 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern-Based Time-Series Risk Scoring for Anomaly Detection and Alert Filtering -- A Predictive Maintenance Case Study
May 24, 2024Fault detection is a key challenge in the management of complex systems. In the context of SparkCognition's efforts towards predictive maintenance in large scale industrial systems, this problem is often framed in terms of anomaly detection - identifying patterns of behavior in the data which deviate from normal. Patterns of normal behavior aren't captured simply in the coarse statistics of measured signals. Rather, the multivariate sequential pattern itself can be indicative of normal vs. abnormal behavior. For this reason, normal behavior modeling that relies on snapshots of the data without taking into account temporal relationships as they evolve would be lacking. However, common strategies for dealing with temporal dependence, such as Recurrent Neural Networks or attention mechanisms are oftentimes computationally expensive and difficult to train. In this paper, we propose a fast and efficient approach to anomaly detection and alert filtering based on sequential pattern similarities. In our empirical analysis section, we show how this approach can be leveraged for a variety of purposes involving anomaly detection on a large scale real-world industrial system. Subsequently, we test our approach on a publicly-available dataset in order to establish its general applicability and robustness compared to a state-of-the-art baseline. We also demonstrate an efficient way of optimizing the framework based on an alert recall objective function.
N-Agent Ad Hoc Teamwork
Apr 16, 2024Current approaches to learning cooperative behaviors in multi-agent settings assume relatively restrictive settings. In standard fully cooperative multi-agent reinforcement learning, the learning algorithm controls \textit{all} agents in the scenario, while in ad hoc teamwork, the learning algorithm usually assumes control over only a $\textit{single}$ agent in the scenario. However, many cooperative settings in the real world are much less restrictive. For example, in an autonomous driving scenario, a company might train its cars with the same learning algorithm, yet once on the road, these cars must cooperate with cars from another company. Towards generalizing the class of scenarios that cooperative learning methods can address, we introduce $N$-agent ad hoc teamwork, in which a set of autonomous agents must interact and cooperate with dynamically varying numbers and types of teammates at evaluation time. This paper formalizes the problem, and proposes the $\textit{Policy Optimization with Agent Modelling}$ (POAM) algorithm. POAM is a policy gradient, multi-agent reinforcement learning approach to the NAHT problem, that enables adaptation to diverse teammate behaviors by learning representations of teammate behaviors. Empirical evaluation on StarCraft II tasks shows that POAM improves cooperative task returns compared to baseline approaches, and enables out-of-distribution generalization to unseen teammates.
Utilizing Mood-Inducing Background Music in Human-Robot Interaction
Aug 28, 2023



Past research has clearly established that music can affect mood and that mood affects emotional and cognitive processing, and thus decision-making. It follows that if a robot interacting with a person needs to predict the person's behavior, knowledge of the music the person is listening to when acting is a potentially relevant feature. To date, however, there has not been any concrete evidence that a robot can improve its human-interactive decision-making by taking into account what the person is listening to. This research fills this gap by reporting the results of an experiment in which human participants were required to complete a task in the presence of an autonomous agent while listening to background music. Specifically, the participants drove a simulated car through an intersection while listening to music. The intersection was not empty, as another simulated vehicle, controlled autonomously, was also crossing the intersection in a different direction. Our results clearly indicate that such background information can be effectively incorporated in an agent's world representation in order to better predict people's behavior. We subsequently analyze how knowledge of music impacted both participant behavior and the resulting learned policy.\setcounter{footnote}{2}\footnote{An earlier version of part of the material in this paper appeared originally in the first author's Ph.D. Dissertation~\cite{liebman2020sequential} but it has not appeared in any pear-reviewed conference or journal.}
DM$^2$: Distributed Multi-Agent Reinforcement Learning for Distribution Matching
Jun 01, 2022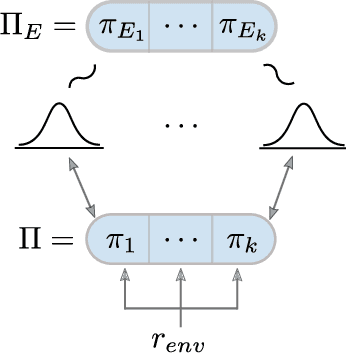

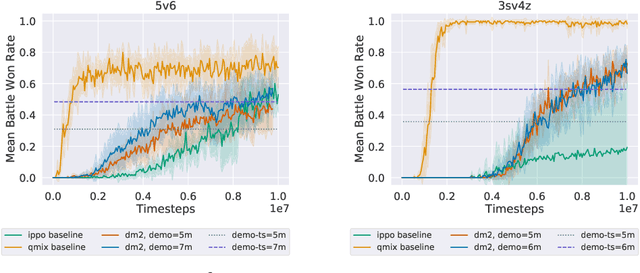
Current approaches to multi-agent cooperation rely heavily on centralized mechanisms or explicit communication protocols to ensure convergence. This paper studies the problem of distributed multi-agent learning without resorting to explicit coordination schemes. The proposed algorithm (DM$^2$) leverages distribution matching to facilitate independent agents' coordination. Each individual agent matches a target distribution of concurrently sampled trajectories from a joint expert policy. The theoretical analysis shows that under some conditions, if each agent optimizes their individual distribution matching objective, the agents increase a lower bound on the objective of matching the joint expert policy, allowing convergence to the joint expert policy. Further, if the distribution matching objective is aligned with a joint task, a combination of environment reward and distribution matching reward leads to the same equilibrium. Experimental validation on the StarCraft domain shows that combining the reward for distribution matching with the environment reward allows agents to outperform a fully distributed baseline. Additional experiments probe the conditions under which expert demonstrations need to be sampled in order to outperform the fully distributed baseline.
Artificial Musical Intelligence: A Survey
Jun 17, 2020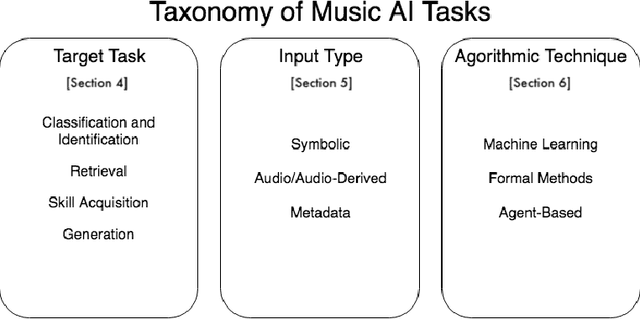

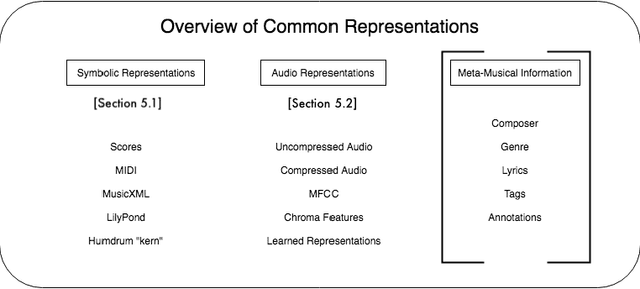

Computers have been used to analyze and create music since they were first introduced in the 1950s and 1960s. Beginning in the late 1990s, the rise of the Internet and large scale platforms for music recommendation and retrieval have made music an increasingly prevalent domain of machine learning and artificial intelligence research. While still nascent, several different approaches have been employed to tackle what may broadly be referred to as "musical intelligence." This article provides a definition of musical intelligence, introduces a taxonomy of its constituent components, and surveys the wide range of AI methods that can be, and have been, brought to bear in its pursuit, with a particular emphasis on machine learning methods.
Representative Selection in Non Metric Datasets
Jun 19, 2015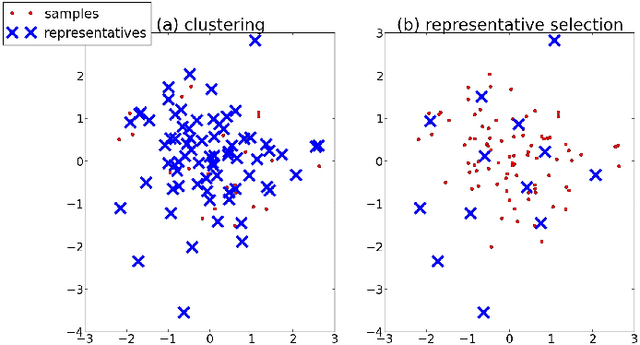
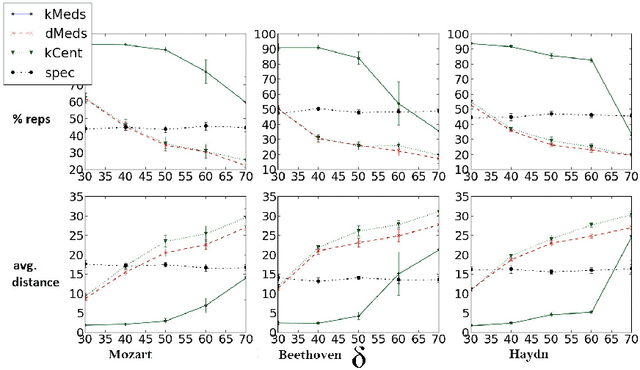
This paper considers the problem of representative selection: choosing a subset of data points from a dataset that best represents its overall set of elements. This subset needs to inherently reflect the type of information contained in the entire set, while minimizing redundancy. For such purposes, clustering may seem like a natural approach. However, existing clustering methods are not ideally suited for representative selection, especially when dealing with non-metric data, where only a pairwise similarity measure exists. In this paper we propose $\delta$-medoids, a novel approach that can be viewed as an extension to the $k$-medoids algorithm and is specifically suited for sample representative selection from non-metric data. We empirically validate $\delta$-medoids in two domains, namely music analysis and motion analysis. We also show some theoretical bounds on the performance of $\delta$-medoids and the hardness of representative selection in general.
DJ-MC: A Reinforcement-Learning Agent for Music Playlist Recommendation
Mar 25, 2015
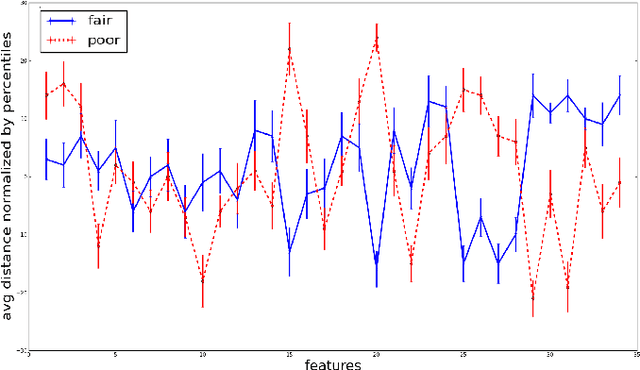
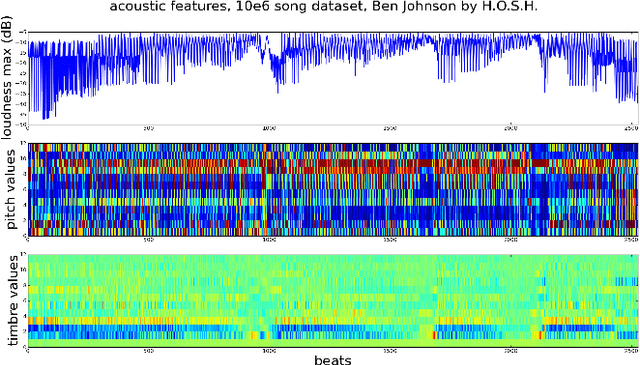
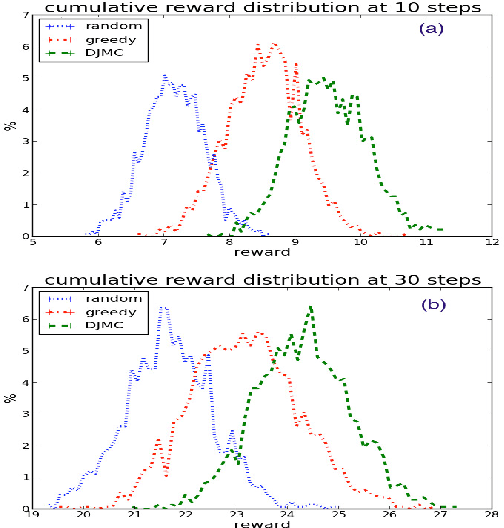
In recent years, there has been growing focus on the study of automated recommender systems. Music recommendation systems serve as a prominent domain for such works, both from an academic and a commercial perspective. A fundamental aspect of music perception is that music is experienced in temporal context and in sequence. In this work we present DJ-MC, a novel reinforcement-learning framework for music recommendation that does not recommend songs individually but rather song sequences, or playlists, based on a model of preferences for both songs and song transitions. The model is learned online and is uniquely adapted for each listener. To reduce exploration time, DJ-MC exploits user feedback to initialize a model, which it subsequently updates by reinforcement. We evaluate our framework with human participants using both real song and playlist data. Our results indicate that DJ-MC's ability to recommend sequences of songs provides a significant improvement over more straightforward approaches, which do not take transitions into account.