 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Augmentation: Score-Guided Pathological Prior for EEG-based Depression Detection
May 29, 2026Deep learning-based Major Depressive Disorder (MDD) detection using Electroencephalography (EEG) is fundamentally constrained by the "small-sample dilemma." Prevailing generative data augmentation methods not only incur heavy computational overhead but also risk introducing synthetic noise, thereby blurring classification boundaries. To challenge the traditional "data quantity first" convention, we propose a novel framework "Beyond Augmentation": Score-Guided Classification (SGC). SGC does not synthesize pseudo-samples; instead, it utilizes an unsupervised generative network architecture to model the structural and statistical anomaly degrees of samples, serving as the core "Pathological Prior". This prior, after robust normalization, is explicitly fused with deep feature representations, thereby precisely guiding the classifier's decision boundary. Furthermore, to dynamically adapt to varying channel configurations, we propose a Cross-Channel Spatial Adaptation module, utilizing a spatial mapping mechanism to effectively resolve the hardware heterogeneity of mismatched channels in multi-center datasets. Extensive experiments on the Mumtaz2016 and high-density MODMA datasets demonstrate the effectiveness and exceptional generalizability of our method under the challenging "zero data augmentation" setting and at "zero sample synthesis cost". Keywords: Electroencephalography (EEG), Depression Detection, Anomaly Score, Diffusion Models, Few-Shot Learning
CanonSLR: Canonical-View Guided Multi-View Continuous Sign Language Recognition
Apr 20, 2026Continuous Sign Language Recognition (CSLR) has achieved remarkable progress in recent years; however, most existing methods are developed under single-view settings and thus remain insufficiently robust to viewpoint variations in real-world scenarios. To address this limitation, we propose CanonSLR, a canonical-view guided framework for multi-view CSLR. Specifically, we introduce a frontal-view-anchored teacher-student learning strategy, in which a teacher network trained on frontal-view data provides canonical temporal supervision for a student network trained on all viewpoints. To further reduce cross-view semantic discrepancy, we propose Sequence-Level Soft-Target Distillation, which transfers structured temporal knowledge from the frontal view to non-frontal samples, thereby alleviating gloss boundary ambiguity and category confusion caused by occlusion and projection variation. In addition, we introduce Temporal Motion Relational Enhancement to explicitly model motion-aware temporal relations in high-level visual features, strengthening stable dynamic representations while suppressing viewpoint-sensitive appearance disturbances. To support multi-view CSLR research, we further develop a universal multi-view sign language data construction pipeline that transforms original single-view RGB videos into semantically consistent, temporally coherent, and viewpoint-controllable multi-view sign language videos. Based on this pipeline, we extend PHOENIX-2014T and CSL-Daily into two seven-view benchmarks, namely PT14-MV and CSL-MV, providing a new experimental foundation for multi-view CSLR. Extensive experiments on PT14-MV and CSL-MV demonstrate that CanonSLR consistently outperforms existing approaches under multi-view settings and exhibits stronger robustness, especially on challenging non-frontal views.
MaRCA: Multi-Agent Reinforcement Learning for Dynamic Computation Allocation in Large-Scale Recommender Systems
Dec 30, 2025Modern recommender systems face significant computational challenges due to growing model complexity and traffic scale, making efficient computation allocation critical for maximizing business revenue. Existing approaches typically simplify multi-stage computation resource allocation, neglecting inter-stage dependencies, thus limiting global optimality. In this paper, we propose MaRCA, a multi-agent reinforcement learning framework for end-to-end computation resource allocation in large-scale recommender systems. MaRCA models the stages of a recommender system as cooperative agents, using Centralized Training with Decentralized Execution (CTDE) to optimize revenue under computation resource constraints. We introduce an AutoBucket TestBench for accurate computation cost estimation, and a Model Predictive Control (MPC)-based Revenue-Cost Balancer to proactively forecast traffic loads and adjust the revenue-cost trade-off accordingly. Since its end-to-end deployment in the advertising pipeline of a leading global e-commerce platform in November 2024, MaRCA has consistently handled hundreds of billions of ad requests per day and has delivered a 16.67% revenue uplift using existing computation resources.
Moderating the Generalization of Score-based Generative Model
Dec 10, 2024



Score-based Generative Models (SGMs) have demonstrated remarkable generalization abilities, e.g. generating unseen, but natural data. However, the greater the generalization power, the more likely the unintended generalization, and the more dangerous the abuse. Research on moderated generalization in SGMs remains limited. To fill this gap, we first examine the current 'gold standard' in Machine Unlearning (MU), i.e., re-training the model after removing the undesirable training data, and find it does not work in SGMs. Further analysis of score functions reveals that the MU 'gold standard' does not alter the original score function, which explains its ineffectiveness. Based on this insight, we propose the first Moderated Score-based Generative Model (MSGM), which introduces a novel score adjustment strategy that redirects the score function away from undesirable data during the continuous-time stochastic differential equation process. Extensive experimental results demonstrate that MSGM significantly reduces the likelihood of generating undesirable content while preserving high visual quality for normal image generation. Albeit designed for SGMs, MSGM is a general and flexible MU framework that is compatible with diverse diffusion architectures (SGM and DDPM) and training strategies (re-training and fine-tuning), and enables zero-shot transfer of the pre-trained models to downstream tasks, e.g. image inpainting and reconstruction. The code will be shared upon acceptance.
Unlearnable Examples Give a False Sense of Security: Piercing through Unexploitable Data with Learnable Examples
May 23, 2023



Safeguarding data from unauthorized exploitation is vital for privacy and security, especially in recent rampant research in security breach such as adversarial/membership attacks. To this end, \textit{unlearnable examples} (UEs) have been recently proposed as a compelling protection, by adding imperceptible perturbation to data so that models trained on them cannot classify them accurately on original clean distribution. Unfortunately, we find UEs provide a false sense of security, because they cannot stop unauthorized users from utilizing other unprotected data to remove the protection, by turning unlearnable data into learnable again. Motivated by this observation, we formally define a new threat by introducing \textit{learnable unauthorized examples} (LEs) which are UEs with their protection removed. The core of this approach is a novel purification process that projects UEs onto the manifold of LEs. This is realized by a new joint-conditional diffusion model which denoises UEs conditioned on the pixel and perceptual similarity between UEs and LEs. Extensive experiments demonstrate that LE delivers state-of-the-art countering performance against both supervised UEs and unsupervised UEs in various scenarios, which is the first generalizable countermeasure to UEs across supervised learning and unsupervised learning.
Deep Hierarchy Quantization Compression algorithm based on Dynamic Sampling
Dec 30, 2022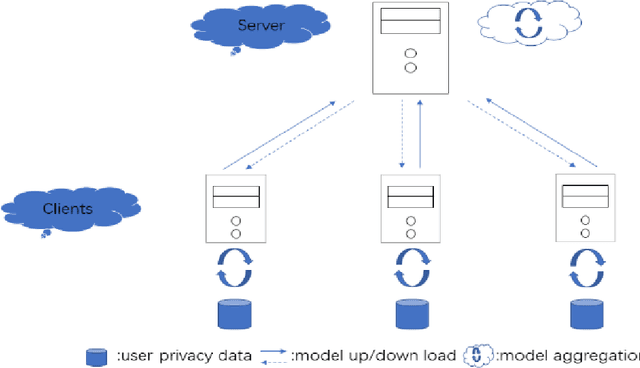
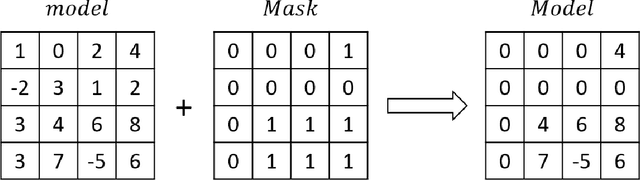
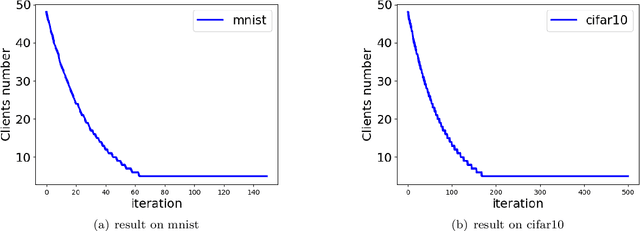
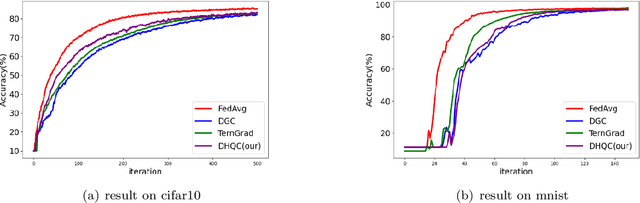
Unlike traditional distributed machine learning, federated learning stores data locally for training and then aggregates the models on the server, which solves the data security problem that may arise in traditional distributed machine learning. However, during the training process, the transmission of model parameters can impose a significant load on the network bandwidth. It has been pointed out that the vast majority of model parameters are redundant during model parameter transmission. In this paper, we explore the data distribution law of selected partial model parameters on this basis, and propose a deep hierarchical quantization compression algorithm, which further compresses the model and reduces the network load brought by data transmission through the hierarchical quantization of model parameters. And we adopt a dynamic sampling strategy for the selection of clients to accelerate the convergence of the model. Experimental results on different public datasets demonstrate the effectiveness of our algorithm.