 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Communication and Computation Efficient Fully First-order Method for Decentralized Bilevel Optimization
Oct 18, 2024


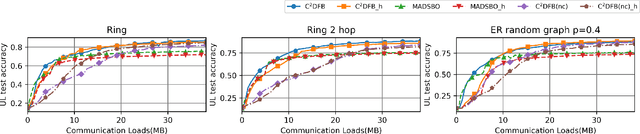
Bilevel optimization, crucial for hyperparameter tuning, meta-learning and reinforcement learning, remains less explored in the decentralized learning paradigm, such as decentralized federated learning (DFL). Typically, decentralized bilevel methods rely on both gradients and Hessian matrices to approximate hypergradients of upper-level models. However, acquiring and sharing the second-order oracle is compute and communication intensive. % and sharing this information incurs heavy communication overhead. To overcome these challenges, this paper introduces a fully first-order decentralized method for decentralized Bilevel optimization, $\text{C}^2$DFB which is both compute- and communicate-efficient. In $\text{C}^2$DFB, each learning node optimizes a min-min-max problem to approximate hypergradient by exclusively using gradients information. To reduce the traffic load at the inner-loop of solving the lower-level problem, $\text{C}^2$DFB incorporates a lightweight communication protocol for efficiently transmitting compressed residuals of local parameters. % during the inner loops. Rigorous theoretical analysis ensures its convergence % of the algorithm, indicating a first-order oracle calls of $\tilde{\mathcal{O}}(\epsilon^{-4})$. Experiments on hyperparameter tuning and hyper-representation tasks validate the superiority of $\text{C}^2$DFB across various typologies and heterogeneous data distributions.