 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable GNN-Based Power Allocation for Rate-Splitting Cell-Free Massive MIMO Systems
Jun 01, 2026Cell-free massive multiple-input multiple-output (CF-mMIMO) systems provide enhanced coverage and capacity for next-generation wireless networks. However, CF-mMIMO systems face significant challenges in downlink power allocation (PA) due to imperfect channel state information (CSI), severe multi-user interference (MUI), and high computational complexity. To address these issues, rate-splitting multiple access (RSMA) is adopted as a robust interference management strategy. Accordingly, this paper proposes an unsupervised and scalable graph neural network (GNN) framework for PA in rate-splitting CF-mMIMO (RS-CF-mMIMO) systems, relying exclusively on large-scale fading (LSF) coefficients without instantaneous CSI. To resolve the dimensionality mismatch in dynamic networks, we introduce a slice-based adaptive layer that projects variable-dimension features into a fixed latent space. This mechanism enables a unified model to generalize across diverse topologies without retraining. Within this architecture, the sum spectral efficiency (SE) is maximized under per-AP power constraints, assuming maximum-ratio precoding for common streams and regularized zero-forcing precoding for private streams. We also derive a weighted minimum mean-square error-alternating direction method of multipliers (WMMSE-ADMM) algorithm as a performance upper bound. Extensive simulations verify that the proposed GNN framework achieves near-optimal SE and outperforms unsupervised deep neural networks (DNNs) across diverse system sizes and pilot assignment schemes. Furthermore, the scalable variant maintains robust performance while reducing the trainable parameter count by over 57% relative to DNNs and decreasing inference latency by up to three orders of magnitude compared with WMMSE-ADMM.
SIREN: Unified Multi-Granularity Semantic Interaction for Multi-Modal Lifelong User Interest Modeling
May 25, 2026Industrial recommender systems increasingly leverage lifelong user behavior histories and rich multi-modal content to capture evolving user preferences. However, effectively integrating multi-modal features into lifelong interest modeling remains challenging due to the inherent misalignment between multi-modal and collaborative spaces. Existing paradigms typically rely on separate modeling of multi-modal sequence and behavior sequence, and late fusion to alleviate the modality gap, which results in coarse-grained multi-modal representation and limited integration. In this paper, we propose SIREN, a unified multi-granularity semantic interaction framework for multi-modal lifelong user interest modeling. In the General Search Unit stage, we introduce two alternative retrieval strategies: multi-modal similarity-based soft retrieval for retrieval effectiveness, and Semantic ID (SemID)-based hard retrieval for efficient industrial serving. For the Exact Search Unit stage, we explicitly incorporate target-aware relevance via coarse similarity buckets and fine-grained prefix-encoded SemIDs, enabling unified interaction with collaborative ID features within the target-conditioned transformer architecture. Extensive experiments on the offline dataset demonstrate that SIREN achieves a state-of-the-art GAUC. Online A/B tests further demonstrate consistent GMV gains across multiple production scenarios, including +2.28% in Weixin Moments, +3.87% in Weixin Official Accounts, and +1.61% in Weixin Channels. From July 2025, SIREN has been fully launched for full-traffic serving in Tencent's advertising platform.
RankUp: Towards High-rank Representations for Large Scale Advertising Recommender Systems
Apr 21, 2026The scaling laws for recommender systems have been increasingly validated, where MetaFormer-based architectures consistently benefit from increased model depth, hidden dimensionality, and user behavior sequence length. However, whether representation capacity scales proportionally with parameter growth remains largely unexplored. Prior studies on RankMixer reveal that the effective rank of token representations exhibits a damped oscillatory trajectory across layers, failing to increase consistently with depth and even degrading in deeper layers. Motivated by this observation, we propose \textbf{RankUp}, an architecture designed to mitigate representation collapse and enhance expressive capacity through randomized permutation splitting over sparse features, a multi-embedding paradigm, global token integration, crossed pretrained embedding tokens and task-specific token decoupling. RankUp has been fully deployed in large-scale production across Weixin Video Accounts, Official Accounts and Moments, yielding GMV improvements of 3.41\%, 4.81\% and 2.21\%, respectively.
Scalable Dexterous Robot Learning with AR-based Remote Human-Robot Interactions
Feb 07, 2026This paper focuses on the scalable robot learning for manipulation in the dexterous robot arm-hand systems, where the remote human-robot interactions via augmented reality (AR) are established to collect the expert demonstration data for improving efficiency. In such a system, we present a unified framework to address the general manipulation task problem. Specifically, the proposed method consists of two phases: i) In the first phase for pretraining, the policy is created in a behavior cloning (BC) manner, through leveraging the learning data from our AR-based remote human-robot interaction system; ii) In the second phase, a contrastive learning empowered reinforcement learning (RL) method is developed to obtain more efficient and robust policy than the BC, and thus a projection head is designed to accelerate the learning progress. An event-driven augmented reward is adopted for enhancing the safety. To validate the proposed method, both the physics simulations via PyBullet and real-world experiments are carried out. The results demonstrate that compared to the classic proximal policy optimization and soft actor-critic policies, our method not only significantly speeds up the inference, but also achieves much better performance in terms of the success rate for fulfilling the manipulation tasks. By conducting the ablation study, it is confirmed that the proposed RL with contrastive learning overcomes policy collapse. Supplementary demonstrations are available at https://cyberyyc.github.io/.
Yanyun-3: Enabling Cross-Platform Strategy Game Operation with Vision-Language Models
Nov 17, 2025Automated operation in cross-platform strategy games demands agents with robust generalization across diverse user interfaces and dynamic battlefield conditions. While vision-language models (VLMs) have shown considerable promise in multimodal reasoning, their application to complex human-computer interaction scenarios--such as strategy gaming--remains largely unexplored. Here, we introduce Yanyun-3, a general-purpose agent framework that, for the first time, enables autonomous cross-platform operation across three heterogeneous strategy game environments. By integrating the vision-language reasoning of Qwen2.5-VL with the precise execution capabilities of UI-TARS, Yanyun-3 successfully performs core tasks including target localization, combat resource allocation, and area control. Through systematic ablation studies, we evaluate the effects of various multimodal data combinations--static images, multi-image sequences, and videos--and propose the concept of combination granularity to differentiate between intra-sample fusion and inter-sample mixing strategies. We find that a hybrid strategy, which fuses multi-image and video data while mixing in static images (MV+S), substantially outperforms full fusion: it reduces inference time by 63% and boosts the BLEU-4 score by a factor of 12 (from 4.81% to 62.41%, approximately 12.98x). Operating via a closed-loop pipeline of screen capture, model inference, and action execution, the agent demonstrates strong real-time performance and cross-platform generalization. Beyond providing an efficient solution for strategy game automation, our work establishes a general paradigm for enhancing VLM performance through structured multimodal data organization, offering new insights into the interplay between static perception and dynamic reasoning in embodied intelligence.
Large Foundation Model for Ads Recommendation
Aug 20, 2025


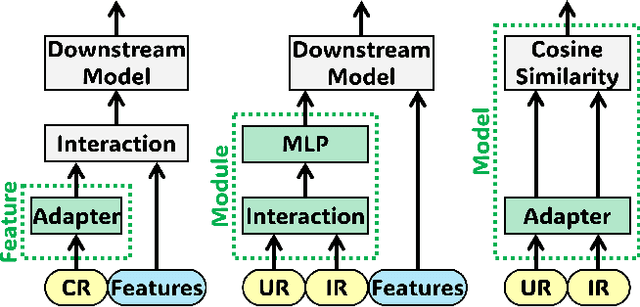
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
A Knowledge-enhanced Pathology Vision-language Foundation Model for Cancer Diagnosis
Dec 17, 2024



Deep learning has enabled the development of highly robust foundation models for various pathological tasks across diverse diseases and patient cohorts. Among these models, vision-language pre-training, which leverages large-scale paired data to align pathology image and text embedding spaces, and provides a novel zero-shot paradigm for downstream tasks. However, existing models have been primarily data-driven and lack the incorporation of domain-specific knowledge, which limits their performance in cancer diagnosis, especially for rare tumor subtypes. To address this limitation, we establish a Knowledge-enhanced Pathology (KEEP) foundation model that harnesses disease knowledge to facilitate vision-language pre-training. Specifically, we first construct a disease knowledge graph (KG) that covers 11,454 human diseases with 139,143 disease attributes, including synonyms, definitions, and hypernym relations. We then systematically reorganize the millions of publicly available noisy pathology image-text pairs, into 143K well-structured semantic groups linked through the hierarchical relations of the disease KG. To derive more nuanced image and text representations, we propose a novel knowledge-enhanced vision-language pre-training approach that integrates disease knowledge into the alignment within hierarchical semantic groups instead of unstructured image-text pairs. Validated on 18 diverse benchmarks with more than 14,000 whole slide images (WSIs), KEEP achieves state-of-the-art performance in zero-shot cancer diagnostic tasks. Notably, for cancer detection, KEEP demonstrates an average sensitivity of 89.8% at a specificity of 95.0% across 7 cancer types. For cancer subtyping, KEEP achieves a median balanced accuracy of 0.456 in subtyping 30 rare brain cancers, indicating strong generalizability for diagnosing rare tumors.
Spatial-spectral Cell-free Networks: A Large-scale Case Study
Jul 16, 2024



This paper studies the large-scale cell-free networks where dense distributed access points (APs) serve many users. As a promising next-generation network architecture, cell-free networks enable ultra-reliable connections and minimal fading/blockage, which are much favorable to the millimeter wave and Terahertz transmissions. However, conventional beam management with large phased arrays in a cell is very time-consuming in the higher-frequencies, and could be worsened when deploying a large number of coordinated APs in the cell-free systems. To tackle this challenge, the spatial-spectral cell-free networks with the leaky-wave antennas are established by coupling the propagation angles with frequencies. The beam training overhead in this direction can be significantly reduced through exploiting such spatial-spectral coupling effects. In the considered large-scale spatial-spectral cell-free networks, a novel subchannel allocation solution at sub-terahertz bands is proposed by leveraging the relationship between cross-entropy method and mixture model. Since initial access and AP clustering play a key role in achieving scalable large-scale cell-free networks, a hierarchical AP clustering solution is proposed to make the joint initial access and cluster formation, which is adaptive and has no need to initialize the number of AP clusters. After AP clustering, a subchannel allocation solution is devised to manage the interference between AP clusters. Numerical results are presented to confirm the efficiency of the proposed solutions and indicate that besides subchannel allocation, AP clustering can also have a big impact on the large-scale cell-free network performance at sub-terahertz bands.
Hierarchical Reinforcement Learning Empowered Task Offloading in V2I Networks
May 18, 2024



Edge computing plays an essential role in the vehicle-to-infrastructure (V2I) networks, where vehicles offload their intensive computation tasks to the road-side units for saving energy and reduce the latency. This paper designs the optimal task offloading policy to address the concerns involving processing delay, energy consumption and edge computing cost. Each computation task consisting of some interdependent sub-tasks is characterized as a directed acyclic graph (DAG). In such dynamic networks, a novel hierarchical Offloading scheme is proposed by leveraging deep reinforcement learning (DRL). The inter-dependencies among the DAGs of the computation tasks are extracted using a graph neural network with attention mechanism. A parameterized DRL algorithm is developed to deal with the hierarchical action space containing both discrete and continuous actions. Simulation results with a real-world car speed dataset demonstrate that the proposed scheme can effectively reduce the system overhead.
Scalable Multiuser Immersive Communications with Multi-numerology and Mini-slot
Sep 16, 2023



This paper studies multiuser immersive communications networks in which different user equipment may demand various extended reality (XR) services. In such heterogeneous networks, time-frequency resource allocation needs to be more adaptive since XR services are usually multi-modal and latency-sensitive. To this end, we develop a scalable time-frequency resource allocation method based on multi-numerology and mini-slot. To appropriately determining the discrete parameters of multi-numerology and mini-slot for multiuser immersive communications, the proposed method first presents a novel flexible time-frequency resource block configuration, then it leverages the deep reinforcement learning to maximize the total quality-of-experience (QoE) under different users' QoE constraints. The results confirm the efficiency and scalability of the proposed time-frequency resource allocation method.