 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGumbel-BEARD: Automatic Layer Selection for Self-Supervised Adaptation of Whisper in Low-Resource Domains
Jun 09, 2026Speech foundation models often struggle in low-resource domains due to domain mismatch and data scarcity. We propose Gumbel-BEARD, a domain adaptation framework that automates Whisper encoder layer selection via an end-to-end trainable hard Gumbel-Softmax selector. It enables self-supervised adaptation with a BEST-RQ objective that dynamically adapts to target acoustic characteristics without manual tuning. Experiments on the MyST child speech corpus demonstrate efficiency and scalability: with 10 h of labeled data for fine-tuning, our method matches a fully supervised baseline trained on the complete 133 h labeled set. We establish new state-of-the-art word error rates (WERs) of 8.21% using Whisper-medium on MyST and 11.06% using Whisper-small on the OGI Spontaneous dataset. Evaluation on CORAAL further confirms robustness to adult dialectal domain shifts, with up to 6% relative WER reduction, highlighting the generalizability of our approach to diverse low-resource conditions.
Entropy-Aware Domain-Routed Mixture-of-Experts Speech-LLM Framework: A Case Study of Multi-Domain Child-Adult ASR
Jun 09, 2026While Speech Large Language Models (Speech-LLMs) have achieved strong performance on adult Automatic Speech Recognition (ASR), their effectiveness on child speech remains under-explored, and single models often struggle to handle diverse adult and child age groups simultaneously. This paper proposes a Mixture-of-Experts (MoE) Speech-LLM for unified ASR across adult and child speech spanning diverse environments and age groups. The framework employs a Classifier-based Domain Router (C-DR) with a coarse-to-fine strategy and integrates both a Mixture-of-Projectors (MoP) and a Mixture-of-LoRAs (MoL) to model domain-specific variations. To address routing uncertainty near domain boundaries, an Entropy-Aware Routing (EAR) mechanism is introduced to dynamically incorporate a shared expert. Experiments on public child corpora demonstrate consistent improvements over baselines while preserving adult ASR performance. To our knowledge, this is the first work leveraging Speech-LLMs for unified, multi-domain ASR encompassing both children and adults.
GC-LoRA: Gated Convolutional LoRA for Parameter-Efficient Acoustic Adaptation
Jun 09, 2026Transformer-based Speech Foundation Models excel in most Automatic Speech Recognition tasks but often suffer performance degradation when applied to domains with mismatched acoustic characteristics. While Parameter Efficient Fine-Tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), adjust global attention, they lack the local context modeling crucial for capturing domain-specific variations. We propose GC-LoRA, a novel adapter architecture that injects Conformer-style local convolutional processing into pretrained Transformer encoders. By integrating a lightweight adapter to encoder attention output projections, our method efficiently captures local acoustic dependencies without disrupting pretrained global representations. Experiments across diverse datasets (acoustically-degraded, bandlimited, dialectal, child) demonstrate the efficacy of our approach, achieving Word Error Rate (WER) reductions of up to 10.9% compared to baselines while adding minimal trainable parameters.
STACodec: Semantic Token Assignment for Balancing Acoustic Fidelity and Semantic Information in Audio Codecs
Feb 05, 2026Neural audio codecs are widely used for audio compression and can be integrated into token-based language models. Traditional codecs preserve acoustic details well but lack semantic information. Recent hybrid codecs attempt to incorporate semantic information through distillation, but this often degrades reconstruction performance, making it difficult to achieve both. To address this limitation, we introduce STACodec, a unified codec that integrates semantic information from self-supervised learning (SSL) models into the first layer of residual vector quantization (RVQ-1) via semantic token assignment (STA). To further eliminate reliance on SSL-based semantic tokenizers and improve efficiency during inference, we propose a semantic pre-distillation (SPD) module, which predicts semantic tokens directly for assignment to the first RVQ layer during inference. Experimental results show that STACodec outperforms existing hybrid codecs in both audio reconstruction and downstream semantic tasks, demonstrating a better balance between acoustic fidelity and semantic capability.
Mind the Shift: Using Delta SSL Embeddings to Enhance Child ASR
Jan 28, 2026Self-supervised learning (SSL) models have achieved impressive results across many speech tasks, yet child automatic speech recognition (ASR) remains challenging due to limited data and pretraining domain mismatch. Fine-tuning SSL models on child speech induces shifts in the representation space. We hypothesize that delta SSL embeddings, defined as the differences between embeddings from a finetuned model and those from its pretrained counterpart, encode task-specific information that complements finetuned features from another SSL model. We evaluate multiple fusion strategies on the MyST childrens corpus using different models. Results show that delta embedding fusion with WavLM yields up to a 10 percent relative WER reduction for HuBERT and a 4.4 percent reduction for W2V2, compared to finetuned embedding fusion. Notably, fusing WavLM with delta W2V2 embeddings achieves a WER of 9.64, setting a new state of the art among SSL models on the MyST corpus. These findings demonstrate the effectiveness of delta embeddings and highlight feature fusion as a promising direction for advancing child ASR.
CHSER: A Dataset and Case Study on Generative Speech Error Correction for Child ASR
May 24, 2025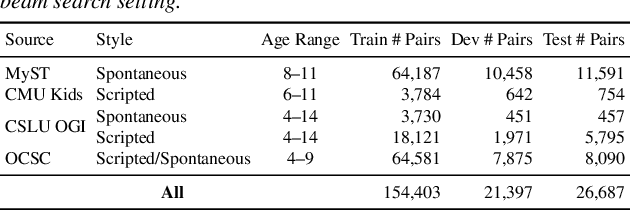
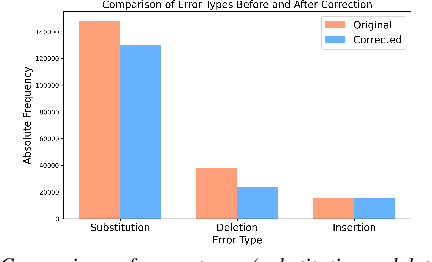
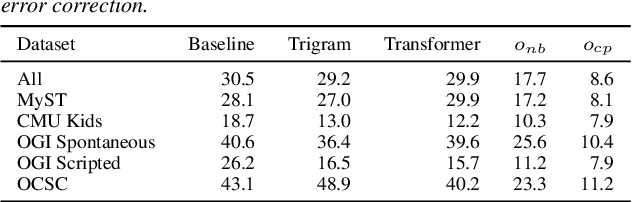
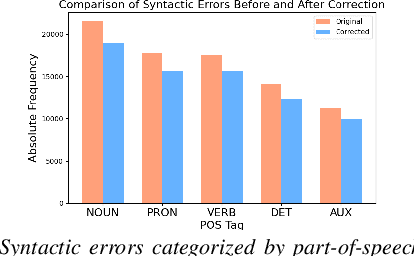
Automatic Speech Recognition (ASR) systems struggle with child speech due to its distinct acoustic and linguistic variability and limited availability of child speech datasets, leading to high transcription error rates. While ASR error correction (AEC) methods have improved adult speech transcription, their effectiveness on child speech remains largely unexplored. To address this, we introduce CHSER, a Generative Speech Error Correction (GenSEC) dataset for child speech, comprising 200K hypothesis-transcription pairs spanning diverse age groups and speaking styles. Results demonstrate that fine-tuning on the CHSER dataset achieves up to a 28.5% relative WER reduction in a zero-shot setting and a 13.3% reduction when applied to fine-tuned ASR systems. Additionally, our error analysis reveals that while GenSEC improves substitution and deletion errors, it struggles with insertions and child-specific disfluencies. These findings highlight the potential of GenSEC for improving child ASR.
Selective Attention Merging for low resource tasks: A case study of Child ASR
Jan 14, 2025While Speech Foundation Models (SFMs) excel in various speech tasks, their performance for low-resource tasks such as child Automatic Speech Recognition (ASR) is hampered by limited pretraining data. To address this, we explore different model merging techniques to leverage knowledge from models trained on larger, more diverse speech corpora. This paper also introduces Selective Attention (SA) Merge, a novel method that selectively merges task vectors from attention matrices to enhance SFM performance on low-resource tasks. Experiments on the MyST database show significant reductions in relative word error rate of up to 14%, outperforming existing model merging and data augmentation techniques. By combining data augmentation techniques with SA Merge, we achieve a new state-of-the-art WER of 8.69 on the MyST database for the Whisper-small model, highlighting the potential of SA Merge for improving low-resource ASR.
SOA: Reducing Domain Mismatch in SSL Pipeline by Speech Only Adaptation for Low Resource ASR
Jun 15, 2024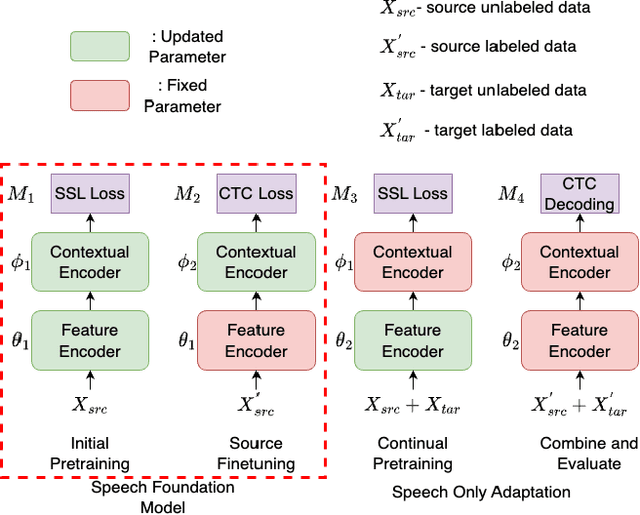
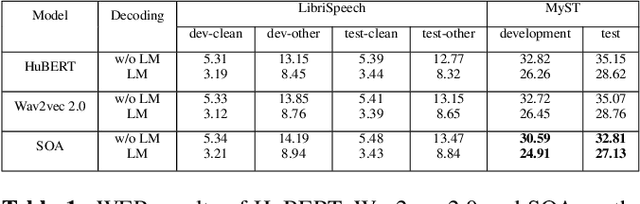
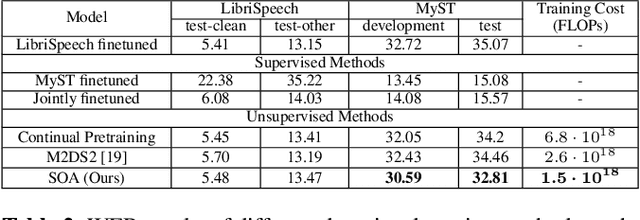
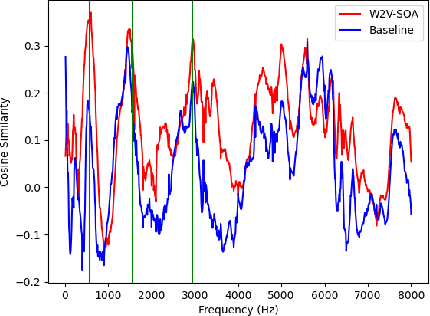
Recently, speech foundation models have gained popularity due to their superiority in finetuning downstream ASR tasks. However, models finetuned on certain domains, such as LibriSpeech (adult read speech), behave poorly on other domains (child or noisy speech). One solution could be collecting as much labeled and diverse data as possible for joint finetuning on various domains. However, collecting target domain speech-text paired data and retraining the model is often costly and computationally expensive. In this paper, we introduce a simple yet effective method, speech only adaptation (SOA), based on speech foundation models (Wav2vec 2.0), which requires only speech input data from the target domain. Specifically, the Wav2vec 2.0 feature encoder is continually pretrained with the Wav2vec 2.0 loss on both the source and target domain data for domain adaptation, while the contextual encoder is frozen. Compared to a source domain finetuned model with the feature encoder being frozen during training, we find that replacing the frozen feature encoder with the adapted one provides significant WER improvements to the target domain while preserving the performance of the source domain. The effectiveness of SOA is examined on various low resource or domain mismatched ASR settings, including adult-child and clean-noisy speech.
Benchmarking Children's ASR with Supervised and Self-supervised Speech Foundation Models
Jun 15, 2024Speech foundation models (SFMs) have achieved state-of-the-art results for various speech tasks in supervised (e.g. Whisper) or self-supervised systems (e.g. WavLM). However, the performance of SFMs for child ASR has not been systematically studied. In addition, there is no benchmark for child ASR with standard evaluations, making the comparisons of novel ideas difficult. In this paper, we initiate and present a comprehensive benchmark on several child speech databases based on various SFMs (Whisper, Wav2vec2.0, HuBERT, and WavLM). Moreover, we investigate finetuning strategies by comparing various data augmentation and parameter-efficient finetuning (PEFT) methods. We observe that the behaviors of these methods are different when the model size increases. For example, PEFT matches the performance of full finetuning for large models but worse for small models. To stabilize finetuning using augmented data, we propose a perturbation invariant finetuning (PIF) loss as a regularization.