 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Hateful Memes Detection via Complementary Visual and Linguistic Networks
Dec 09, 2020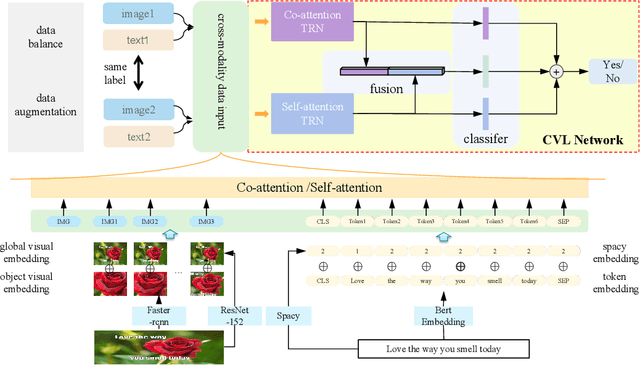
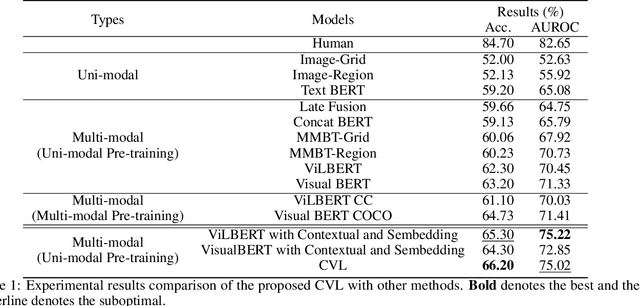
Hateful memes are widespread in social media and convey negative information. The main challenge of hateful memes detection is that the expressive meaning can not be well recognized by a single modality. In order to further integrate modal information, we investigate a candidate solution based on complementary visual and linguistic network in Hateful Memes Challenge 2020. In this way, more comprehensive information of the multi-modality could be explored in detail. Both contextual-level and sensitive object-level information are considered in visual and linguistic embedding to formulate the complex multi-modal scenarios. Specifically, a pre-trained classifier and object detector are utilized to obtain the contextual features and region-of-interests (RoIs) from the input, followed by the position representation fusion for visual embedding. While linguistic embedding is composed of three components, i.e., the sentence words embedding, position embedding and the corresponding Spacy embedding (Sembedding), which is a symbol represented by vocabulary extracted by Spacy. Both visual and linguistic embedding are fed into the designed Complementary Visual and Linguistic (CVL) networks to produce the prediction for hateful memes. Experimental results on Hateful Memes Challenge Dataset demonstrate that CVL provides a decent performance, and produces 78:48% and 72:95% on the criteria of AUROC and Accuracy. Code is available at https://github.com/webYFDT/hateful.