 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOA: Reducing Domain Mismatch in SSL Pipeline by Speech Only Adaptation for Low Resource ASR
Paper and Code
Jun 15, 2024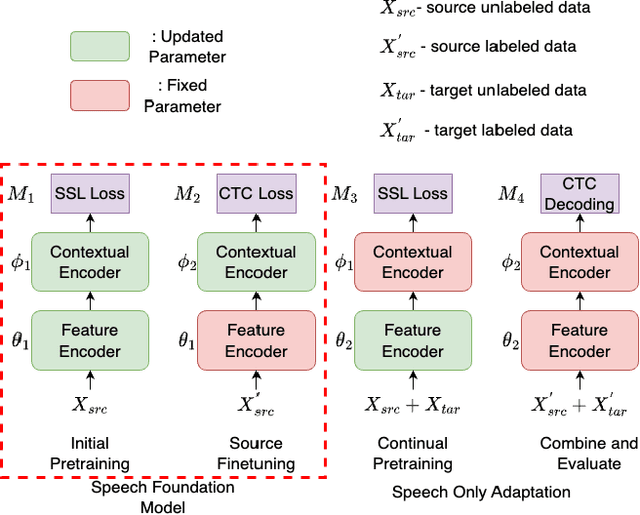
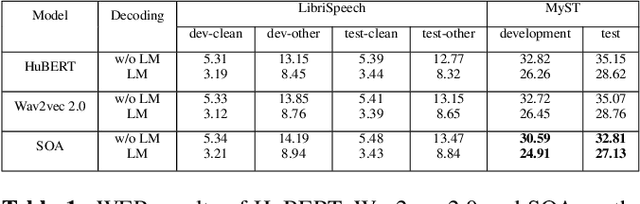
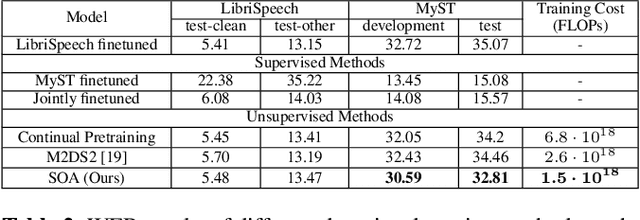
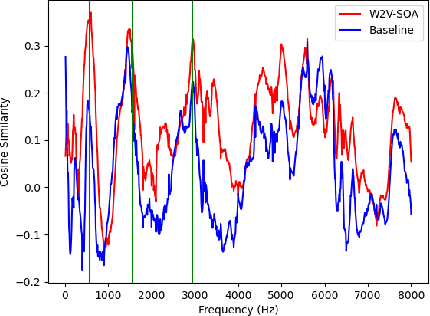
Recently, speech foundation models have gained popularity due to their superiority in finetuning downstream ASR tasks. However, models finetuned on certain domains, such as LibriSpeech (adult read speech), behave poorly on other domains (child or noisy speech). One solution could be collecting as much labeled and diverse data as possible for joint finetuning on various domains. However, collecting target domain speech-text paired data and retraining the model is often costly and computationally expensive. In this paper, we introduce a simple yet effective method, speech only adaptation (SOA), based on speech foundation models (Wav2vec 2.0), which requires only speech input data from the target domain. Specifically, the Wav2vec 2.0 feature encoder is continually pretrained with the Wav2vec 2.0 loss on both the source and target domain data for domain adaptation, while the contextual encoder is frozen. Compared to a source domain finetuned model with the feature encoder being frozen during training, we find that replacing the frozen feature encoder with the adapted one provides significant WER improvements to the target domain while preserving the performance of the source domain. The effectiveness of SOA is examined on various low resource or domain mismatched ASR settings, including adult-child and clean-noisy speech.