 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPFormer: LiDAR Pose Estimation Transformer with Multi-Task Network
Jun 21, 2023



In this technical report, we present the 1st place solution for the 2023 Waymo Open Dataset Pose Estimation challenge. Due to the difficulty of acquiring large-scale 3D human keypoint annotation, previous methods have commonly relied on 2D image features and 2D sequential annotations for 3D human pose estimation. In contrast, our proposed method, named LPFormer, uses only LiDAR as its input along with its corresponding 3D annotations. LPFormer consists of two stages: the first stage detects the human bounding box and extracts multi-level feature representations, while the second stage employs a transformer-based network to regress the human keypoints using these features. Experimental results on the Waymo Open Dataset demonstrate the top performance, and improvements even compared to previous multi-modal solutions.
LiDARFormer: A Unified Transformer-based Multi-task Network for LiDAR Perception
Mar 21, 2023



There is a recent trend in the LiDAR perception field towards unifying multiple tasks in a single strong network with improved performance, as opposed to using separate networks for each task. In this paper, we introduce a new LiDAR multi-task learning paradigm based on the transformer. The proposed LiDARFormer utilizes cross-space global contextual feature information and exploits cross-task synergy to boost the performance of LiDAR perception tasks across multiple large-scale datasets and benchmarks. Our novel transformer-based framework includes a cross-space transformer module that learns attentive features between the 2D dense Bird's Eye View (BEV) and 3D sparse voxel feature maps. Additionally, we propose a transformer decoder for the segmentation task to dynamically adjust the learned features by leveraging the categorical feature representations. Furthermore, we combine the segmentation and detection features in a shared transformer decoder with cross-task attention layers to enhance and integrate the object-level and class-level features. LiDARFormer is evaluated on the large-scale nuScenes and the Waymo Open datasets for both 3D detection and semantic segmentation tasks, and it outperforms all previously published methods on both tasks. Notably, LiDARFormer achieves the state-of-the-art performance of 76.4% L2 mAPH and 74.3% NDS on the challenging Waymo and nuScenes detection benchmarks for a single model LiDAR-only method.
LidarMultiNet: Towards a Unified Multi-task Network for LiDAR Perception
Sep 19, 2022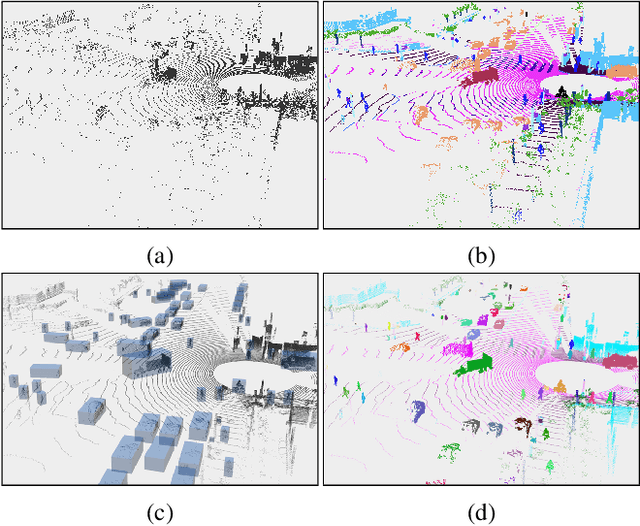
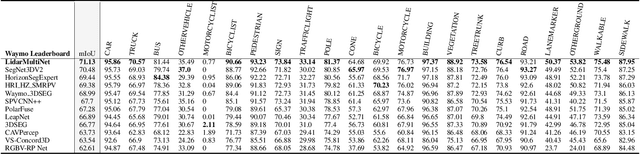
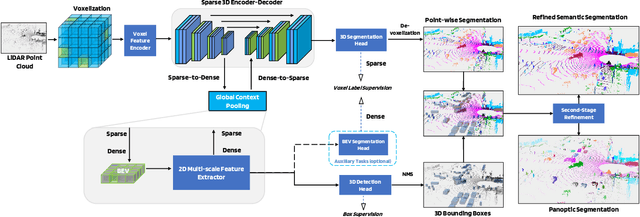

LiDAR-based 3D object detection, semantic segmentation, and panoptic segmentation are usually implemented in specialized networks with distinctive architectures that are difficult to adapt to each other. This paper presents LidarMultiNet, a LiDAR-based multi-task network that unifies these three major LiDAR perception tasks. Among its many benefits, a multi-task network can reduce the overall cost by sharing weights and computation among multiple tasks. However, it typically underperforms compared to independently combined single-task models. The proposed LidarMultiNet aims to bridge the performance gap between the multi-task network and multiple single-task networks. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder architecture with a Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame. Task-specific heads are added on top of the network to perform the three LiDAR perception tasks. More tasks can be implemented simply by adding new task-specific heads while introducing little additional cost. A second stage is also proposed to refine the first-stage segmentation and generate accurate panoptic segmentation results. LidarMultiNet is extensively tested on both Waymo Open Dataset and nuScenes dataset, demonstrating for the first time that major LiDAR perception tasks can be unified in a single strong network that is trained end-to-end and achieves state-of-the-art performance. Notably, LidarMultiNet reaches the official 1st place in the Waymo Open Dataset 3D semantic segmentation challenge 2022 with the highest mIoU and the best accuracy for most of the 22 classes on the test set, using only LiDAR points as input. It also sets the new state-of-the-art for a single model on the Waymo 3D object detection benchmark and three nuScenes benchmarks.
LidarMultiNet: Unifying LiDAR Semantic Segmentation, 3D Object Detection, and Panoptic Segmentation in a Single Multi-task Network
Jun 24, 2022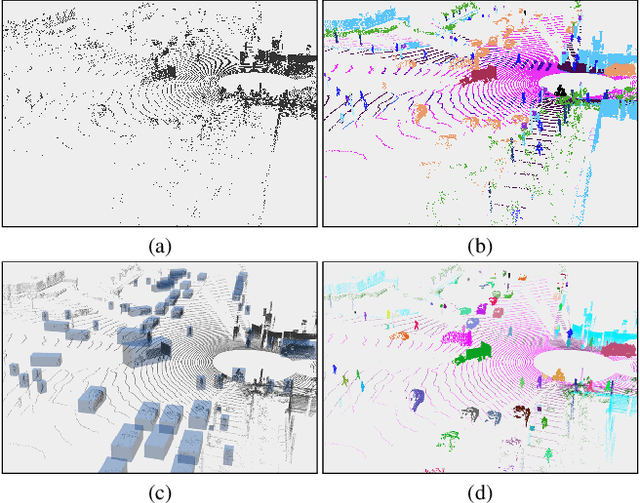
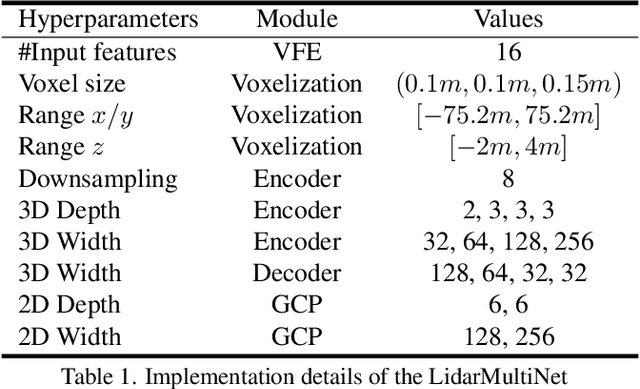
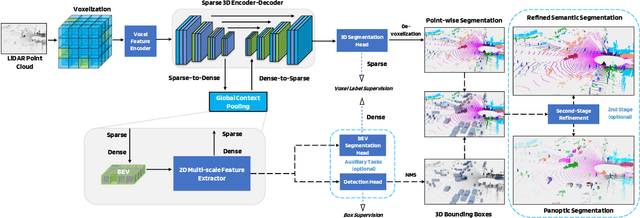
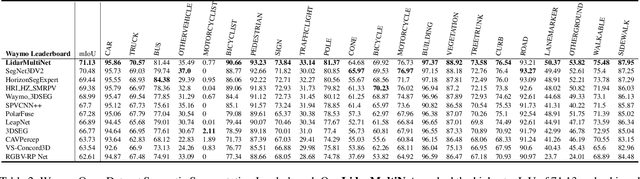
This technical report presents the 1st place winning solution for the Waymo Open Dataset 3D semantic segmentation challenge 2022. Our network, termed LidarMultiNet, unifies the major LiDAR perception tasks such as 3D semantic segmentation, object detection, and panoptic segmentation in a single framework. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder network with a novel Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame to complement its local features. An optional second stage is proposed to refine the first-stage segmentation or generate accurate panoptic segmentation results. Our solution achieves a mIoU of 71.13 and is the best for most of the 22 classes on the Waymo 3D semantic segmentation test set, outperforming all the other 3D semantic segmentation methods on the official leaderboard. We demonstrate for the first time that major LiDAR perception tasks can be unified in a single strong network that can be trained end-to-end.
Point Set Voting for Partial Point Cloud Analysis
Jul 09, 2020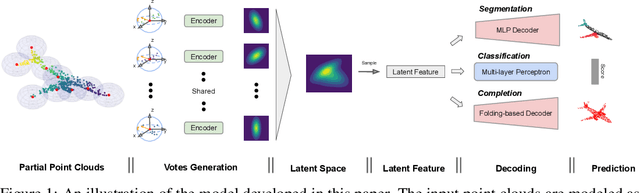
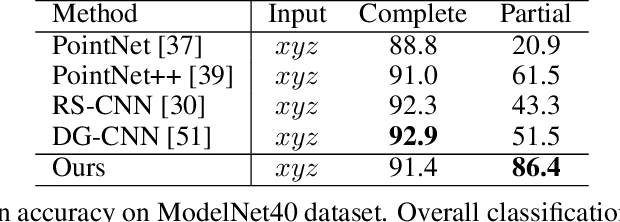
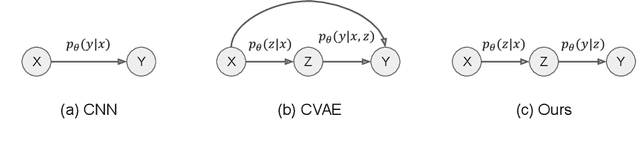
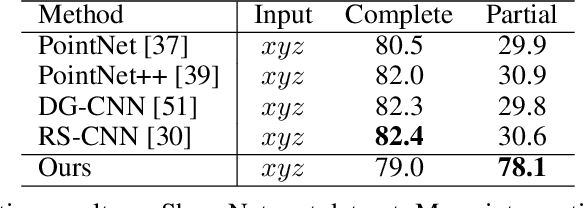
The continual improvement of 3D sensors has driven the development of algorithms to perform point cloud analysis. In fact, techniques for point cloud classification and segmentation have in recent years achieved incredible performance driven in part by leveraging large synthetic datasets. Unfortunately these same state-of-the-art approaches perform poorly when applied to incomplete point clouds. This limitation of existing algorithms is particularly concerning since point clouds generated by 3D sensors in the real world are usually incomplete due to perspective view or occlusion by other objects. This paper proposes a general model for partial point clouds analysis wherein the latent feature encoding a complete point clouds is inferred by applying a local point set voting strategy. In particular, each local point set constructs a vote that corresponds to a distribution in the latent space, and the optimal latent feature is the one with the highest probability. This approach ensures that any subsequent point cloud analysis is robust to partial observation while simultaneously guaranteeing that the proposed model is able to output multiple possible results. This paper illustrates that this proposed method achieves state-of-the-art performance on shape classification, part segmentation and point cloud completion.
AliMe KBQA: Question Answering over Structured Knowledge for E-commerce Customer Service
Dec 12, 2019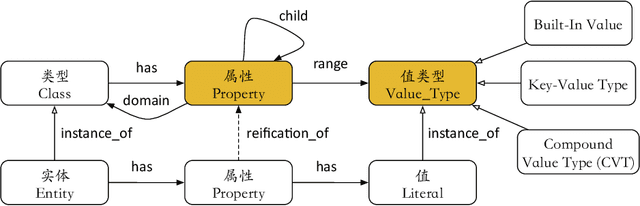

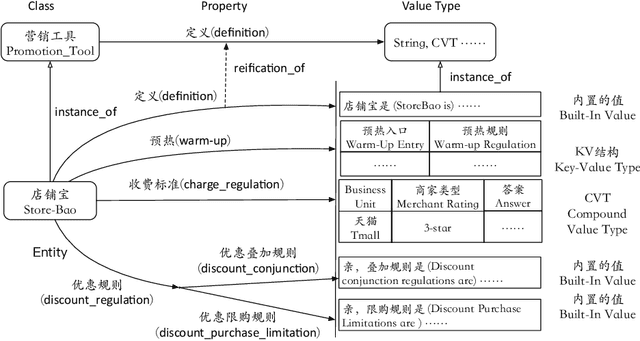
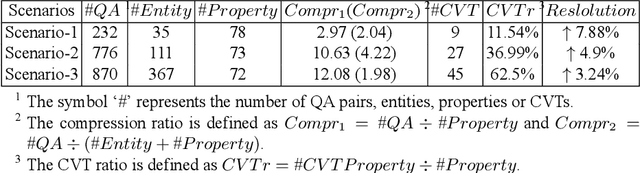
With the rise of knowledge graph (KG), question answering over knowledge base (KBQA) has attracted increasing attention in recent years. Despite much research has been conducted on this topic, it is still challenging to apply KBQA technology in industry because business knowledge and real-world questions can be rather complicated. In this paper, we present AliMe-KBQA, a bold attempt to apply KBQA in the E-commerce customer service field. To handle real knowledge and questions, we extend the classic "subject-predicate-object (SPO)" structure with property hierarchy, key-value structure and compound value type (CVT), and enhance traditional KBQA with constraints recognition and reasoning ability. We launch AliMe-KBQA in the Marketing Promotion scenario for merchants during the "Double 11" period in 2018 and other such promotional events afterwards. Online results suggest that AliMe-KBQA is not only able to gain better resolution and improve customer satisfaction, but also becomes the preferred knowledge management method by business knowledge staffs since it offers a more convenient and efficient management experience.
Deep Reinforcement Learning for Multi-Resource Multi-Machine Job Scheduling
Nov 20, 2017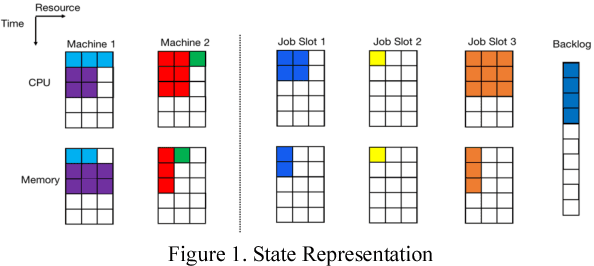
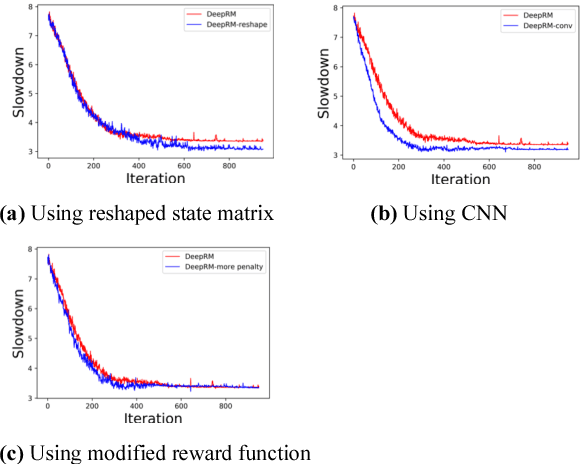
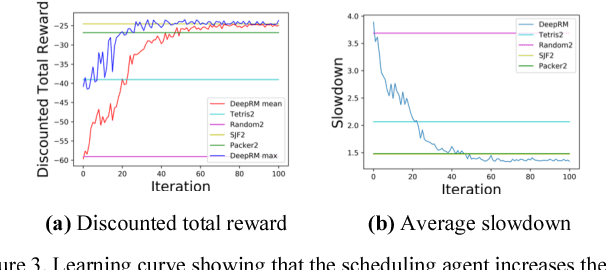
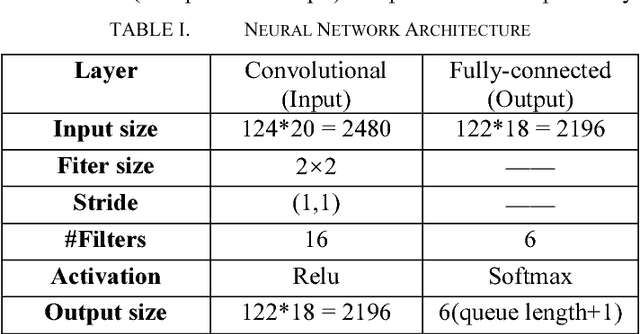
Minimizing job scheduling time is a fundamental issue in data center networks that has been extensively studied in recent years. The incoming jobs require different CPU and memory units, and span different number of time slots. The traditional solution is to design efficient heuristic algorithms with performance guarantee under certain assumptions. In this paper, we improve a recently proposed job scheduling algorithm using deep reinforcement learning and extend it to multiple server clusters. Our study reveals that deep reinforcement learning method has the potential to outperform traditional resource allocation algorithms in a variety of complicated environments.