 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving 2D Diffusion Models for 3D Medical Imaging with Inter-Slice Consistent Stochasticity
Feb 04, 20263D medical imaging is in high demand and essential for clinical diagnosis and scientific research. Currently, diffusion models (DMs) have become an effective tool for medical imaging reconstruction thanks to their ability to learn rich, high-quality data priors. However, learning the 3D data distribution with DMs in medical imaging is challenging, not only due to the difficulties in data collection but also because of the significant computational burden during model training. A common compromise is to train the DMs on 2D data priors and reconstruct stacked 2D slices to address 3D medical inverse problems. However, the intrinsic randomness of diffusion sampling causes severe inter-slice discontinuities of reconstructed 3D volumes. Existing methods often enforce continuity regularizations along the z-axis, which introduces sensitive hyper-parameters and may lead to over-smoothing results. In this work, we revisit the origin of stochasticity in diffusion sampling and introduce Inter-Slice Consistent Stochasticity (ISCS), a simple yet effective strategy that encourages interslice consistency during diffusion sampling. Our key idea is to control the consistency of stochastic noise components during diffusion sampling, thereby aligning their sampling trajectories without adding any new loss terms or optimization steps. Importantly, the proposed ISCS is plug-and-play and can be dropped into any 2D trained diffusion based 3D reconstruction pipeline without additional computational cost. Experiments on several medical imaging problems show that our method can effectively improve the performance of medical 3D imaging problems based on 2D diffusion models. Our findings suggest that controlling inter-slice stochasticity is a principled and practically attractive route toward high-fidelity 3D medical imaging with 2D diffusion priors. The code is available at: https://github.com/duchenhe/ISCS
Diffusion Model Regularized Implicit Neural Representation for CT Metal Artifact Reduction
Dec 09, 2025



Computed tomography (CT) images are often severely corrupted by artifacts in the presence of metals. Existing supervised metal artifact reduction (MAR) approaches suffer from performance instability on known data due to their reliance on limited paired metal-clean data, which limits their clinical applicability. Moreover, existing unsupervised methods face two main challenges: 1) the CT physical geometry is not effectively incorporated into the MAR process to ensure data fidelity; 2) traditional heuristics regularization terms cannot fully capture the abundant prior knowledge available. To overcome these shortcomings, we propose diffusion model regularized implicit neural representation framework for MAR. The implicit neural representation integrates physical constraints and imposes data fidelity, while the pre-trained diffusion model provides prior knowledge to regularize the solution. Experimental results on both simulated and clinical data demonstrate the effectiveness and generalization ability of our method, highlighting its potential to be applied to clinical settings.
Unsupervised Self-Prior Embedding Neural Representation for Iterative Sparse-View CT Reconstruction
Feb 08, 2025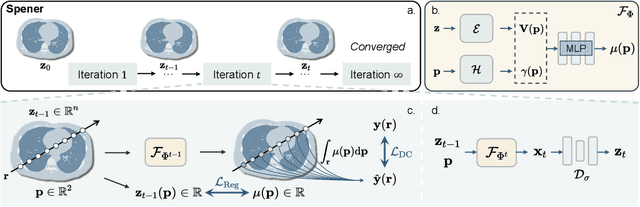
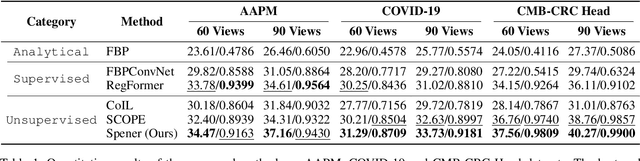
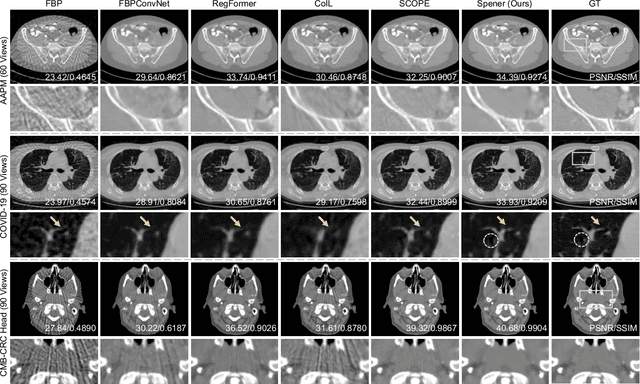
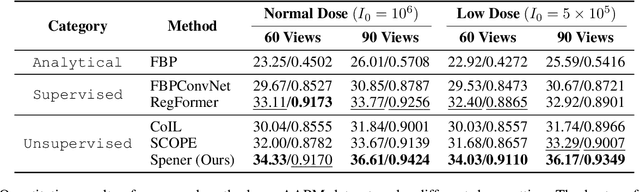
Emerging unsupervised implicit neural representation (INR) methods, such as NeRP, NeAT, and SCOPE, have shown great potential to address sparse-view computed tomography (SVCT) inverse problems. Although these INR-based methods perform well in relatively dense SVCT reconstructions, they struggle to achieve comparable performance to supervised methods in sparser SVCT scenarios. They are prone to being affected by noise, limiting their applicability in real clinical settings. Additionally, current methods have not fully explored the use of image domain priors for solving SVCsT inverse problems. In this work, we demonstrate that imperfect reconstruction results can provide effective image domain priors for INRs to enhance performance. To leverage this, we introduce Self-prior embedding neural representation (Spener), a novel unsupervised method for SVCT reconstruction that integrates iterative reconstruction algorithms. During each iteration, Spener extracts local image prior features from the previous iteration and embeds them to constrain the solution space. Experimental results on multiple CT datasets show that our unsupervised Spener method achieves performance comparable to supervised state-of-the-art (SOTA) methods on in-domain data while outperforming them on out-of-domain datasets. Moreover, Spener significantly improves the performance of INR-based methods in handling SVCT with noisy sinograms. Our code is available at https://github.com/MeijiTian/Spener.
Moner: Motion Correction in Undersampled Radial MRI with Unsupervised Neural Representation
Sep 25, 2024



Motion correction (MoCo) in radial MRI is a challenging problem due to the unpredictability of subject's motion. Current state-of-the-art (SOTA) MoCo algorithms often use extensive high-quality MR images to pre-train neural networks, obtaining excellent reconstructions. However, the need for large-scale datasets significantly increases costs and limits model generalization. In this work, we propose Moner, an unsupervised MoCo method that jointly solves artifact-free MR images and accurate motion from undersampled, rigid motion-corrupted k-space data, without requiring training data. Our core idea is to leverage the continuous prior of implicit neural representation (INR) to constrain this ill-posed inverse problem, enabling ideal solutions. Specifically, we incorporate a quasi-static motion model into the INR, granting its ability to correct subject's motion. To stabilize model optimization, we reformulate radial MRI as a back-projection problem using the Fourier-slice theorem. Additionally, we propose a novel coarse-to-fine hash encoding strategy, significantly enhancing MoCo accuracy. Experiments on multiple MRI datasets show our Moner achieves performance comparable to SOTA MoCo techniques on in-domain data, while demonstrating significant improvements on out-of-domain data.
Highly Accelerated MRI via Implicit Neural Representation Guided Posterior Sampling of Diffusion Models
Jul 03, 2024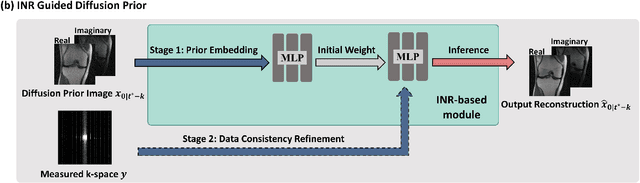
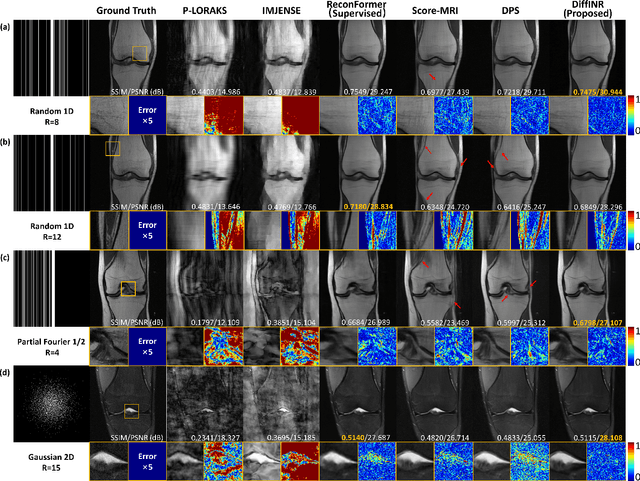
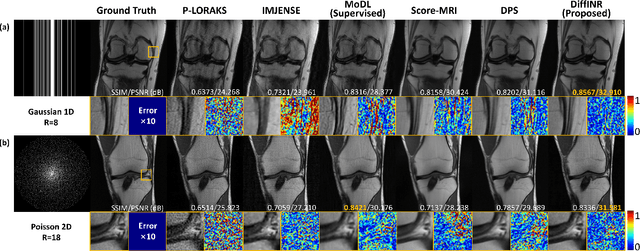
Reconstructing high-fidelity magnetic resonance (MR) images from under-sampled k-space is a commonly used strategy to reduce scan time. The posterior sampling of diffusion models based on the real measurement data holds significant promise of improved reconstruction accuracy. However, traditional posterior sampling methods often lack effective data consistency guidance, leading to inaccurate and unstable reconstructions. Implicit neural representation (INR) has emerged as a powerful paradigm for solving inverse problems by modeling a signal's attributes as a continuous function of spatial coordinates. In this study, we present a novel posterior sampler for diffusion models using INR, named DiffINR. The INR-based component incorporates both the diffusion prior distribution and the MRI physical model to ensure high data fidelity. DiffINR demonstrates superior performance on experimental datasets with remarkable accuracy, even under high acceleration factors (up to R=12 in single-channel reconstruction). Notably, our proposed framework can be a generalizable framework to solve inverse problems in other medical imaging tasks.
DPER: Diffusion Prior Driven Neural Representation for Limited Angle and Sparse View CT Reconstruction
Apr 27, 2024



Limited-angle and sparse-view computed tomography (LACT and SVCT) are crucial for expanding the scope of X-ray CT applications. However, they face challenges due to incomplete data acquisition, resulting in diverse artifacts in the reconstructed CT images. Emerging implicit neural representation (INR) techniques, such as NeRF, NeAT, and NeRP, have shown promise in under-determined CT imaging reconstruction tasks. However, the unsupervised nature of INR architecture imposes limited constraints on the solution space, particularly for the highly ill-posed reconstruction task posed by LACT and ultra-SVCT. In this study, we introduce the Diffusion Prior Driven Neural Representation (DPER), an advanced unsupervised framework designed to address the exceptionally ill-posed CT reconstruction inverse problems. DPER adopts the Half Quadratic Splitting (HQS) algorithm to decompose the inverse problem into data fidelity and distribution prior sub-problems. The two sub-problems are respectively addressed by INR reconstruction scheme and pre-trained score-based diffusion model. This combination initially preserves the implicit image local consistency prior from INR. Additionally, it effectively augments the feasibility of the solution space for the inverse problem through the generative diffusion model, resulting in increased stability and precision in the solutions. We conduct comprehensive experiments to evaluate the performance of DPER on LACT and ultra-SVCT reconstruction with two public datasets (AAPM and LIDC). The results show that our method outperforms the state-of-the-art reconstruction methods on in-domain datasets, while achieving significant performance improvements on out-of-domain datasets.