 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Multi-Task Reinforcement Learning via Adaptive Task Sampling
May 14, 2026Multi-task reinforcement learning (MTRL) aims to train a single agent to efficiently optimize performance across multiple tasks simultaneously. However, jointly optimizing all tasks often yields imbalanced learning: agents quickly solve easy tasks but learn slowly on harder ones. While prior work primarily attributes this imbalance to conflicting task gradients and proposes gradient manipulation or specialized architectures to address it, we instead focus on a distinct and under-explored challenge: imbalanced data allocation. Standard MTRL allocates an equal number of environment interactions to each task, which over-allocates data to easy tasks that require relatively few interactions to solve and under-allocates data to hard tasks that require substantially more experience to solve. To address this challenge, we introduce Distributionally Robust Adaptive Task Sampling (DRATS), an algorithm that adaptively prioritizes sampling tasks furthest from being solved. We derive DRATS by formalizing MTRL as a feasibility problem from which we derive a minimax objective for minimizing the worst-case return gap, the difference between a desired target return and the agent's return on a task. In benchmarks like MetaWorld-MT10 and MT50, DRATS improves data efficiency and increases worst-task performance compared to existing task sampling algorithms.
On-Policy Policy Gradient Reinforcement Learning Without On-Policy Sampling
Nov 14, 2023On-policy reinforcement learning (RL) algorithms perform policy updates using i.i.d. trajectories collected by the current policy. However, after observing only a finite number of trajectories, on-policy sampling may produce data that fails to match the expected on-policy data distribution. This sampling error leads to noisy updates and data inefficient on-policy learning. Recent work in the policy evaluation setting has shown that non-i.i.d., off-policy sampling can produce data with lower sampling error than on-policy sampling can produce. Motivated by this observation, we introduce an adaptive, off-policy sampling method to improve the data efficiency of on-policy policy gradient algorithms. Our method, Proximal Robust On-Policy Sampling (PROPS), reduces sampling error by collecting data with a behavior policy that increases the probability of sampling actions that are under-sampled with respect to the current policy. Rather than discarding data from old policies -- as is commonly done in on-policy algorithms -- PROPS uses data collection to adjust the distribution of previously collected data to be approximately on-policy. We empirically evaluate PROPS on both continuous-action MuJoCo benchmark tasks as well as discrete-action tasks and demonstrate that (1) PROPS decreases sampling error throughout training and (2) improves the data efficiency of on-policy policy gradient algorithms. Our work improves the RL community's understanding of a nuance in the on-policy vs off-policy dichotomy: on-policy learning requires on-policy data, not on-policy sampling.
Guided Data Augmentation for Offline Reinforcement Learning and Imitation Learning
Oct 27, 2023



Learning from demonstration (LfD) is a popular technique that uses expert demonstrations to learn robot control policies. However, the difficulty in acquiring expert-quality demonstrations limits the applicability of LfD methods: real-world data collection is often costly, and the quality of the demonstrations depends greatly on the demonstrator's abilities and safety concerns. A number of works have leveraged data augmentation (DA) to inexpensively generate additional demonstration data, but most DA works generate augmented data in a random fashion and ultimately produce highly suboptimal data. In this work, we propose Guided Data Augmentation (GuDA), a human-guided DA framework that generates expert-quality augmented data. The key insight of GuDA is that while it may be difficult to demonstrate the sequence of actions required to produce expert data, a user can often easily identify when an augmented trajectory segment represents task progress. Thus, the user can impose a series of simple rules on the DA process to automatically generate augmented samples that approximate expert behavior. To extract a policy from GuDA, we use off-the-shelf offline reinforcement learning and behavior cloning algorithms. We evaluate GuDA on a physical robot soccer task as well as simulated D4RL navigation tasks, a simulated autonomous driving task, and a simulated soccer task. Empirically, we find that GuDA enables learning from a small set of potentially suboptimal demonstrations and substantially outperforms a DA strategy that samples augmented data randomly.
Understanding when Dynamics-Invariant Data Augmentations Benefit Model-Free Reinforcement Learning Updates
Oct 26, 2023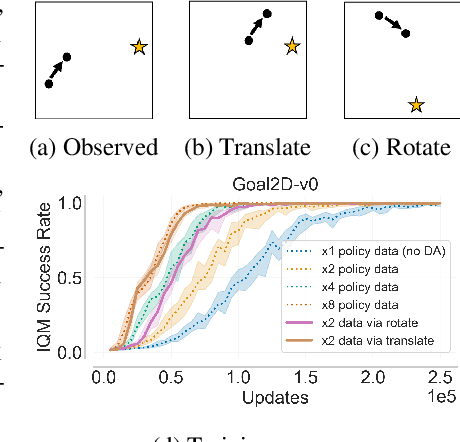


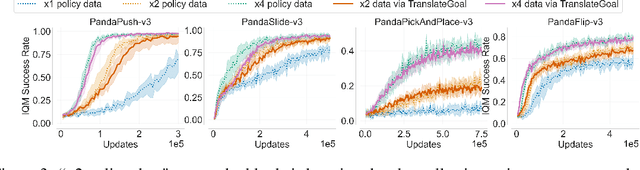
Recently, data augmentation (DA) has emerged as a method for leveraging domain knowledge to inexpensively generate additional data in reinforcement learning (RL) tasks, often yielding substantial improvements in data efficiency. While prior work has demonstrated the utility of incorporating augmented data directly into model-free RL updates, it is not well-understood when a particular DA strategy will improve data efficiency. In this paper, we seek to identify general aspects of DA responsible for observed learning improvements. Our study focuses on sparse-reward tasks with dynamics-invariant data augmentation functions, serving as an initial step towards a more general understanding of DA and its integration into RL training. Experimentally, we isolate three relevant aspects of DA: state-action coverage, reward density, and the number of augmented transitions generated per update (the augmented replay ratio). From our experiments, we draw two conclusions: (1) increasing state-action coverage often has a much greater impact on data efficiency than increasing reward density, and (2) decreasing the augmented replay ratio substantially improves data efficiency. In fact, certain tasks in our empirical study are solvable only when the replay ratio is sufficiently low.