 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Convex-Concave Problems with $\tilde{\mathcal{O}}(ε^{-4/7})$ Second-Order Oracle Complexity
Jun 10, 2025Previous algorithms can solve convex-concave minimax problems $\min_{x \in \mathcal{X}} \max_{y \in \mathcal{Y}} f(x,y)$ with $\mathcal{O}(\epsilon^{-2/3})$ second-order oracle calls using Newton-type methods. This result has been speculated to be optimal because the upper bound is achieved by a natural generalization of the optimal first-order method. In this work, we show an improved upper bound of $\tilde{\mathcal{O}}(\epsilon^{-4/7})$ by generalizing the optimal second-order method for convex optimization to solve the convex-concave minimax problem. We further apply a similar technique to lazy Hessian algorithms and show that our proposed algorithm can also be seen as a second-order ``Catalyst'' framework (Lin et al., JMLR 2018) that could accelerate any globally convergent algorithms for solving minimax problems.
A Communication and Computation Efficient Fully First-order Method for Decentralized Bilevel Optimization
Oct 18, 2024


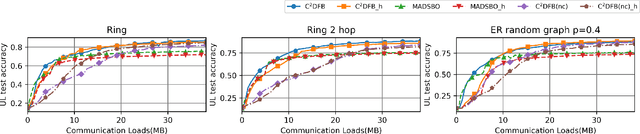
Bilevel optimization, crucial for hyperparameter tuning, meta-learning and reinforcement learning, remains less explored in the decentralized learning paradigm, such as decentralized federated learning (DFL). Typically, decentralized bilevel methods rely on both gradients and Hessian matrices to approximate hypergradients of upper-level models. However, acquiring and sharing the second-order oracle is compute and communication intensive. % and sharing this information incurs heavy communication overhead. To overcome these challenges, this paper introduces a fully first-order decentralized method for decentralized Bilevel optimization, $\text{C}^2$DFB which is both compute- and communicate-efficient. In $\text{C}^2$DFB, each learning node optimizes a min-min-max problem to approximate hypergradient by exclusively using gradients information. To reduce the traffic load at the inner-loop of solving the lower-level problem, $\text{C}^2$DFB incorporates a lightweight communication protocol for efficiently transmitting compressed residuals of local parameters. % during the inner loops. Rigorous theoretical analysis ensures its convergence % of the algorithm, indicating a first-order oracle calls of $\tilde{\mathcal{O}}(\epsilon^{-4})$. Experiments on hyperparameter tuning and hyper-representation tasks validate the superiority of $\text{C}^2$DFB across various typologies and heterogeneous data distributions.
Second-Order Min-Max Optimization with Lazy Hessians
Oct 12, 2024


This paper studies second-order methods for convex-concave minimax optimization. Monteiro and Svaiter (2012) proposed a method to solve the problem with an optimal iteration complexity of $\mathcal{O}(\epsilon^{-3/2})$ to find an $\epsilon$-saddle point. However, it is unclear whether the computational complexity, $\mathcal{O}((N+ d^2) d \epsilon^{-2/3})$, can be improved. In the above, we follow Doikov et al. (2023) and assume the complexity of obtaining a first-order oracle as $N$ and the complexity of obtaining a second-order oracle as $dN$. In this paper, we show that the computation cost can be reduced by reusing Hessian across iterations. Our methods take the overall computational complexity of $ \tilde{\mathcal{O}}( (N+d^2)(d+ d^{2/3}\epsilon^{-2/3}))$, which improves those of previous methods by a factor of $d^{1/3}$. Furthermore, we generalize our method to strongly-convex-strongly-concave minimax problems and establish the complexity of $\tilde{\mathcal{O}}((N+d^2) (d + d^{2/3} \kappa^{2/3}) )$ when the condition number of the problem is $\kappa$, enjoying a similar speedup upon the state-of-the-art method. Numerical experiments on both real and synthetic datasets also verify the efficiency of our method.
Incremental Gauss--Newton Methods with Superlinear Convergence Rates
Jul 03, 2024



This paper addresses the challenge of solving large-scale nonlinear equations with H\"older continuous Jacobians. We introduce a novel Incremental Gauss--Newton (IGN) method within explicit superlinear convergence rate, which outperforms existing methods that only achieve linear convergence rate. In particular, we formulate our problem by the nonlinear least squares with finite-sum structure, and our method incrementally iterates with the information of one component in each round. We also provide a mini-batch extension to our IGN method that obtains an even faster superlinear convergence rate. Furthermore, we conduct numerical experiments to show the advantages of the proposed methods.
Quasi-Newton Methods for Saddle Point Problems and Beyond
Nov 13, 2021

This paper studies quasi-Newton methods for solving strongly-convex-strongly-concave saddle point problems (SPP). We propose greedy and random Broyden family updates for SPP, which have explicit local superlinear convergence rate of ${\mathcal O}\big(\big(1-\frac{1}{n\kappa^2}\big)^{k(k-1)/2}\big)$, where $n$ is dimensions of the problem, $\kappa$ is the condition number and $k$ is the number of iterations. The design and analysis of proposed algorithm are based on estimating the square of indefinite Hessian matrix, which is different from classical quasi-Newton methods in convex optimization. We also present two specific Broyden family algorithms with BFGS-type and SR1-type updates, which enjoy the faster local convergence rate of $\mathcal O\big(\big(1-\frac{1}{n}\big)^{k(k-1)/2}\big)$. Additionally, we extend our algorithms to solve general nonlinear equations and prove it enjoys the similar convergence rate.