 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrectionPlanner: Self-Correction Planner with Reinforcement Learning in Autonomous Driving
Mar 16, 2026Autonomous driving requires safe planning, but most learning-based planners lack explicit self-correction ability: once an unsafe action is proposed, there is no mechanism to correct it. Thus, we propose CorrectionPlanner, an autoregressive planner with self-correction that models planning as motion-token generation within a propose, evaluate, and correct loop. At each planning step, the policy proposes an action, namely a motion token, and a learned collision critic predicts whether it will induce a collision within a short horizon. If the critic predicts a collision, we retain the sequence of historical unsafe motion tokens as a self-correction trace, generate the next motion token conditioned on it, and repeat this process until a safe motion token is proposed or the safety criterion is met. This self-correction trace, consisting of all unsafe motion tokens, represents the planner's correction process in motion-token space, analogous to a reasoning trace in language models. We train the planner with imitation learning followed by model-based reinforcement learning using rollouts from a pretrained world model that realistically models agents' reactive behaviors. Closed-loop evaluations show that CorrectionPlanner reduces collision rate by over 20% on Waymax and achieves state-of-the-art planning scores on nuPlan.
Efficient Visual Question Answering Pipeline for Autonomous Driving via Scene Region Compression
Jan 11, 2026Autonomous driving increasingly relies on Visual Question Answering (VQA) to enable vehicles to understand complex surroundings by analyzing visual inputs and textual queries. Currently, a paramount concern for VQA in this domain is the stringent requirement for fast latency and real-time processing, as delays directly impact real-world safety in this safety-critical application. However, current state-of-the-art VQA models, particularly large vision-language models (VLMs), often prioritize performance over computational efficiency. These models typically process dense patch tokens for every frame, leading to prohibitive computational costs (FLOPs) and significant inference latency, especially with long video sequences. This focus limits their practical deployment in real-time autonomous driving scenarios. To tackle this issue, we propose an efficient VLM framework for autonomous driving VQA tasks, SRC-Pipeline. It learns to compress early frame tokens into a small number of high-level tokens while retaining full patch tokens for recent frames. Experiments on autonomous driving video question answering tasks show that our approach achieves 66% FLOPs reduction while maintaining comparable performance, enabling VLMs to operate more effectively in real-time, safety-critical autonomous driving settings.
LPFormer: LiDAR Pose Estimation Transformer with Multi-Task Network
Jun 21, 2023



In this technical report, we present the 1st place solution for the 2023 Waymo Open Dataset Pose Estimation challenge. Due to the difficulty of acquiring large-scale 3D human keypoint annotation, previous methods have commonly relied on 2D image features and 2D sequential annotations for 3D human pose estimation. In contrast, our proposed method, named LPFormer, uses only LiDAR as its input along with its corresponding 3D annotations. LPFormer consists of two stages: the first stage detects the human bounding box and extracts multi-level feature representations, while the second stage employs a transformer-based network to regress the human keypoints using these features. Experimental results on the Waymo Open Dataset demonstrate the top performance, and improvements even compared to previous multi-modal solutions.
LiDARFormer: A Unified Transformer-based Multi-task Network for LiDAR Perception
Mar 21, 2023



There is a recent trend in the LiDAR perception field towards unifying multiple tasks in a single strong network with improved performance, as opposed to using separate networks for each task. In this paper, we introduce a new LiDAR multi-task learning paradigm based on the transformer. The proposed LiDARFormer utilizes cross-space global contextual feature information and exploits cross-task synergy to boost the performance of LiDAR perception tasks across multiple large-scale datasets and benchmarks. Our novel transformer-based framework includes a cross-space transformer module that learns attentive features between the 2D dense Bird's Eye View (BEV) and 3D sparse voxel feature maps. Additionally, we propose a transformer decoder for the segmentation task to dynamically adjust the learned features by leveraging the categorical feature representations. Furthermore, we combine the segmentation and detection features in a shared transformer decoder with cross-task attention layers to enhance and integrate the object-level and class-level features. LiDARFormer is evaluated on the large-scale nuScenes and the Waymo Open datasets for both 3D detection and semantic segmentation tasks, and it outperforms all previously published methods on both tasks. Notably, LiDARFormer achieves the state-of-the-art performance of 76.4% L2 mAPH and 74.3% NDS on the challenging Waymo and nuScenes detection benchmarks for a single model LiDAR-only method.
LidarMultiNet: Towards a Unified Multi-task Network for LiDAR Perception
Sep 19, 2022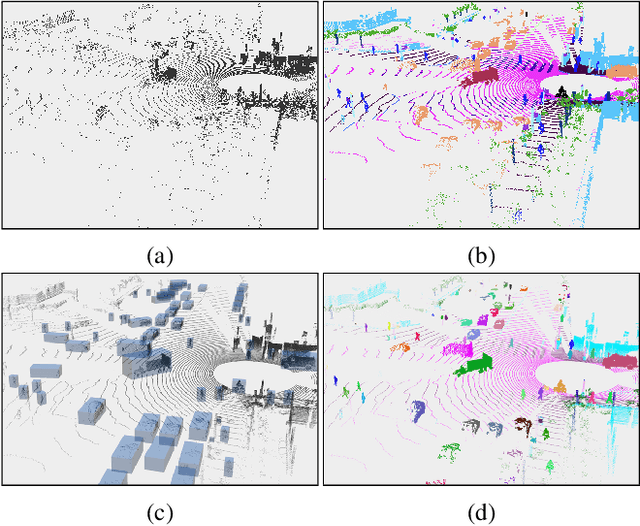
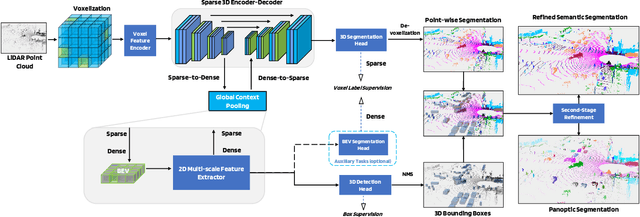

LiDAR-based 3D object detection, semantic segmentation, and panoptic segmentation are usually implemented in specialized networks with distinctive architectures that are difficult to adapt to each other. This paper presents LidarMultiNet, a LiDAR-based multi-task network that unifies these three major LiDAR perception tasks. Among its many benefits, a multi-task network can reduce the overall cost by sharing weights and computation among multiple tasks. However, it typically underperforms compared to independently combined single-task models. The proposed LidarMultiNet aims to bridge the performance gap between the multi-task network and multiple single-task networks. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder architecture with a Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame. Task-specific heads are added on top of the network to perform the three LiDAR perception tasks. More tasks can be implemented simply by adding new task-specific heads while introducing little additional cost. A second stage is also proposed to refine the first-stage segmentation and generate accurate panoptic segmentation results. LidarMultiNet is extensively tested on both Waymo Open Dataset and nuScenes dataset, demonstrating for the first time that major LiDAR perception tasks can be unified in a single strong network that is trained end-to-end and achieves state-of-the-art performance. Notably, LidarMultiNet reaches the official 1st place in the Waymo Open Dataset 3D semantic segmentation challenge 2022 with the highest mIoU and the best accuracy for most of the 22 classes on the test set, using only LiDAR points as input. It also sets the new state-of-the-art for a single model on the Waymo 3D object detection benchmark and three nuScenes benchmarks.
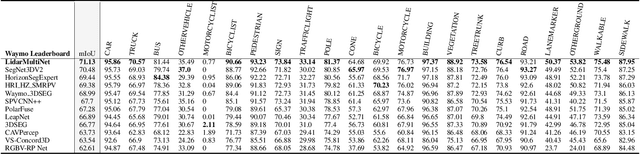
LidarMultiNet: Unifying LiDAR Semantic Segmentation, 3D Object Detection, and Panoptic Segmentation in a Single Multi-task Network
Jun 24, 2022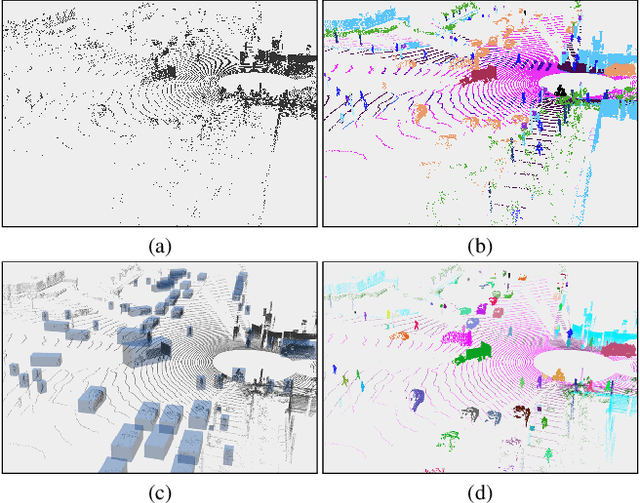
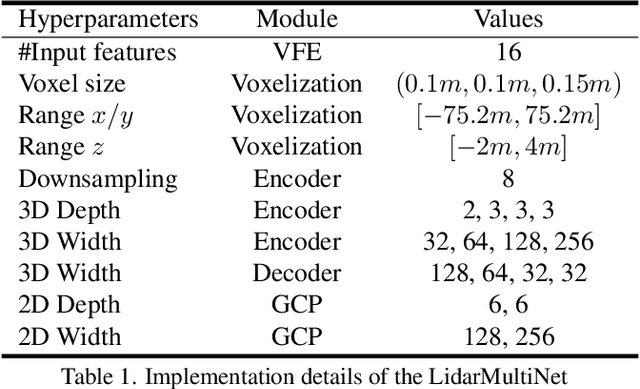
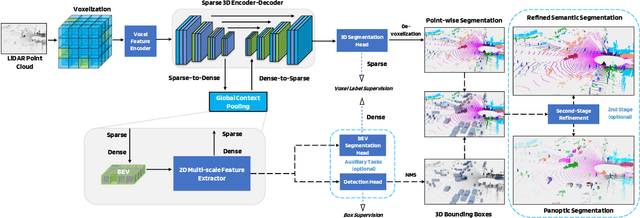
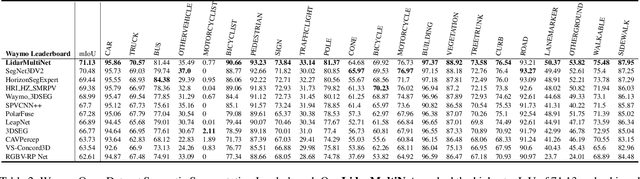
This technical report presents the 1st place winning solution for the Waymo Open Dataset 3D semantic segmentation challenge 2022. Our network, termed LidarMultiNet, unifies the major LiDAR perception tasks such as 3D semantic segmentation, object detection, and panoptic segmentation in a single framework. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder network with a novel Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame to complement its local features. An optional second stage is proposed to refine the first-stage segmentation or generate accurate panoptic segmentation results. Our solution achieves a mIoU of 71.13 and is the best for most of the 22 classes on the Waymo 3D semantic segmentation test set, outperforming all the other 3D semantic segmentation methods on the official leaderboard. We demonstrate for the first time that major LiDAR perception tasks can be unified in a single strong network that can be trained end-to-end.
LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks
Jul 26, 2018
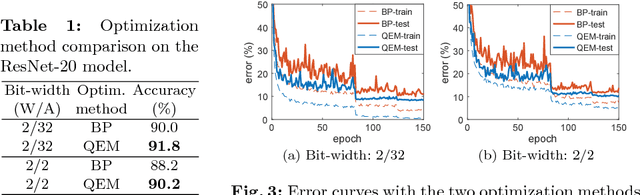


Although weight and activation quantization is an effective approach for Deep Neural Network (DNN) compression and has a lot of potentials to increase inference speed leveraging bit-operations, there is still a noticeable gap in terms of prediction accuracy between the quantized model and the full-precision model. To address this gap, we propose to jointly train a quantized, bit-operation-compatible DNN and its associated quantizers, as opposed to using fixed, handcrafted quantization schemes such as uniform or logarithmic quantization. Our method for learning the quantizers applies to both network weights and activations with arbitrary-bit precision, and our quantizers are easy to train. The comprehensive experiments on CIFAR-10 and ImageNet datasets show that our method works consistently well for various network structures such as AlexNet, VGG-Net, GoogLeNet, ResNet, and DenseNet, surpassing previous quantization methods in terms of accuracy by an appreciable margin. Code available at https://github.com/Microsoft/LQ-Nets