 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxiomVision: Accuracy-Guaranteed Adaptive Visual Model Selection for Perspective-Aware Video Analytics
Paper and Code


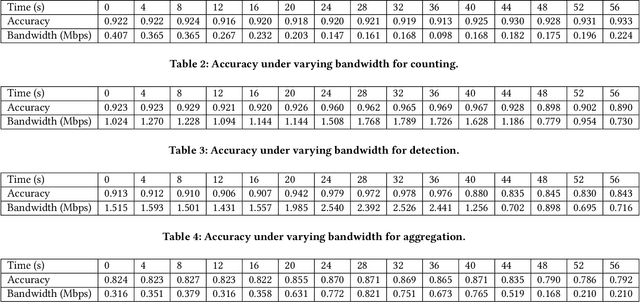

The rapid evolution of multimedia and computer vision technologies requires adaptive visual model deployment strategies to effectively handle diverse tasks and varying environments. This work introduces AxiomVision, a novel framework that can guarantee accuracy by leveraging edge computing to dynamically select the most efficient visual models for video analytics under diverse scenarios. Utilizing a tiered edge-cloud architecture, AxiomVision enables the deployment of a broad spectrum of visual models, from lightweight to complex DNNs, that can be tailored to specific scenarios while considering camera source impacts. In addition, AxiomVision provides three core innovations: (1) a dynamic visual model selection mechanism utilizing continual online learning, (2) an efficient online method that efficiently takes into account the influence of the camera's perspective, and (3) a topology-driven grouping approach that accelerates the model selection process. With rigorous theoretical guarantees, these advancements provide a scalable and effective solution for visual tasks inherent to multimedia systems, such as object detection, classification, and counting. Empirically, AxiomVision achieves a 25.7\% improvement in accuracy.