considers one negative item for each positive item, neglecting the potential impacts of other unobserved items. To address this issue, the recently proposed Sampled Softmax Cross-Entropy (SSM) compares one positive sample with multiple negative samples, leading to better performance. Our comprehensive experiments confirm that recommender systems consistently benefit from multiple negative samples during training. Furthermore, we introduce a \underline{Sim}plified Sampled Softmax \underline{C}ross-\underline{E}ntropy Loss (SimCE), which simplifies the SSM using its upper bound. Our validation on 12 benchmark datasets, using both MF and LightGCN backbones, shows that SimCE significantly outperforms both BPR and SSM.
Differentially private $k$-means clustering via exponential mechanism and max cover
Sep 02, 2020
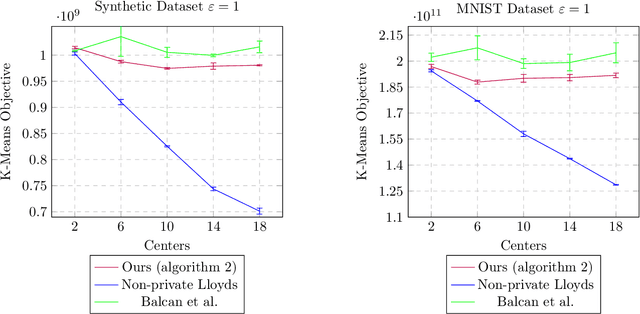
We introduce a new $(\epsilon_p, \delta_p)$-differentially private algorithm for the $k$-means clustering problem. Given a dataset in Euclidean space, the $k$-means clustering problem requires one to find $k$ points in that space such that the sum of squares of Euclidean distances between each data point and its closest respective point among the $k$ returned is minimised. Although there exist privacy-preserving methods with good theoretical guarantees to solve this problem [Balcan et al., 2017; Kaplan and Stemmer, 2018], in practice it is seen that it is the additive error which dictates the practical performance of these methods. By reducing the problem to a sequence of instances of maximum coverage on a grid, we are able to derive a new method that achieves lower additive error then previous works. For input datasets with cardinality $n$ and diameter $\Delta$, our algorithm has an $O(\Delta^2 (k \log^2 n \log(1/\delta_p)/\epsilon_p + k\sqrt{d \log(1/\delta_p)}/\epsilon_p))$ additive error whilst maintaining constant multiplicative error. We conclude with some experiments and find an improvement over previously implemented work for this problem.