 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding when Dynamics-Invariant Data Augmentations Benefit Model-Free Reinforcement Learning Updates
Paper and Code
Oct 26, 2023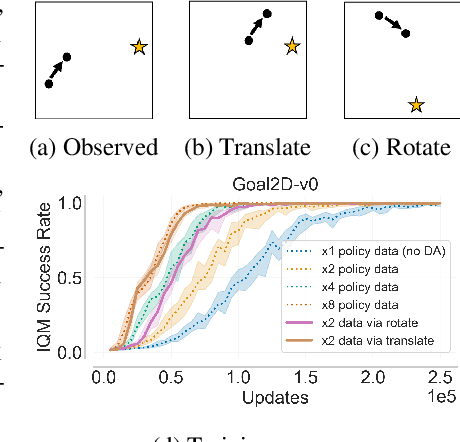


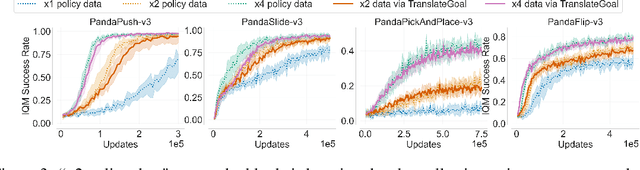
Recently, data augmentation (DA) has emerged as a method for leveraging domain knowledge to inexpensively generate additional data in reinforcement learning (RL) tasks, often yielding substantial improvements in data efficiency. While prior work has demonstrated the utility of incorporating augmented data directly into model-free RL updates, it is not well-understood when a particular DA strategy will improve data efficiency. In this paper, we seek to identify general aspects of DA responsible for observed learning improvements. Our study focuses on sparse-reward tasks with dynamics-invariant data augmentation functions, serving as an initial step towards a more general understanding of DA and its integration into RL training. Experimentally, we isolate three relevant aspects of DA: state-action coverage, reward density, and the number of augmented transitions generated per update (the augmented replay ratio). From our experiments, we draw two conclusions: (1) increasing state-action coverage often has a much greater impact on data efficiency than increasing reward density, and (2) decreasing the augmented replay ratio substantially improves data efficiency. In fact, certain tasks in our empirical study are solvable only when the replay ratio is sufficiently low.