 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpediting In-Network Federated Learning by Voting-Based Consensus Model Compression
Feb 06, 2024



Recently, federated learning (FL) has gained momentum because of its capability in preserving data privacy. To conduct model training by FL, multiple clients exchange model updates with a parameter server via Internet. To accelerate the communication speed, it has been explored to deploy a programmable switch (PS) in lieu of the parameter server to coordinate clients. The challenge to deploy the PS in FL lies in its scarce memory space, prohibiting running memory consuming aggregation algorithms on the PS. To overcome this challenge, we propose Federated Learning in-network Aggregation with Compression (FediAC) algorithm, consisting of two phases: client voting and model aggregating. In the former phase, clients report their significant model update indices to the PS to estimate global significant model updates. In the latter phase, clients upload global significant model updates to the PS for aggregation. FediAC consumes much less memory space and communication traffic than existing works because the first phase can guarantee consensus compression across clients. The PS easily aligns model update indices to swiftly complete aggregation in the second phase. Finally, we conduct extensive experiments by using public datasets to demonstrate that FediAC remarkably surpasses the state-of-the-art baselines in terms of model accuracy and communication traffic.
Fed-CVLC: Compressing Federated Learning Communications with Variable-Length Codes
Feb 06, 2024



In Federated Learning (FL) paradigm, a parameter server (PS) concurrently communicates with distributed participating clients for model collection, update aggregation, and model distribution over multiple rounds, without touching private data owned by individual clients. FL is appealing in preserving data privacy; yet the communication between the PS and scattered clients can be a severe bottleneck. Model compression algorithms, such as quantization and sparsification, have been suggested but they generally assume a fixed code length, which does not reflect the heterogeneity and variability of model updates. In this paper, through both analysis and experiments, we show strong evidences that variable-length is beneficial for compression in FL. We accordingly present Fed-CVLC (Federated Learning Compression with Variable-Length Codes), which fine-tunes the code length in response of the dynamics of model updates. We develop optimal tuning strategy that minimizes the loss function (equivalent to maximizing the model utility) subject to the budget for communication. We further demonstrate that Fed-CVLC is indeed a general compression design that bridges quantization and sparsification, with greater flexibility. Extensive experiments have been conducted with public datasets to demonstrate that Fed-CVLC remarkably outperforms state-of-the-art baselines, improving model utility by 1.50%-5.44%, or shrinking communication traffic by 16.67%-41.61%.
A Fast Blockchain-based Federated Learning Framework with Compressed Communications
Aug 12, 2022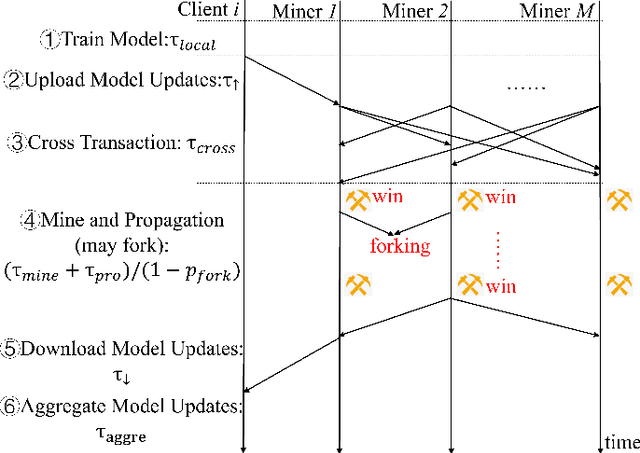

Recently, blockchain-based federated learning (BFL) has attracted intensive research attention due to that the training process is auditable and the architecture is serverless avoiding the single point failure of the parameter server in vanilla federated learning (VFL). Nevertheless, BFL tremendously escalates the communication traffic volume because all local model updates (i.e., changes of model parameters) obtained by BFL clients will be transmitted to all miners for verification and to all clients for aggregation. In contrast, the parameter server and clients in VFL only retain aggregated model updates. Consequently, the huge communication traffic in BFL will inevitably impair the training efficiency and hinder the deployment of BFL in reality. To improve the practicality of BFL, we are among the first to propose a fast blockchain-based communication-efficient federated learning framework by compressing communications in BFL, called BCFL. Meanwhile, we derive the convergence rate of BCFL with non-convex loss. To maximize the final model accuracy, we further formulate the problem to minimize the training loss of the convergence rate subject to a limited training time with respect to the compression rate and the block generation rate, which is a bi-convex optimization problem and can be efficiently solved. To the end, to demonstrate the efficiency of BCFL, we carry out extensive experiments with standard CIFAR-10 and FEMNIST datasets. Our experimental results not only verify the correctness of our analysis, but also manifest that BCFL can remarkably reduce the communication traffic by 95-98% or shorten the training time by 90-95% compared with BFL.
Optimal Rate Adaption in Federated Learning with Compressed Communications
Dec 13, 2021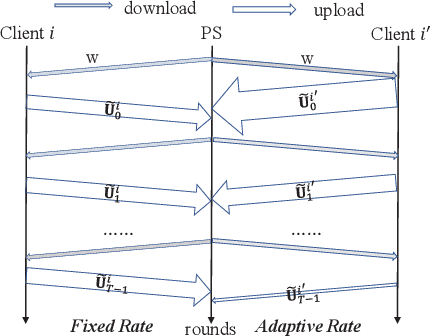
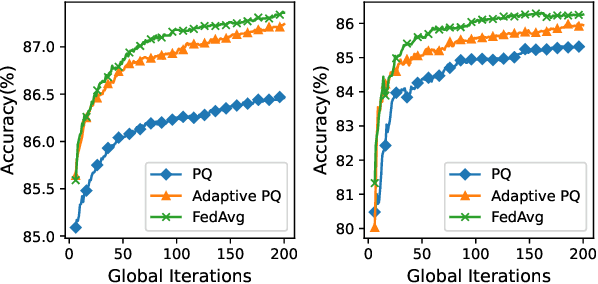
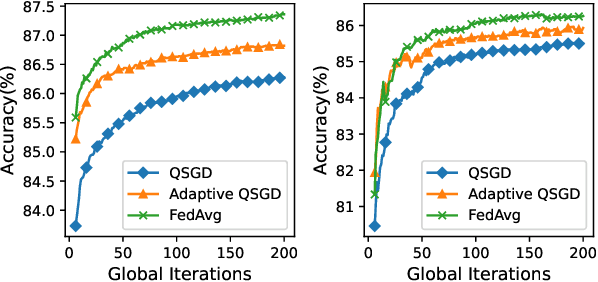
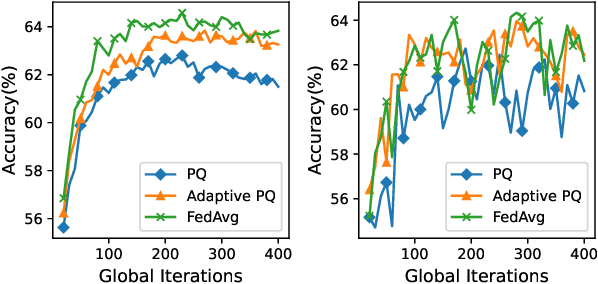
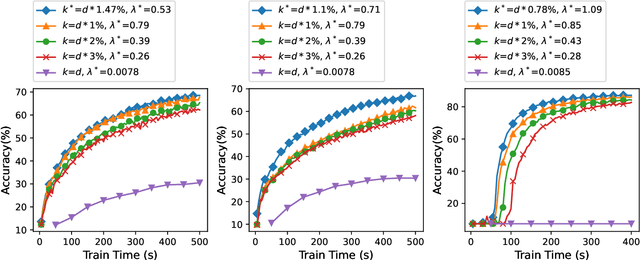
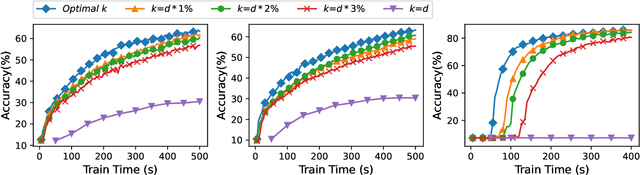
Federated Learning (FL) incurs high communication overhead, which can be greatly alleviated by compression for model updates. Yet the tradeoff between compression and model accuracy in the networked environment remains unclear and, for simplicity, most implementations adopt a fixed compression rate only. In this paper, we for the first time systematically examine this tradeoff, identifying the influence of the compression error on the final model accuracy with respect to the learning rate. Specifically, we factor the compression error of each global iteration into the convergence rate analysis under both strongly convex and non-convex loss functions. We then present an adaptation framework to maximize the final model accuracy by strategically adjusting the compression rate in each iteration. We have discussed the key implementation issues of our framework in practical networks with representative compression algorithms. Experiments over the popular MNIST and CIFAR-10 datasets confirm that our solution effectively reduces network traffic yet maintains high model accuracy in FL.
Slashing Communication Traffic in Federated Learning by Transmitting Clustered Model Updates
May 10, 2021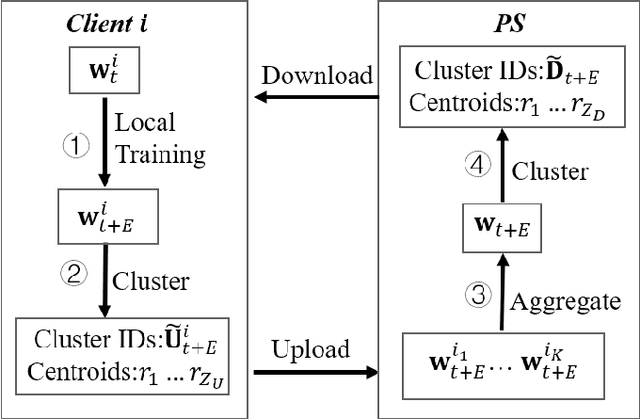
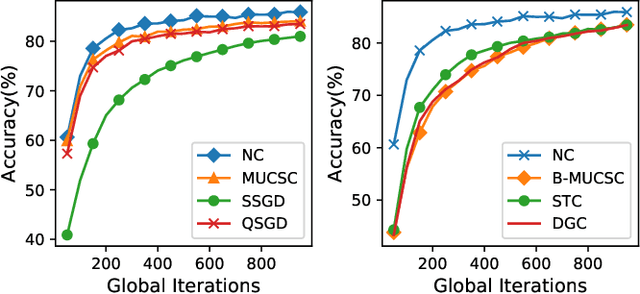

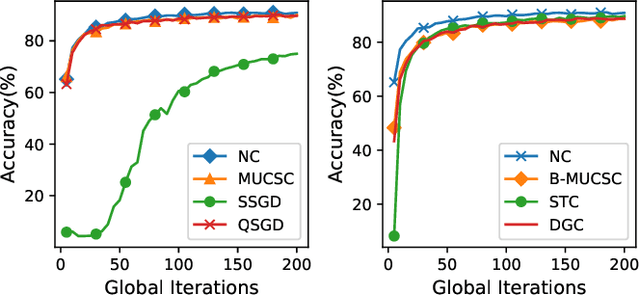
Federated Learning (FL) is an emerging decentralized learning framework through which multiple clients can collaboratively train a learning model. However, a major obstacle that impedes the wide deployment of FL lies in massive communication traffic. To train high dimensional machine learning models (such as CNN models), heavy communication traffic can be incurred by exchanging model updates via the Internet between clients and the parameter server (PS), implying that the network resource can be easily exhausted. Compressing model updates is an effective way to reduce the traffic amount. However, a flexible unbiased compression algorithm applicable for both uplink and downlink compression in FL is still absent from existing works. In this work, we devise the Model Update Compression by Soft Clustering (MUCSC) algorithm to compress model updates transmitted between clients and the PS. In MUCSC, it is only necessary to transmit cluster centroids and the cluster ID of each model update. Moreover, we prove that: 1) The compressed model updates are unbiased estimation of their original values so that the convergence rate by transmitting compressed model updates is unchanged; 2) MUCSC can guarantee that the influence of the compression error on the model accuracy is minimized. Then, we further propose the boosted MUCSC (B-MUCSC) algorithm, a biased compression algorithm that can achieve an extremely high compression rate by grouping insignificant model updates into a super cluster. B-MUCSC is suitable for scenarios with very scarce network resource. Ultimately, we conduct extensive experiments with the CIFAR-10 and FEMNIST datasets to demonstrate that our algorithms can not only substantially reduce the volume of communication traffic in FL, but also improve the training efficiency in practical networks.