 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuotient Complex Transformer (QCformer) for Perovskite Data Analysis
May 14, 2025The discovery of novel functional materials is crucial in addressing the challenges of sustainable energy generation and climate change. Hybrid organic-inorganic perovskites (HOIPs) have gained attention for their exceptional optoelectronic properties in photovoltaics. Recently, geometric deep learning, particularly graph neural networks (GNNs), has shown strong potential in predicting material properties and guiding material design. However, traditional GNNs often struggle to capture the periodic structures and higher-order interactions prevalent in such systems. To address these limitations, we propose a novel representation based on quotient complexes (QCs) and introduce the Quotient Complex Transformer (QCformer) for material property prediction. A material structure is modeled as a quotient complex, which encodes both pairwise and many-body interactions via simplices of varying dimensions and captures material periodicity through a quotient operation. Our model leverages higher-order features defined on simplices and processes them using a simplex-based Transformer module. We pretrain QCformer on benchmark datasets such as the Materials Project and JARVIS, and fine-tune it on HOIP datasets. The results show that QCformer outperforms state-of-the-art models in HOIP property prediction, demonstrating its effectiveness. The quotient complex representation and QCformer model together contribute a powerful new tool for predictive modeling of perovskite materials.
Hierarchical Reinforcement Learning Empowered Task Offloading in V2I Networks
May 18, 2024



Edge computing plays an essential role in the vehicle-to-infrastructure (V2I) networks, where vehicles offload their intensive computation tasks to the road-side units for saving energy and reduce the latency. This paper designs the optimal task offloading policy to address the concerns involving processing delay, energy consumption and edge computing cost. Each computation task consisting of some interdependent sub-tasks is characterized as a directed acyclic graph (DAG). In such dynamic networks, a novel hierarchical Offloading scheme is proposed by leveraging deep reinforcement learning (DRL). The inter-dependencies among the DAGs of the computation tasks are extracted using a graph neural network with attention mechanism. A parameterized DRL algorithm is developed to deal with the hierarchical action space containing both discrete and continuous actions. Simulation results with a real-world car speed dataset demonstrate that the proposed scheme can effectively reduce the system overhead.
Toward Packet Routing with Fully-distributed Multi-agent Deep Reinforcement Learning
May 09, 2019
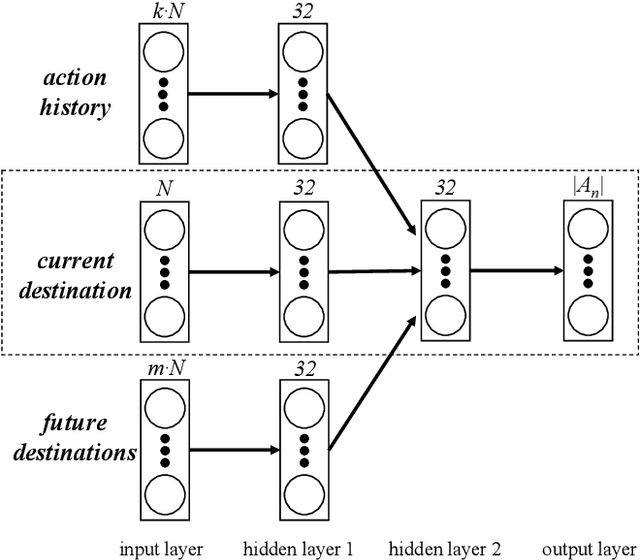
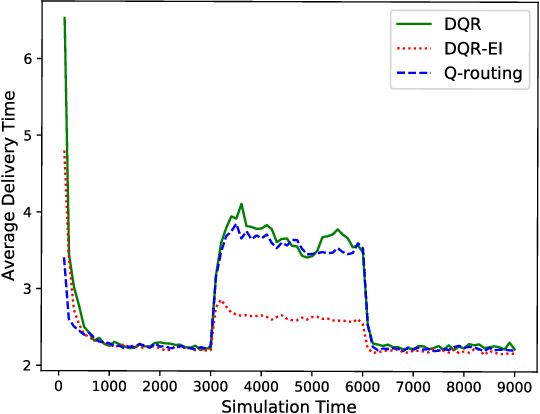
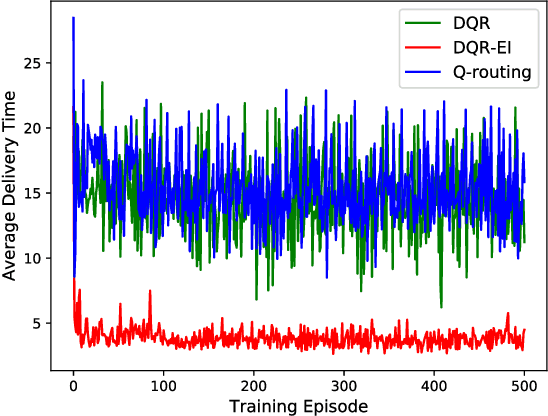
Packet routing is one of the fundamental problems in computer networks in which a router determines the next-hop of each packet in the queue to get it as quickly as possible to its destination. Reinforcement learning has been introduced to design the autonomous packet routing policy namely Q-routing only using local information available to each router. However, the curse of dimensionality of Q-routing prohibits the more comprehensive representation of dynamic network states, thus limiting the potential benefit of reinforcement learning. Inspired by recent success of deep reinforcement learning (DRL), we embed deep neural networks in multi-agent Q-routing. Each router possesses an independent neural network that is trained without communicating with its neighbors and makes decision locally. Two multi-agent DRL-enabled routing algorithms are proposed: one simply replaces Q-table of vanilla Q-routing by a deep neural network, and the other further employs extra information including the past actions and the destinations of non-head of line packets. Our simulation manifests that the direct substitution of Q-table by a deep neural network may not yield minimal delivery delays because the neural network does not learn more from the same input. When more information is utilized, adaptive routing policy can converge and significantly reduce the packet delivery time.
* 8 pages, 9 figures