 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePull Requests as a Training Signal for Repo-Level Code Editing
Feb 07, 2026Repository-level code editing requires models to understand complex dependencies and execute precise multi-file modifications across a large codebase. While recent gains on SWE-bench rely heavily on complex agent scaffolding, it remains unclear how much of this capability can be internalised via high-quality training signals. To address this, we propose Clean Pull Request (Clean-PR), a mid-training paradigm that leverages real-world GitHub pull requests as a training signal for repository-level editing. We introduce a scalable pipeline that converts noisy pull request diffs into Search/Replace edit blocks through reconstruction and validation, resulting in the largest publicly available corpus of 2 million pull requests spanning 12 programming languages. Using this training signal, we perform a mid-training stage followed by an agentless-aligned supervised fine-tuning process with error-driven data augmentation. On SWE-bench, our model significantly outperforms the instruction-tuned baseline, achieving absolute improvements of 13.6% on SWE-bench Lite and 12.3% on SWE-bench Verified. These results demonstrate that repository-level code understanding and editing capabilities can be effectively internalised into model weights under a simplified, agentless protocol, without relying on heavy inference-time scaffolding.
Trading Vector Data in Vector Databases
Nov 10, 2025Vector data trading is essential for cross-domain learning with vector databases, yet it remains largely unexplored. We study this problem under online learning, where sellers face uncertain retrieval costs and buyers provide stochastic feedback to posted prices. Three main challenges arise: (1) heterogeneous and partial feedback in configuration learning, (2) variable and complex feedback in pricing learning, and (3) inherent coupling between configuration and pricing decisions. We propose a hierarchical bandit framework that jointly optimizes retrieval configurations and pricing. Stage I employs contextual clustering with confidence-based exploration to learn effective configurations with logarithmic regret. Stage II adopts interval-based price selection with local Taylor approximation to estimate buyer responses and achieve sublinear regret. We establish theoretical guarantees with polynomial time complexity and validate the framework on four real-world datasets, demonstrating consistent improvements in cumulative reward and regret reduction compared with existing methods.
Semantic Caching for Low-Cost LLM Serving: From Offline Learning to Online Adaptation
Aug 12, 2025Large Language Models (LLMs) are revolutionizing how users interact with information systems, yet their high inference cost poses serious scalability and sustainability challenges. Caching inference responses, allowing them to be retrieved without another forward pass through the LLM, has emerged as one possible solution. Traditional exact-match caching, however, overlooks the semantic similarity between queries, leading to unnecessary recomputation. Semantic caching addresses this by retrieving responses based on semantic similarity, but introduces a fundamentally different cache eviction problem: one must account for mismatch costs between incoming queries and cached responses. Moreover, key system parameters, such as query arrival probabilities and serving costs, are often unknown and must be learned over time. Existing semantic caching methods are largely ad-hoc, lacking theoretical foundations and unable to adapt to real-world uncertainty. In this paper, we present a principled, learning-based framework for semantic cache eviction under unknown query and cost distributions. We formulate both offline optimization and online learning variants of the problem, and develop provably efficient algorithms with state-of-the-art guarantees. We also evaluate our framework on a synthetic dataset, showing that our proposed algorithms perform matching or superior performance compared with baselines.
A Unified Online-Offline Framework for Co-Branding Campaign Recommendations
May 28, 2025



Co-branding has become a vital strategy for businesses aiming to expand market reach within recommendation systems. However, identifying effective cross-industry partnerships remains challenging due to resource imbalances, uncertain brand willingness, and ever-changing market conditions. In this paper, we provide the first systematic study of this problem and propose a unified online-offline framework to enable co-branding recommendations. Our approach begins by constructing a bipartite graph linking ``initiating'' and ``target'' brands to quantify co-branding probabilities and assess market benefits. During the online learning phase, we dynamically update the graph in response to market feedback, while striking a balance between exploring new collaborations for long-term gains and exploiting established partnerships for immediate benefits. To address the high initial co-branding costs, our framework mitigates redundant exploration, thereby enhancing short-term performance while ensuring sustainable strategic growth. In the offline optimization phase, our framework consolidates the interests of multiple sub-brands under the same parent brand to maximize overall returns, avoid excessive investment in single sub-brands, and reduce unnecessary costs associated with over-prioritizing a single sub-brand. We present a theoretical analysis of our approach, establishing a highly nontrivial sublinear regret bound for online learning in the complex co-branding problem, and enhancing the approximation guarantee for the NP-hard offline budget allocation optimization. Experiments on both synthetic and real-world co-branding datasets demonstrate the practical effectiveness of our framework, with at least 12\% improvement.
Leveraging the Power of Conversations: Optimal Key Term Selection in Conversational Contextual Bandits
May 27, 2025



Conversational recommender systems proactively query users with relevant "key terms" and leverage the feedback to elicit users' preferences for personalized recommendations. Conversational contextual bandits, a prevalent approach in this domain, aim to optimize preference learning by balancing exploitation and exploration. However, several limitations hinder their effectiveness in real-world scenarios. First, existing algorithms employ key term selection strategies with insufficient exploration, often failing to thoroughly probe users' preferences and resulting in suboptimal preference estimation. Second, current algorithms typically rely on deterministic rules to initiate conversations, causing unnecessary interactions when preferences are well-understood and missed opportunities when preferences are uncertain. To address these limitations, we propose three novel algorithms: CLiSK, CLiME, and CLiSK-ME. CLiSK introduces smoothed key term contexts to enhance exploration in preference learning, CLiME adaptively initiates conversations based on preference uncertainty, and CLiSK-ME integrates both techniques. We theoretically prove that all three algorithms achieve a tighter regret upper bound of $O(\sqrt{dT\log{T}})$ with respect to the time horizon $T$, improving upon existing methods. Additionally, we provide a matching lower bound $\Omega(\sqrt{dT})$ for conversational bandits, demonstrating that our algorithms are nearly minimax optimal. Extensive evaluations on both synthetic and real-world datasets show that our approaches achieve at least a 14.6% improvement in cumulative regret.
Offline Learning for Combinatorial Multi-armed Bandits
Jan 31, 2025



The combinatorial multi-armed bandit (CMAB) is a fundamental sequential decision-making framework, extensively studied over the past decade. However, existing work primarily focuses on the online setting, overlooking the substantial costs of online interactions and the readily available offline datasets. To overcome these limitations, we introduce Off-CMAB, the first offline learning framework for CMAB. Central to our framework is the combinatorial lower confidence bound (CLCB) algorithm, which combines pessimistic reward estimations with combinatorial solvers. To characterize the quality of offline datasets, we propose two novel data coverage conditions and prove that, under these conditions, CLCB achieves a near-optimal suboptimality gap, matching the theoretical lower bound up to a logarithmic factor. We validate Off-CMAB through practical applications, including learning to rank, large language model (LLM) caching, and social influence maximization, showing its ability to handle nonlinear reward functions, general feedback models, and out-of-distribution action samples that excludes optimal or even feasible actions. Extensive experiments on synthetic and real-world datasets further highlight the superior performance of CLCB.
Multi-Agent Conversational Online Learning for Adaptive LLM Response Identification
Jan 03, 2025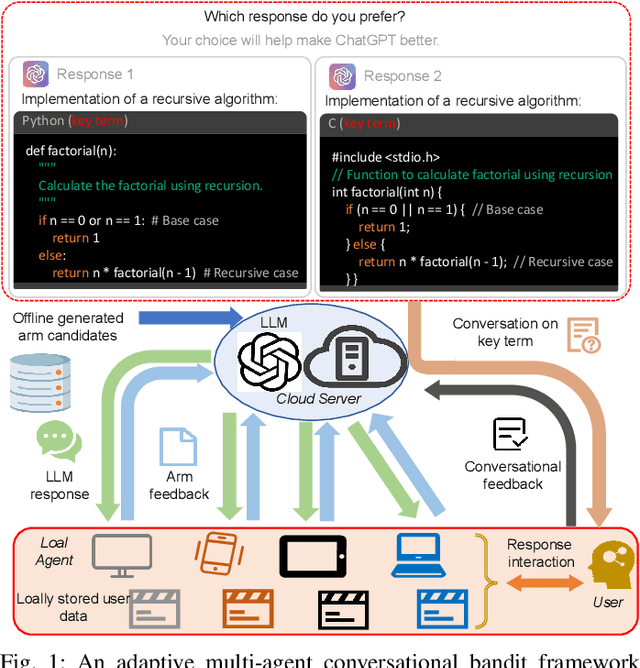


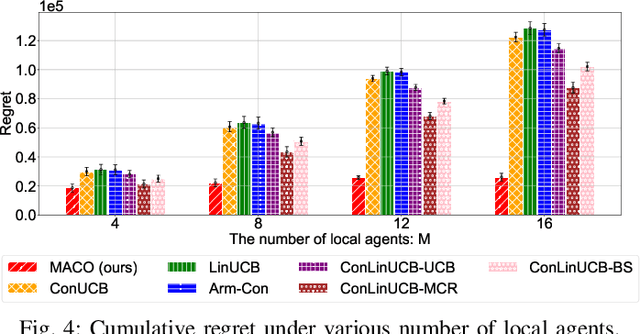
The remarkable generative capability of large language models (LLMs) has sparked a growing interest in automatically generating responses for different applications. Given the dynamic nature of user preferences and the uncertainty of LLM response performance, it is crucial to design efficient online learning algorithms to identify optimal LLM responses (i.e., high-quality responses that also meet user preferences). Most existing online algorithms adopt a centralized approach and fail to leverage explicit user preferences for more efficient and personalized LLM response identification. In contrast, this paper introduces \textit{MACO} (\underline{M}ulti-\underline{A}gent \underline{C}onversational \underline{O}nline Learning for Adaptive LLM Response Identification): 1) The online LLM response identification process is accelerated by multiple local agents (such as smartphones), while enhancing data privacy; 2) A novel conversational mechanism is proposed to adaptively conduct conversations for soliciting user preferences (e.g., a preference for a humorous tone over a serious one in generated responses), so to minimize uncertainty in preference estimation. Our theoretical analysis demonstrates that \cadi\ is near-optimal regarding cumulative regret. Additionally, \cadi\ offers reduced communication costs and computational complexity by eliminating the traditional, computing-intensive ``G-optimal design" found in previous works. Extensive experiments with the open LLM \textit{Llama}, coupled with two different embedding models from Google and OpenAI for text vector representation, demonstrate that \cadi\ significantly outperforms the current state-of-the-art in online LLM response identification.
Demystifying Online Clustering of Bandits: Enhanced Exploration Under Stochastic and Smoothed Adversarial Contexts
Jan 01, 2025



The contextual multi-armed bandit (MAB) problem is crucial in sequential decision-making. A line of research, known as online clustering of bandits, extends contextual MAB by grouping similar users into clusters, utilizing shared features to improve learning efficiency. However, existing algorithms, which rely on the upper confidence bound (UCB) strategy, struggle to gather adequate statistical information to accurately identify unknown user clusters. As a result, their theoretical analyses require several strong assumptions about the "diversity" of contexts generated by the environment, leading to impractical settings, complicated analyses, and poor practical performance. Removing these assumptions has been a long-standing open problem in the clustering of bandits literature. In this paper, we provide two solutions to this open problem. First, following the i.i.d. context generation setting in existing studies, we propose two novel algorithms, UniCLUB and PhaseUniCLUB, which incorporate enhanced exploration mechanisms to accelerate cluster identification. Remarkably, our algorithms require substantially weaker assumptions while achieving regret bounds comparable to prior work. Second, inspired by the smoothed analysis framework, we propose a more practical setting that eliminates the requirement for i.i.d. context generation used in previous studies, thus enhancing the performance of existing algorithms for online clustering of bandits. Our technique can be applied to both graph-based and set-based clustering of bandits frameworks. Extensive evaluations on both synthetic and real-world datasets demonstrate that our proposed algorithms consistently outperform existing approaches.
Combinatorial Logistic Bandits
Oct 22, 2024



We introduce a novel framework called combinatorial logistic bandits (CLogB), where in each round, a subset of base arms (called the super arm) is selected, with the outcome of each base arm being binary and its expectation following a logistic parametric model. The feedback is governed by a general arm triggering process. Our study covers CLogB with reward functions satisfying two smoothness conditions, capturing application scenarios such as online content delivery, online learning to rank, and dynamic channel allocation. We first propose a simple yet efficient algorithm, CLogUCB, utilizing a variance-agnostic exploration bonus. Under the 1-norm triggering probability modulated (TPM) smoothness condition, CLogUCB achieves a regret bound of $\tilde{O}(d\sqrt{\kappa KT})$, where $\tilde{O}$ ignores logarithmic factors, $d$ is the dimension of the feature vector, $\kappa$ represents the nonlinearity of the logistic model, and $K$ is the maximum number of base arms a super arm can trigger. This result improves on prior work by a factor of $\tilde{O}(\sqrt{\kappa})$. We then enhance CLogUCB with a variance-adaptive version, VA-CLogUCB, which attains a regret bound of $\tilde{O}(d\sqrt{KT})$ under the same 1-norm TPM condition, improving another $\tilde{O}(\sqrt{\kappa})$ factor. VA-CLogUCB shows even greater promise under the stronger triggering probability and variance modulated (TPVM) condition, achieving a leading $\tilde{O}(d\sqrt{T})$ regret, thus removing the additional dependency on the action-size $K$. Furthermore, we enhance the computational efficiency of VA-CLogUCB by eliminating the nonconvex optimization process when the context feature map is time-invariant while maintaining the tight $\tilde{O}(d\sqrt{T})$ regret. Finally, experiments on synthetic and real-world datasets demonstrate the superior performance of our algorithms compared to benchmark algorithms.
AxiomVision: Accuracy-Guaranteed Adaptive Visual Model Selection for Perspective-Aware Video Analytics
Jul 29, 2024

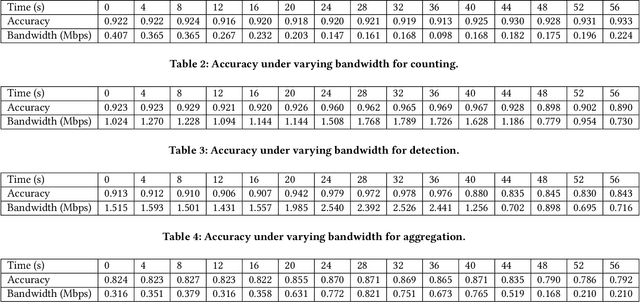

The rapid evolution of multimedia and computer vision technologies requires adaptive visual model deployment strategies to effectively handle diverse tasks and varying environments. This work introduces AxiomVision, a novel framework that can guarantee accuracy by leveraging edge computing to dynamically select the most efficient visual models for video analytics under diverse scenarios. Utilizing a tiered edge-cloud architecture, AxiomVision enables the deployment of a broad spectrum of visual models, from lightweight to complex DNNs, that can be tailored to specific scenarios while considering camera source impacts. In addition, AxiomVision provides three core innovations: (1) a dynamic visual model selection mechanism utilizing continual online learning, (2) an efficient online method that efficiently takes into account the influence of the camera's perspective, and (3) a topology-driven grouping approach that accelerates the model selection process. With rigorous theoretical guarantees, these advancements provide a scalable and effective solution for visual tasks inherent to multimedia systems, such as object detection, classification, and counting. Empirically, AxiomVision achieves a 25.7\% improvement in accuracy.