 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Pursuit of Interpretable, Fair and Accurate Machine Learning for Criminal Recidivism Prediction
Paper and Code
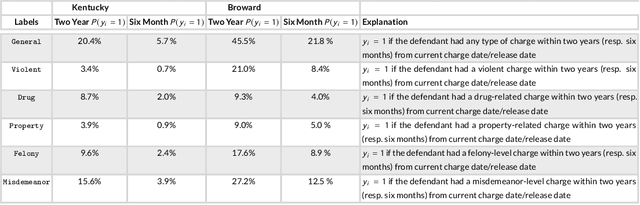

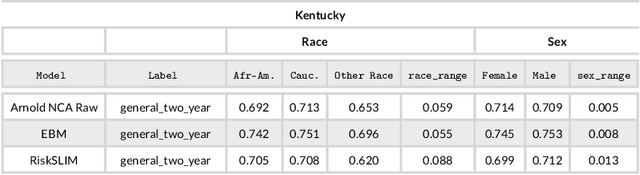
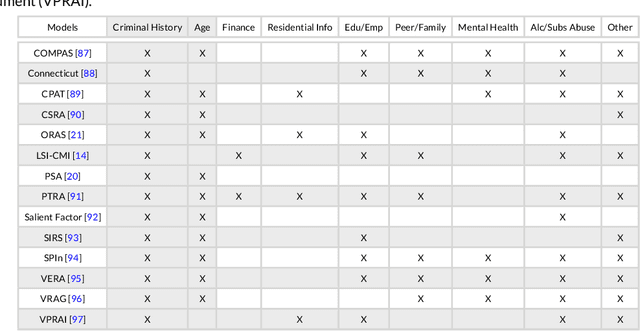
In recent years, academics and investigative journalists have criticized certain commercial risk assessments for their black-box nature and failure to satisfy competing notions of fairness. Since then, the field of interpretable machine learning has created simple yet effective algorithms, while the field of fair machine learning has proposed various mathematical definitions of fairness. However, studies from these fields are largely independent, despite the fact that many applications of machine learning to social issues require both fairness and interpretability. We explore the intersection by revisiting the recidivism prediction problem using state-of-the-art tools from interpretable machine learning, and assessing the models for performance, interpretability, and fairness. Unlike previous works, we compare against two existing risk assessments (COMPAS and the Arnold Public Safety Assessment) and train models that output probabilities rather than binary predictions. We present multiple models that beat these risk assessments in performance, and provide a fairness analysis of these models. Our results imply that machine learning models should be trained separately for separate locations, and updated over time.