 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Best Paths in Quantum Networks
Jun 14, 2025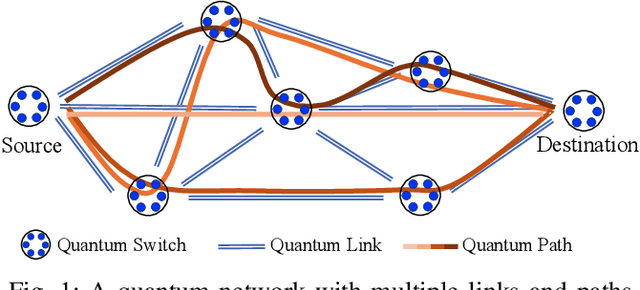



Quantum networks (QNs) transmit delicate quantum information across noisy quantum channels. Crucial applications, like quantum key distribution (QKD) and distributed quantum computation (DQC), rely on efficient quantum information transmission. Learning the best path between a pair of end nodes in a QN is key to enhancing such applications. This paper addresses learning the best path in a QN in the online learning setting. We explore two types of feedback: "link-level" and "path-level". Link-level feedback pertains to QNs with advanced quantum switches that enable link-level benchmarking. Path-level feedback, on the other hand, is associated with basic quantum switches that permit only path-level benchmarking. We introduce two online learning algorithms, BeQuP-Link and BeQuP-Path, to identify the best path using link-level and path-level feedback, respectively. To learn the best path, BeQuP-Link benchmarks the critical links dynamically, while BeQuP-Path relies on a subroutine, transferring path-level observations to estimate link-level parameters in a batch manner. We analyze the quantum resource complexity of these algorithms and demonstrate that both can efficiently and, with high probability, determine the best path. Finally, we perform NetSquid-based simulations and validate that both algorithms accurately and efficiently identify the best path.
Leveraging the Power of Conversations: Optimal Key Term Selection in Conversational Contextual Bandits
May 27, 2025



Conversational recommender systems proactively query users with relevant "key terms" and leverage the feedback to elicit users' preferences for personalized recommendations. Conversational contextual bandits, a prevalent approach in this domain, aim to optimize preference learning by balancing exploitation and exploration. However, several limitations hinder their effectiveness in real-world scenarios. First, existing algorithms employ key term selection strategies with insufficient exploration, often failing to thoroughly probe users' preferences and resulting in suboptimal preference estimation. Second, current algorithms typically rely on deterministic rules to initiate conversations, causing unnecessary interactions when preferences are well-understood and missed opportunities when preferences are uncertain. To address these limitations, we propose three novel algorithms: CLiSK, CLiME, and CLiSK-ME. CLiSK introduces smoothed key term contexts to enhance exploration in preference learning, CLiME adaptively initiates conversations based on preference uncertainty, and CLiSK-ME integrates both techniques. We theoretically prove that all three algorithms achieve a tighter regret upper bound of $O(\sqrt{dT\log{T}})$ with respect to the time horizon $T$, improving upon existing methods. Additionally, we provide a matching lower bound $\Omega(\sqrt{dT})$ for conversational bandits, demonstrating that our algorithms are nearly minimax optimal. Extensive evaluations on both synthetic and real-world datasets show that our approaches achieve at least a 14.6% improvement in cumulative regret.
Multi-Agent Conversational Online Learning for Adaptive LLM Response Identification
Jan 03, 2025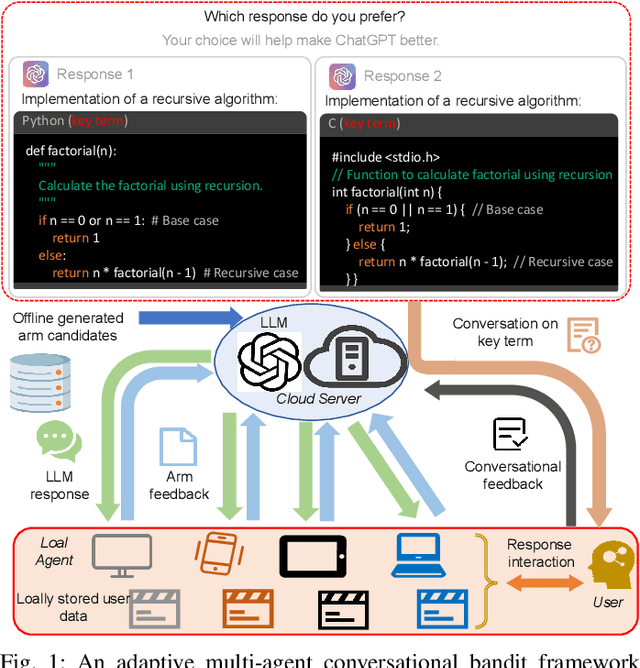


The remarkable generative capability of large language models (LLMs) has sparked a growing interest in automatically generating responses for different applications. Given the dynamic nature of user preferences and the uncertainty of LLM response performance, it is crucial to design efficient online learning algorithms to identify optimal LLM responses (i.e., high-quality responses that also meet user preferences). Most existing online algorithms adopt a centralized approach and fail to leverage explicit user preferences for more efficient and personalized LLM response identification. In contrast, this paper introduces \textit{MACO} (\underline{M}ulti-\underline{A}gent \underline{C}onversational \underline{O}nline Learning for Adaptive LLM Response Identification): 1) The online LLM response identification process is accelerated by multiple local agents (such as smartphones), while enhancing data privacy; 2) A novel conversational mechanism is proposed to adaptively conduct conversations for soliciting user preferences (e.g., a preference for a humorous tone over a serious one in generated responses), so to minimize uncertainty in preference estimation. Our theoretical analysis demonstrates that \cadi\ is near-optimal regarding cumulative regret. Additionally, \cadi\ offers reduced communication costs and computational complexity by eliminating the traditional, computing-intensive ``G-optimal design" found in previous works. Extensive experiments with the open LLM \textit{Llama}, coupled with two different embedding models from Google and OpenAI for text vector representation, demonstrate that \cadi\ significantly outperforms the current state-of-the-art in online LLM response identification.
Demystifying Online Clustering of Bandits: Enhanced Exploration Under Stochastic and Smoothed Adversarial Contexts
Jan 01, 2025



The contextual multi-armed bandit (MAB) problem is crucial in sequential decision-making. A line of research, known as online clustering of bandits, extends contextual MAB by grouping similar users into clusters, utilizing shared features to improve learning efficiency. However, existing algorithms, which rely on the upper confidence bound (UCB) strategy, struggle to gather adequate statistical information to accurately identify unknown user clusters. As a result, their theoretical analyses require several strong assumptions about the "diversity" of contexts generated by the environment, leading to impractical settings, complicated analyses, and poor practical performance. Removing these assumptions has been a long-standing open problem in the clustering of bandits literature. In this paper, we provide two solutions to this open problem. First, following the i.i.d. context generation setting in existing studies, we propose two novel algorithms, UniCLUB and PhaseUniCLUB, which incorporate enhanced exploration mechanisms to accelerate cluster identification. Remarkably, our algorithms require substantially weaker assumptions while achieving regret bounds comparable to prior work. Second, inspired by the smoothed analysis framework, we propose a more practical setting that eliminates the requirement for i.i.d. context generation used in previous studies, thus enhancing the performance of existing algorithms for online clustering of bandits. Our technique can be applied to both graph-based and set-based clustering of bandits frameworks. Extensive evaluations on both synthetic and real-world datasets demonstrate that our proposed algorithms consistently outperform existing approaches.
FedConPE: Efficient Federated Conversational Bandits with Heterogeneous Clients
May 05, 2024Conversational recommender systems have emerged as a potent solution for efficiently eliciting user preferences. These systems interactively present queries associated with "key terms" to users and leverage user feedback to estimate user preferences more efficiently. Nonetheless, most existing algorithms adopt a centralized approach. In this paper, we introduce FedConPE, a phase elimination-based federated conversational bandit algorithm, where $M$ agents collaboratively solve a global contextual linear bandit problem with the help of a central server while ensuring secure data management. To effectively coordinate all the clients and aggregate their collected data, FedConPE uses an adaptive approach to construct key terms that minimize uncertainty across all dimensions in the feature space. Furthermore, compared with existing federated linear bandit algorithms, FedConPE offers improved computational and communication efficiency as well as enhanced privacy protections. Our theoretical analysis shows that FedConPE is minimax near-optimal in terms of cumulative regret. We also establish upper bounds for communication costs and conversation frequency. Comprehensive evaluations demonstrate that FedConPE outperforms existing conversational bandit algorithms while using fewer conversations.
Hateful Memes Detection via Complementary Visual and Linguistic Networks
Dec 09, 2020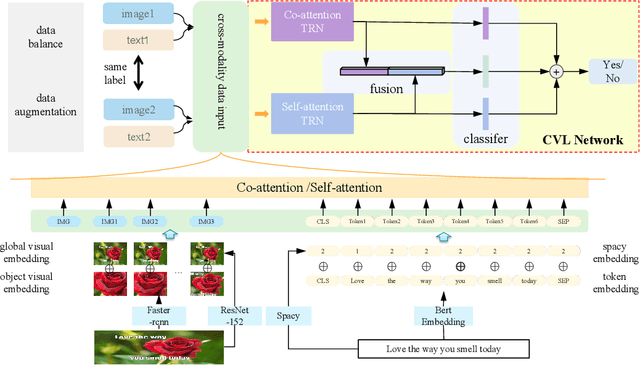
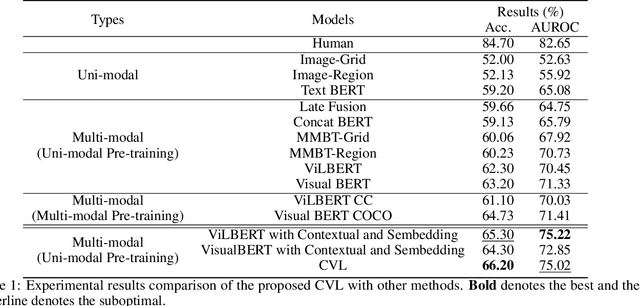
Hateful memes are widespread in social media and convey negative information. The main challenge of hateful memes detection is that the expressive meaning can not be well recognized by a single modality. In order to further integrate modal information, we investigate a candidate solution based on complementary visual and linguistic network in Hateful Memes Challenge 2020. In this way, more comprehensive information of the multi-modality could be explored in detail. Both contextual-level and sensitive object-level information are considered in visual and linguistic embedding to formulate the complex multi-modal scenarios. Specifically, a pre-trained classifier and object detector are utilized to obtain the contextual features and region-of-interests (RoIs) from the input, followed by the position representation fusion for visual embedding. While linguistic embedding is composed of three components, i.e., the sentence words embedding, position embedding and the corresponding Spacy embedding (Sembedding), which is a symbol represented by vocabulary extracted by Spacy. Both visual and linguistic embedding are fed into the designed Complementary Visual and Linguistic (CVL) networks to produce the prediction for hateful memes. Experimental results on Hateful Memes Challenge Dataset demonstrate that CVL provides a decent performance, and produces 78:48% and 72:95% on the criteria of AUROC and Accuracy. Code is available at https://github.com/webYFDT/hateful.