 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Regression with Conditional GANs
Apr 21, 2024Regression is typically treated as a curve-fitting process where the goal is to fit a prediction function to data. With the help of conditional generative adversarial networks, we propose to solve this age-old problem in a different way; we aim to learn a prediction function whose outputs, when paired with the corresponding inputs, are indistinguishable from feature-label pairs in the training dataset. We show that this approach to regression makes fewer assumptions on the distribution of the data we are fitting to and, therefore, has better representation capabilities. We draw parallels with generalized linear models in statistics and show how our proposal serves as an extension of them to neural networks. We demonstrate the superiority of this new approach to standard regression with experiments on multiple synthetic and publicly available real-world datasets, finding encouraging results, especially with real-world heavy-tailed regression datasets. To make our work more reproducible, we release our source code. Link to repository: https://anonymous.4open.science/r/regressGAN-7B71/
ABC: Adversarial Behavioral Cloning for Offline Mode-Seeking Imitation Learning
Nov 08, 2022Given a dataset of expert agent interactions with an environment of interest, a viable method to extract an effective agent policy is to estimate the maximum likelihood policy indicated by this data. This approach is commonly referred to as behavioral cloning (BC). In this work, we describe a key disadvantage of BC that arises due to the maximum likelihood objective function; namely that BC is mean-seeking with respect to the state-conditional expert action distribution when the learner's policy is represented with a Gaussian. To address this issue, we introduce a modified version of BC, Adversarial Behavioral Cloning (ABC), that exhibits mode-seeking behavior by incorporating elements of GAN (generative adversarial network) training. We evaluate ABC on toy domains and a domain based on Hopper from the DeepMind Control suite, and show that it outperforms standard BC by being mode-seeking in nature.
RAIL: A modular framework for Reinforcement-learning-based Adversarial Imitation Learning
May 08, 2021



While Adversarial Imitation Learning (AIL) algorithms have recently led to state-of-the-art results on various imitation learning benchmarks, it is unclear as to what impact various design decisions have on performance. To this end, we present here an organizing, modular framework called Reinforcement-learning-based Adversarial Imitation Learning (RAIL) that encompasses and generalizes a popular subclass of existing AIL approaches. Using the view espoused by RAIL, we create two new IfO (Imitation from Observation) algorithms, which we term SAIfO: SAC-based Adversarial Imitation from Observation and SILEM (Skeletal Feature Compensation for Imitation Learning with Embodiment Mismatch). We go into greater depth about SILEM in a separate technical report. In this paper, we focus on SAIfO, evaluating it on a suite of locomotion tasks from OpenAI Gym, and showing that it outperforms contemporaneous RAIL algorithms that perform IfO.
Skeletal Feature Compensation for Imitation Learning with Embodiment Mismatch
Apr 15, 2021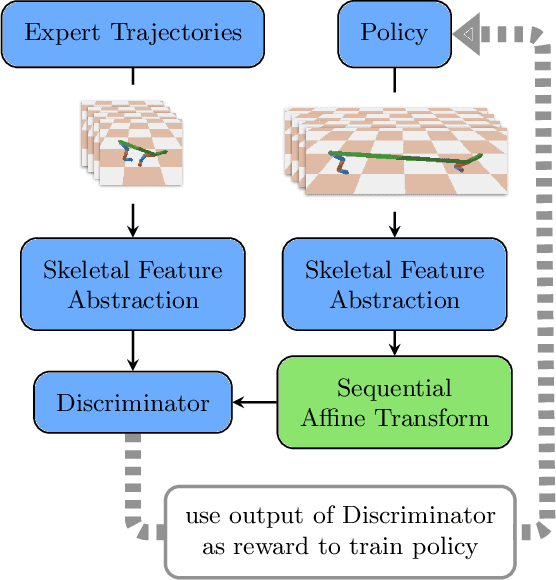

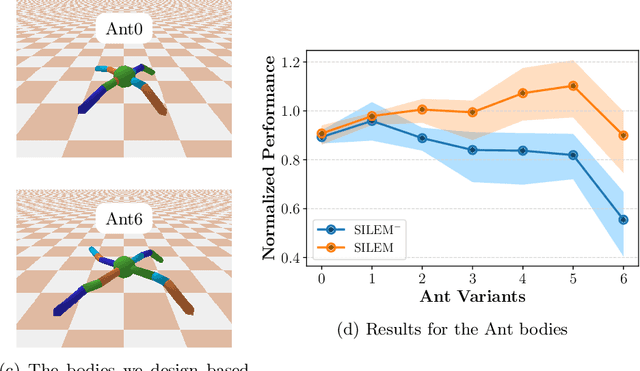
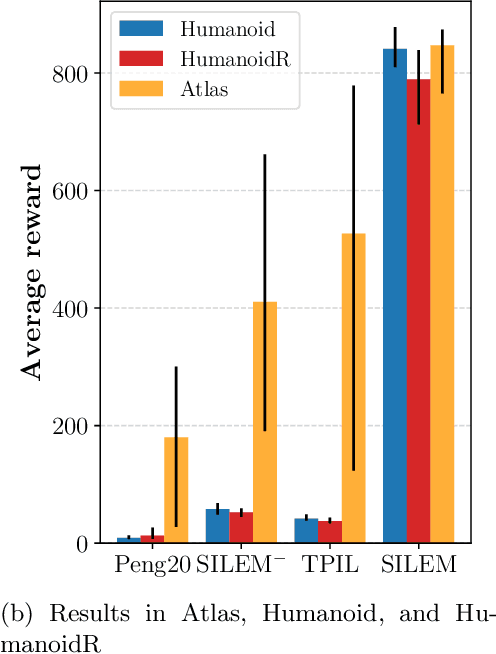
Learning from demonstrations in the wild (e.g. YouTube videos) is a tantalizing goal in imitation learning. However, for this goal to be achieved, imitation learning algorithms must deal with the fact that the demonstrators and learners may have bodies that differ from one another. This condition -- "embodiment mismatch" -- is ignored by many recent imitation learning algorithms. Our proposed imitation learning technique, SILEM (\textbf{S}keletal feature compensation for \textbf{I}mitation \textbf{L}earning with \textbf{E}mbodiment \textbf{M}ismatch), addresses a particular type of embodiment mismatch by introducing a learned affine transform to compensate for differences in the skeletal features obtained from the learner and expert. We create toy domains based on PyBullet's HalfCheetah and Ant to assess SILEM's benefits for this type of embodiment mismatch. We also provide qualitative and quantitative results on more realistic problems -- teaching simulated humanoid agents, including Atlas from Boston Dynamics, to walk by observing human demonstrations.