 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Approaches for Human Action Recognition in Video Data
Mar 11, 2024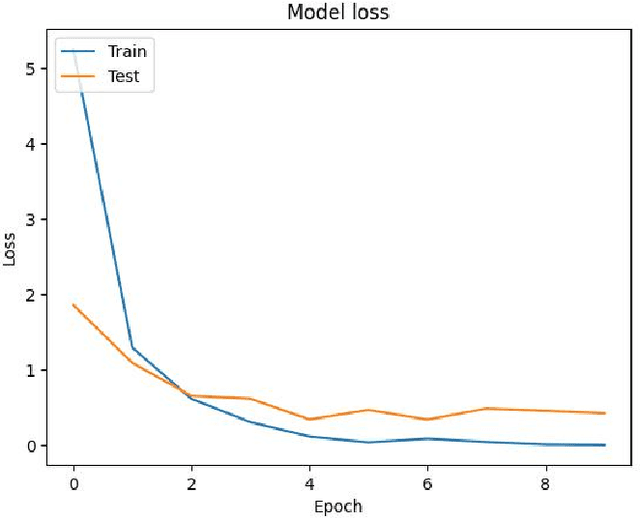
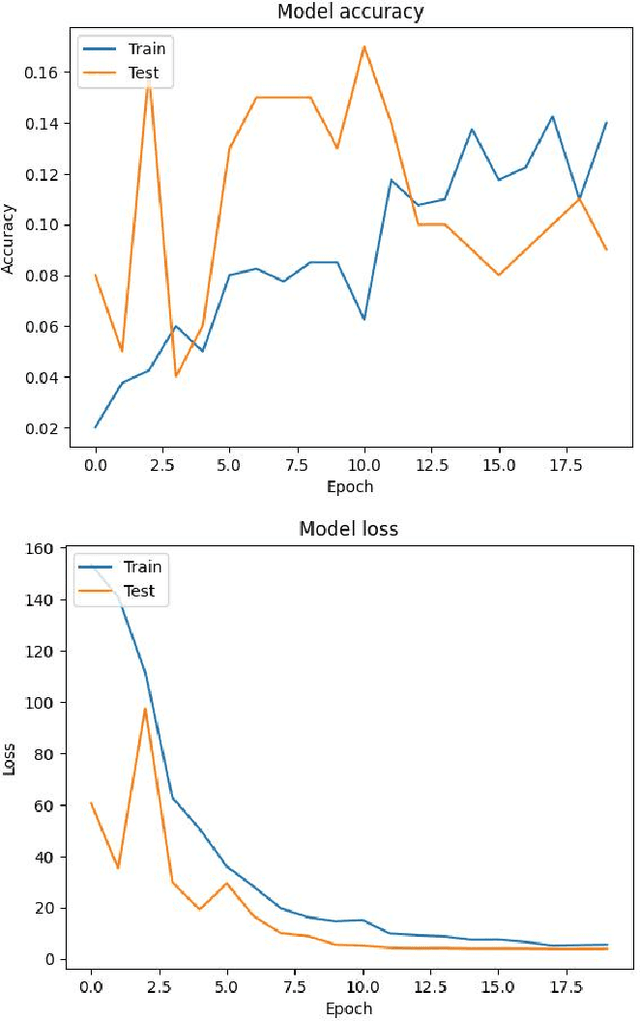

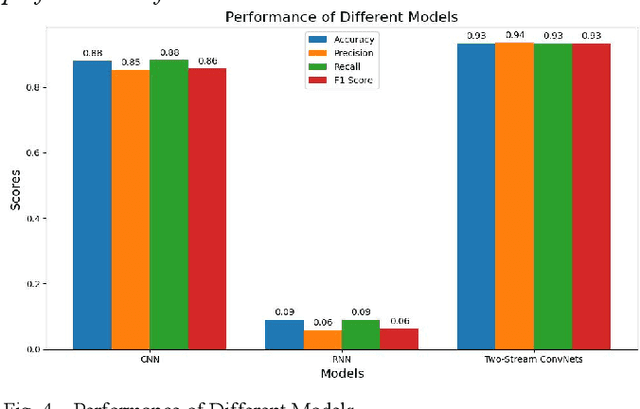
Human action recognition in videos is a critical task with significant implications for numerous applications, including surveillance, sports analytics, and healthcare. The challenge lies in creating models that are both precise in their recognition capabilities and efficient enough for practical use. This study conducts an in-depth analysis of various deep learning models to address this challenge. Utilizing a subset of the UCF101 Videos dataset, we focus on Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Two-Stream ConvNets. The research reveals that while CNNs effectively capture spatial features and RNNs encode temporal sequences, Two-Stream ConvNets exhibit superior performance by integrating spatial and temporal dimensions. These insights are distilled from the evaluation metrics of accuracy, precision, recall, and F1-score. The results of this study underscore the potential of composite models in achieving robust human action recognition and suggest avenues for future research in optimizing these models for real-world deployment.
Convolutional Neural Networks for Sentiment Analysis on Weibo Data: A Natural Language Processing Approach
Jul 13, 2023



This study addressed the complex task of sentiment analysis on a dataset of 119,988 original tweets from Weibo using a Convolutional Neural Network (CNN), offering a new approach to Natural Language Processing (NLP). The data, sourced from Baidu's PaddlePaddle AI platform, were meticulously preprocessed, tokenized, and categorized based on sentiment labels. A CNN-based model was utilized, leveraging word embeddings for feature extraction, and trained to perform sentiment classification. The model achieved a macro-average F1-score of approximately 0.73 on the test set, showing balanced performance across positive, neutral, and negative sentiments. The findings underscore the effectiveness of CNNs for sentiment analysis tasks, with implications for practical applications in social media analysis, market research, and policy studies. The complete experimental content and code have been made publicly available on the Kaggle data platform for further research and development. Future work may involve exploring different architectures, such as Recurrent Neural Networks (RNN) or transformers, or using more complex pre-trained models like BERT, to further improve the model's ability to understand linguistic nuances and context.
LPFormer: LiDAR Pose Estimation Transformer with Multi-Task Network
Jun 21, 2023



In this technical report, we present the 1st place solution for the 2023 Waymo Open Dataset Pose Estimation challenge. Due to the difficulty of acquiring large-scale 3D human keypoint annotation, previous methods have commonly relied on 2D image features and 2D sequential annotations for 3D human pose estimation. In contrast, our proposed method, named LPFormer, uses only LiDAR as its input along with its corresponding 3D annotations. LPFormer consists of two stages: the first stage detects the human bounding box and extracts multi-level feature representations, while the second stage employs a transformer-based network to regress the human keypoints using these features. Experimental results on the Waymo Open Dataset demonstrate the top performance, and improvements even compared to previous multi-modal solutions.
Producing a Standard Dataset of Speed Climbing Training Videos Using Deep Learning Techniques
May 23, 2023This dissertation presents a methodology for recording speed climbing training sessions with multiple cameras and annotating the videos with relevant data, including body position, hand and foot placement, and timing. The annotated data is then analyzed using deep learning techniques to create a standard dataset of speed climbing training videos. The results demonstrate the potential of the new dataset for improving speed climbing training and research, including identifying areas for improvement, creating personalized training plans, and analyzing the effects of different training methods.The findings will also be applied to the training process of the Jiangxi climbing team through further empirical research to test the findings and further explore the feasibility of this study.
LiDARFormer: A Unified Transformer-based Multi-task Network for LiDAR Perception
Mar 21, 2023



There is a recent trend in the LiDAR perception field towards unifying multiple tasks in a single strong network with improved performance, as opposed to using separate networks for each task. In this paper, we introduce a new LiDAR multi-task learning paradigm based on the transformer. The proposed LiDARFormer utilizes cross-space global contextual feature information and exploits cross-task synergy to boost the performance of LiDAR perception tasks across multiple large-scale datasets and benchmarks. Our novel transformer-based framework includes a cross-space transformer module that learns attentive features between the 2D dense Bird's Eye View (BEV) and 3D sparse voxel feature maps. Additionally, we propose a transformer decoder for the segmentation task to dynamically adjust the learned features by leveraging the categorical feature representations. Furthermore, we combine the segmentation and detection features in a shared transformer decoder with cross-task attention layers to enhance and integrate the object-level and class-level features. LiDARFormer is evaluated on the large-scale nuScenes and the Waymo Open datasets for both 3D detection and semantic segmentation tasks, and it outperforms all previously published methods on both tasks. Notably, LiDARFormer achieves the state-of-the-art performance of 76.4% L2 mAPH and 74.3% NDS on the challenging Waymo and nuScenes detection benchmarks for a single model LiDAR-only method.
LidarMultiNet: Towards a Unified Multi-task Network for LiDAR Perception
Sep 19, 2022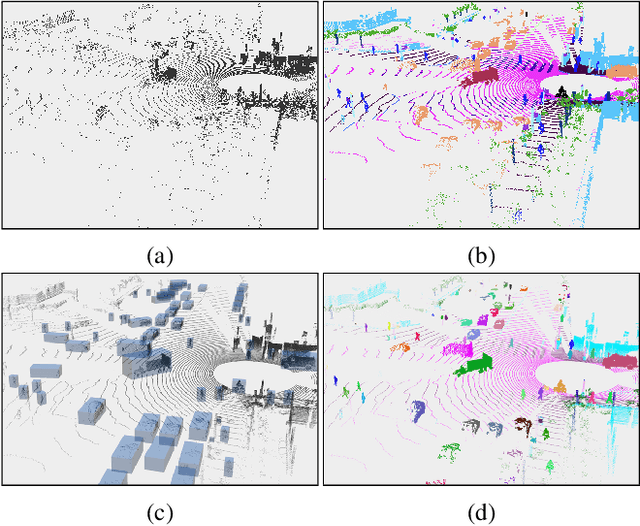
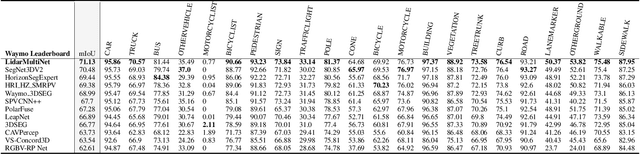
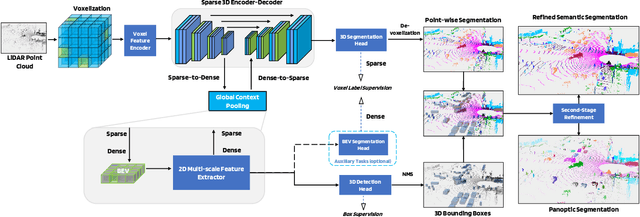

LiDAR-based 3D object detection, semantic segmentation, and panoptic segmentation are usually implemented in specialized networks with distinctive architectures that are difficult to adapt to each other. This paper presents LidarMultiNet, a LiDAR-based multi-task network that unifies these three major LiDAR perception tasks. Among its many benefits, a multi-task network can reduce the overall cost by sharing weights and computation among multiple tasks. However, it typically underperforms compared to independently combined single-task models. The proposed LidarMultiNet aims to bridge the performance gap between the multi-task network and multiple single-task networks. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder architecture with a Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame. Task-specific heads are added on top of the network to perform the three LiDAR perception tasks. More tasks can be implemented simply by adding new task-specific heads while introducing little additional cost. A second stage is also proposed to refine the first-stage segmentation and generate accurate panoptic segmentation results. LidarMultiNet is extensively tested on both Waymo Open Dataset and nuScenes dataset, demonstrating for the first time that major LiDAR perception tasks can be unified in a single strong network that is trained end-to-end and achieves state-of-the-art performance. Notably, LidarMultiNet reaches the official 1st place in the Waymo Open Dataset 3D semantic segmentation challenge 2022 with the highest mIoU and the best accuracy for most of the 22 classes on the test set, using only LiDAR points as input. It also sets the new state-of-the-art for a single model on the Waymo 3D object detection benchmark and three nuScenes benchmarks.
LidarMultiNet: Unifying LiDAR Semantic Segmentation, 3D Object Detection, and Panoptic Segmentation in a Single Multi-task Network
Jun 24, 2022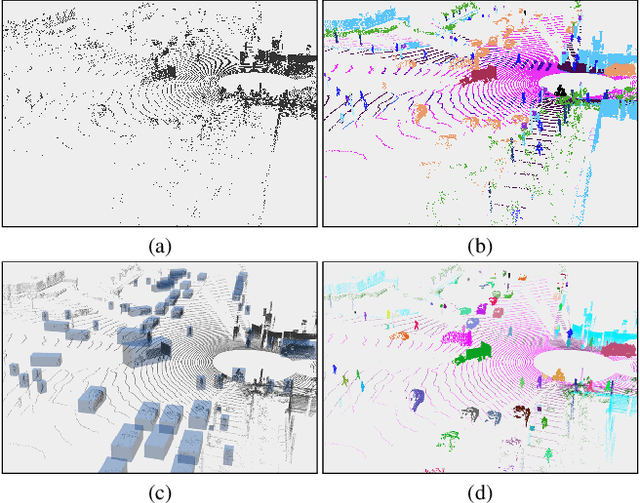
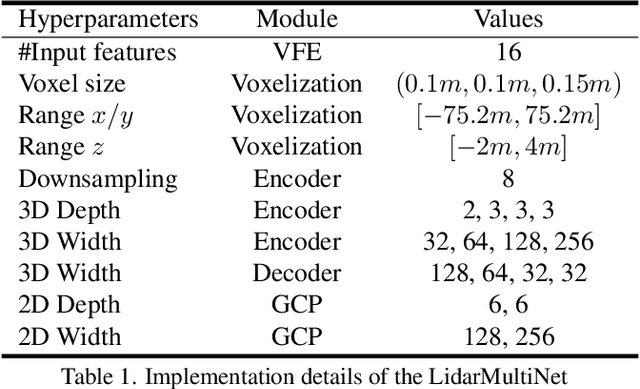
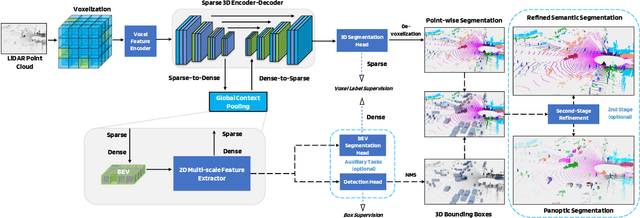
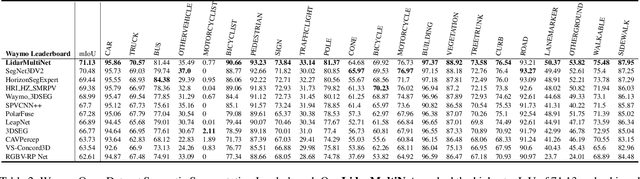
This technical report presents the 1st place winning solution for the Waymo Open Dataset 3D semantic segmentation challenge 2022. Our network, termed LidarMultiNet, unifies the major LiDAR perception tasks such as 3D semantic segmentation, object detection, and panoptic segmentation in a single framework. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder network with a novel Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame to complement its local features. An optional second stage is proposed to refine the first-stage segmentation or generate accurate panoptic segmentation results. Our solution achieves a mIoU of 71.13 and is the best for most of the 22 classes on the Waymo 3D semantic segmentation test set, outperforming all the other 3D semantic segmentation methods on the official leaderboard. We demonstrate for the first time that major LiDAR perception tasks can be unified in a single strong network that can be trained end-to-end.