 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Rate Adaption in Federated Learning with Compressed Communications
Paper and Code
Dec 13, 2021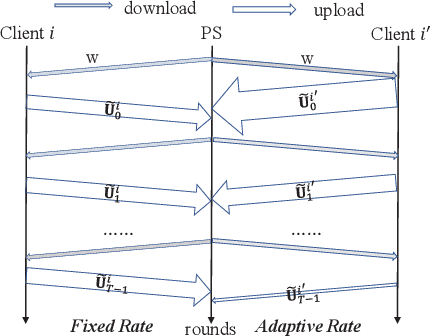
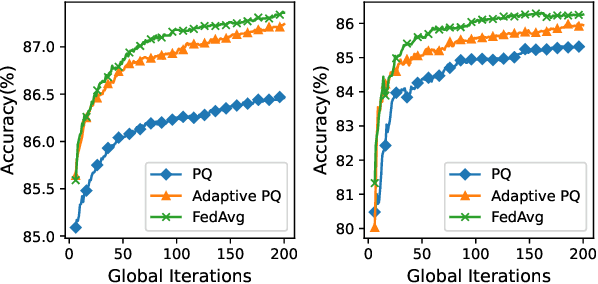
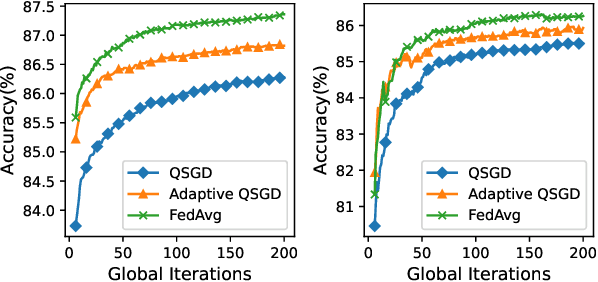
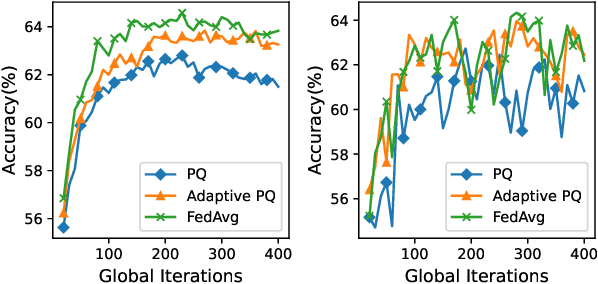
Federated Learning (FL) incurs high communication overhead, which can be greatly alleviated by compression for model updates. Yet the tradeoff between compression and model accuracy in the networked environment remains unclear and, for simplicity, most implementations adopt a fixed compression rate only. In this paper, we for the first time systematically examine this tradeoff, identifying the influence of the compression error on the final model accuracy with respect to the learning rate. Specifically, we factor the compression error of each global iteration into the convergence rate analysis under both strongly convex and non-convex loss functions. We then present an adaptation framework to maximize the final model accuracy by strategically adjusting the compression rate in each iteration. We have discussed the key implementation issues of our framework in practical networks with representative compression algorithms. Experiments over the popular MNIST and CIFAR-10 datasets confirm that our solution effectively reduces network traffic yet maintains high model accuracy in FL.