 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling Unbounded State Spaces in Continuing Task Reinforcement Learning
Paper and Code
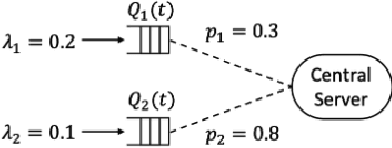
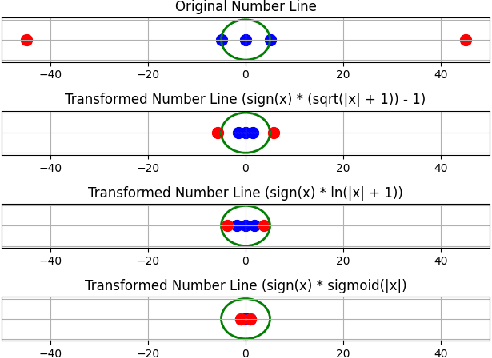
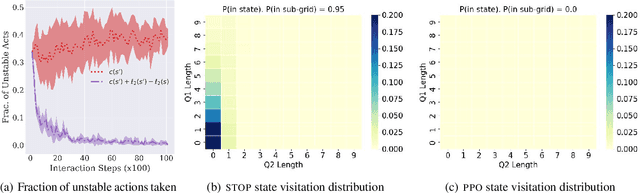
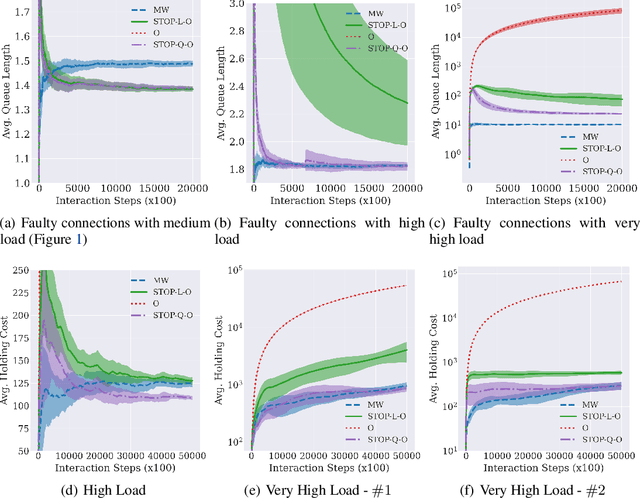
While deep reinforcement learning (RL) algorithms have been successfully applied to many tasks, their inability to extrapolate and strong reliance on episodic resets inhibits their applicability to many real-world settings. For instance, in stochastic queueing problems, the state space can be unbounded and the agent may have to learn online without the system ever being reset to states the agent has seen before. In such settings, we show that deep RL agents can diverge into unseen states from which they can never recover due to the lack of resets, especially in highly stochastic environments. Towards overcoming this divergence, we introduce a Lyapunov-inspired reward shaping approach that encourages the agent to first learn to be stable (i.e. to achieve bounded cost) and then to learn to be optimal. We theoretically show that our reward shaping technique reduces the rate of divergence of the agent and empirically find that it prevents it. We further combine our reward shaping approach with a weight annealing scheme that gradually introduces optimality and log-transform of state inputs, and find that these techniques enable deep RL algorithms to learn high performing policies when learning online in unbounded state space domains.