 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Differences in Strategic Behavior Between Humans and LLMs
Feb 10, 2026As Large Language Models (LLMs) are increasingly deployed in social and strategic scenarios, it becomes critical to understand where and why their behavior diverges from that of humans. While behavioral game theory (BGT) provides a framework for analyzing behavior, existing models do not fully capture the idiosyncratic behavior of humans or black-box, non-human agents like LLMs. We employ AlphaEvolve, a cutting-edge program discovery tool, to directly discover interpretable models of human and LLM behavior from data, thereby enabling open-ended discovery of structural factors driving human and LLM behavior. Our analysis on iterated rock-paper-scissors reveals that frontier LLMs can be capable of deeper strategic behavior than humans. These results provide a foundation for understanding structural differences driving differences in human and LLM behavior in strategic interactions.
ROTATE: Regret-driven Open-ended Training for Ad Hoc Teamwork
May 29, 2025Developing AI agents capable of collaborating with previously unseen partners is a fundamental generalization challenge in multi-agent learning, known as Ad Hoc Teamwork (AHT). Existing AHT approaches typically adopt a two-stage pipeline, where first, a fixed population of teammates is generated with the idea that they should be representative of the teammates that will be seen at deployment time, and second, an AHT agent is trained to collaborate well with agents in the population. To date, the research community has focused on designing separate algorithms for each stage. This separation has led to algorithms that generate teammate pools with limited coverage of possible behaviors, and that ignore whether the generated teammates are easy to learn from for the AHT agent. Furthermore, algorithms for training AHT agents typically treat the set of training teammates as static, thus attempting to generalize to previously unseen partner agents without assuming any control over the distribution of training teammates. In this paper, we present a unified framework for AHT by reformulating the problem as an open-ended learning process between an ad hoc agent and an adversarial teammate generator. We introduce ROTATE, a regret-driven, open-ended training algorithm that alternates between improving the AHT agent and generating teammates that probe its deficiencies. Extensive experiments across diverse AHT environments demonstrate that ROTATE significantly outperforms baselines at generalizing to an unseen set of evaluation teammates, thus establishing a new standard for robust and generalizable teamwork.
N-Agent Ad Hoc Teamwork
Apr 16, 2024Current approaches to learning cooperative behaviors in multi-agent settings assume relatively restrictive settings. In standard fully cooperative multi-agent reinforcement learning, the learning algorithm controls \textit{all} agents in the scenario, while in ad hoc teamwork, the learning algorithm usually assumes control over only a $\textit{single}$ agent in the scenario. However, many cooperative settings in the real world are much less restrictive. For example, in an autonomous driving scenario, a company might train its cars with the same learning algorithm, yet once on the road, these cars must cooperate with cars from another company. Towards generalizing the class of scenarios that cooperative learning methods can address, we introduce $N$-agent ad hoc teamwork, in which a set of autonomous agents must interact and cooperate with dynamically varying numbers and types of teammates at evaluation time. This paper formalizes the problem, and proposes the $\textit{Policy Optimization with Agent Modelling}$ (POAM) algorithm. POAM is a policy gradient, multi-agent reinforcement learning approach to the NAHT problem, that enables adaptation to diverse teammate behaviors by learning representations of teammate behaviors. Empirical evaluation on StarCraft II tasks shows that POAM improves cooperative task returns compared to baseline approaches, and enables out-of-distribution generalization to unseen teammates.
Building Minimal and Reusable Causal State Abstractions for Reinforcement Learning
Jan 23, 2024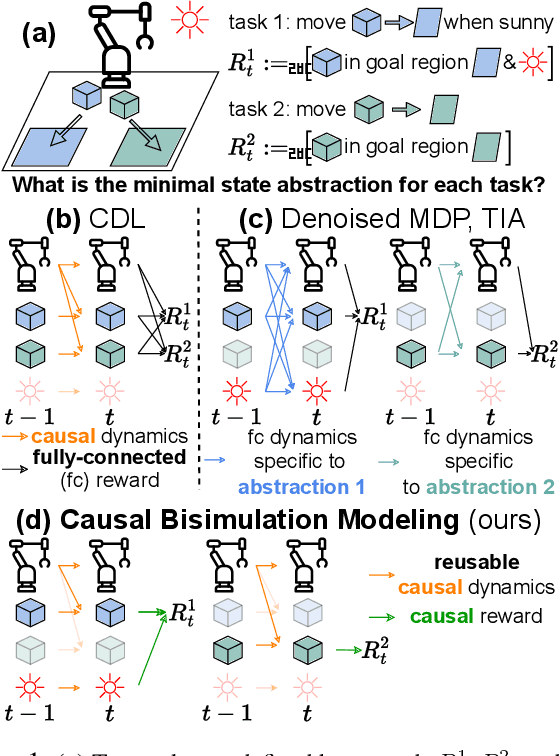

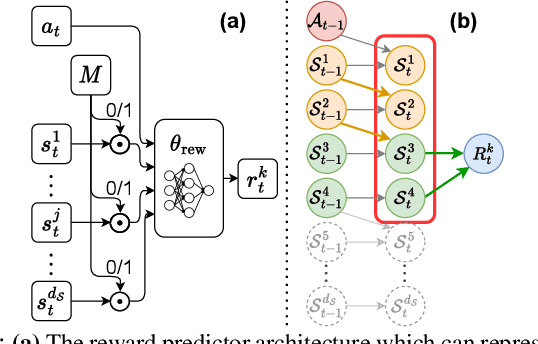
Two desiderata of reinforcement learning (RL) algorithms are the ability to learn from relatively little experience and the ability to learn policies that generalize to a range of problem specifications. In factored state spaces, one approach towards achieving both goals is to learn state abstractions, which only keep the necessary variables for learning the tasks at hand. This paper introduces Causal Bisimulation Modeling (CBM), a method that learns the causal relationships in the dynamics and reward functions for each task to derive a minimal, task-specific abstraction. CBM leverages and improves implicit modeling to train a high-fidelity causal dynamics model that can be reused for all tasks in the same environment. Empirical validation on manipulation environments and Deepmind Control Suite reveals that CBM's learned implicit dynamics models identify the underlying causal relationships and state abstractions more accurately than explicit ones. Furthermore, the derived state abstractions allow a task learner to achieve near-oracle levels of sample efficiency and outperform baselines on all tasks.
D-Shape: Demonstration-Shaped Reinforcement Learning via Goal Conditioning
Oct 26, 2022
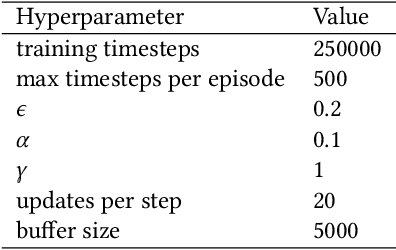
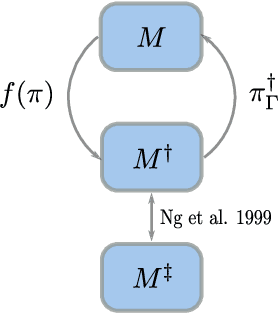
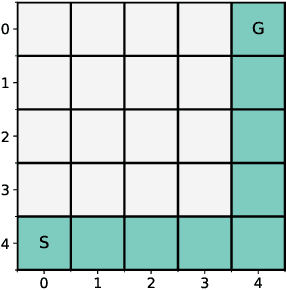
While combining imitation learning (IL) and reinforcement learning (RL) is a promising way to address poor sample efficiency in autonomous behavior acquisition, methods that do so typically assume that the requisite behavior demonstrations are provided by an expert that behaves optimally with respect to a task reward. If, however, suboptimal demonstrations are provided, a fundamental challenge appears in that the demonstration-matching objective of IL conflicts with the return-maximization objective of RL. This paper introduces D-Shape, a new method for combining IL and RL that uses ideas from reward shaping and goal-conditioned RL to resolve the above conflict. D-Shape allows learning from suboptimal demonstrations while retaining the ability to find the optimal policy with respect to the task reward. We experimentally validate D-Shape in sparse-reward gridworld domains, showing that it both improves over RL in terms of sample efficiency and converges consistently to the optimal policy in the presence of suboptimal demonstrations.
DM$^2$: Distributed Multi-Agent Reinforcement Learning for Distribution Matching
Jun 01, 2022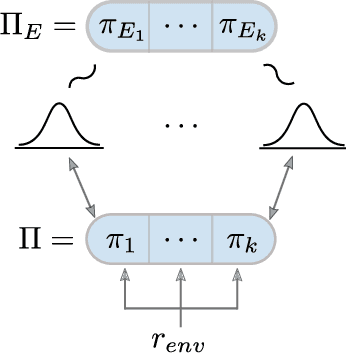

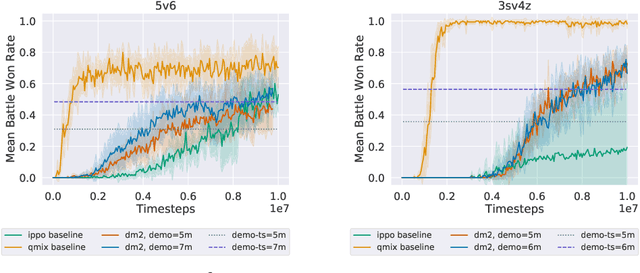
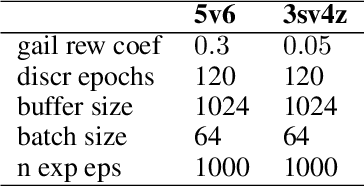
Current approaches to multi-agent cooperation rely heavily on centralized mechanisms or explicit communication protocols to ensure convergence. This paper studies the problem of distributed multi-agent learning without resorting to explicit coordination schemes. The proposed algorithm (DM$^2$) leverages distribution matching to facilitate independent agents' coordination. Each individual agent matches a target distribution of concurrently sampled trajectories from a joint expert policy. The theoretical analysis shows that under some conditions, if each agent optimizes their individual distribution matching objective, the agents increase a lower bound on the objective of matching the joint expert policy, allowing convergence to the joint expert policy. Further, if the distribution matching objective is aligned with a joint task, a combination of environment reward and distribution matching reward leads to the same equilibrium. Experimental validation on the StarCraft domain shows that combining the reward for distribution matching with the environment reward allows agents to outperform a fully distributed baseline. Additional experiments probe the conditions under which expert demonstrations need to be sampled in order to outperform the fully distributed baseline.
In Pursuit of Interpretable, Fair and Accurate Machine Learning for Criminal Recidivism Prediction
May 08, 2020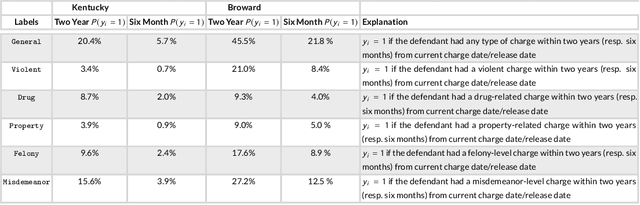

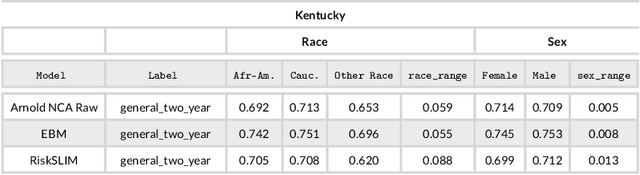
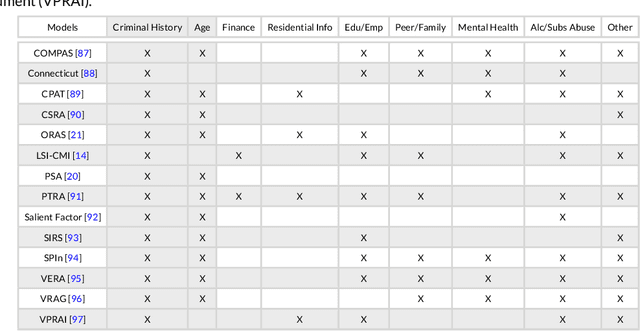
In recent years, academics and investigative journalists have criticized certain commercial risk assessments for their black-box nature and failure to satisfy competing notions of fairness. Since then, the field of interpretable machine learning has created simple yet effective algorithms, while the field of fair machine learning has proposed various mathematical definitions of fairness. However, studies from these fields are largely independent, despite the fact that many applications of machine learning to social issues require both fairness and interpretability. We explore the intersection by revisiting the recidivism prediction problem using state-of-the-art tools from interpretable machine learning, and assessing the models for performance, interpretability, and fairness. Unlike previous works, we compare against two existing risk assessments (COMPAS and the Arnold Public Safety Assessment) and train models that output probabilities rather than binary predictions. We present multiple models that beat these risk assessments in performance, and provide a fairness analysis of these models. Our results imply that machine learning models should be trained separately for separate locations, and updated over time.