 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Region-Growing Network for Object Segmentation in Atmospheric Turbulence
Paper and Code
Nov 06, 2023

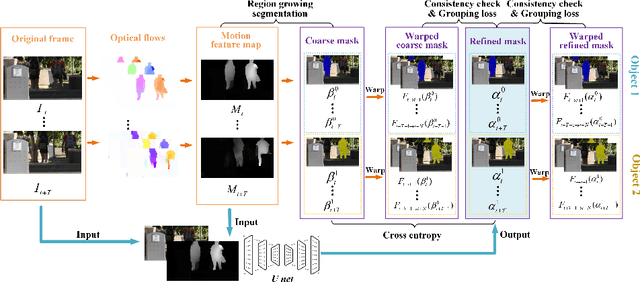
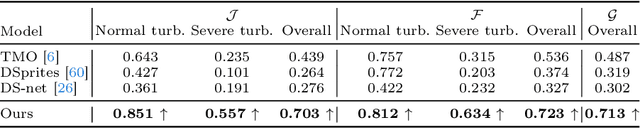
In this paper, we present a two-stage unsupervised foreground object segmentation network tailored for dynamic scenes affected by atmospheric turbulence. In the first stage, we utilize averaged optical flow from turbulence-distorted image sequences to feed a novel region-growing algorithm, crafting preliminary masks for each moving object in the video. In the second stage, we employ a U-Net architecture with consistency and grouping losses to further refine these masks optimizing their spatio-temporal alignment. Our approach does not require labeled training data and works across varied turbulence strengths for long-range video. Furthermore, we release the first moving object segmentation dataset of turbulence-affected videos, complete with manually annotated ground truth masks. Our method, evaluated on this new dataset, demonstrates superior segmentation accuracy and robustness as compared to current state-of-the-art unsupervised methods.