 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing Video Diffusion Transformers for Robust Point Tracking
Dec 23, 2025Point tracking aims to localize corresponding points across video frames, serving as a fundamental task for 4D reconstruction, robotics, and video editing. Existing methods commonly rely on shallow convolutional backbones such as ResNet that process frames independently, lacking temporal coherence and producing unreliable matching costs under challenging conditions. Through systematic analysis, we find that video Diffusion Transformers (DiTs), pre-trained on large-scale real-world videos with spatio-temporal attention, inherently exhibit strong point tracking capability and robustly handle dynamic motions and frequent occlusions. We propose DiTracker, which adapts video DiTs through: (1) query-key attention matching, (2) lightweight LoRA tuning, and (3) cost fusion with a ResNet backbone. Despite training with 8 times smaller batch size, DiTracker achieves state-of-the-art performance on challenging ITTO benchmark and matches or outperforms state-of-the-art models on TAP-Vid benchmarks. Our work validates video DiT features as an effective and efficient foundation for point tracking.
MATRIX: Mask Track Alignment for Interaction-aware Video Generation
Oct 08, 2025



Video DiTs have advanced video generation, yet they still struggle to model multi-instance or subject-object interactions. This raises a key question: How do these models internally represent interactions? To answer this, we curate MATRIX-11K, a video dataset with interaction-aware captions and multi-instance mask tracks. Using this dataset, we conduct a systematic analysis that formalizes two perspectives of video DiTs: semantic grounding, via video-to-text attention, which evaluates whether noun and verb tokens capture instances and their relations; and semantic propagation, via video-to-video attention, which assesses whether instance bindings persist across frames. We find both effects concentrate in a small subset of interaction-dominant layers. Motivated by this, we introduce MATRIX, a simple and effective regularization that aligns attention in specific layers of video DiTs with multi-instance mask tracks from the MATRIX-11K dataset, enhancing both grounding and propagation. We further propose InterGenEval, an evaluation protocol for interaction-aware video generation. In experiments, MATRIX improves both interaction fidelity and semantic alignment while reducing drift and hallucination. Extensive ablations validate our design choices. Codes and weights will be released.
Vid-CamEdit: Video Camera Trajectory Editing with Generative Rendering from Estimated Geometry
Jun 16, 2025We introduce Vid-CamEdit, a novel framework for video camera trajectory editing, enabling the re-synthesis of monocular videos along user-defined camera paths. This task is challenging due to its ill-posed nature and the limited multi-view video data for training. Traditional reconstruction methods struggle with extreme trajectory changes, and existing generative models for dynamic novel view synthesis cannot handle in-the-wild videos. Our approach consists of two steps: estimating temporally consistent geometry, and generative rendering guided by this geometry. By integrating geometric priors, the generative model focuses on synthesizing realistic details where the estimated geometry is uncertain. We eliminate the need for extensive 4D training data through a factorized fine-tuning framework that separately trains spatial and temporal components using multi-view image and video data. Our method outperforms baselines in producing plausible videos from novel camera trajectories, especially in extreme extrapolation scenarios on real-world footage.
Appearance Matching Adapter for Exemplar-based Semantic Image Synthesis
Dec 04, 2024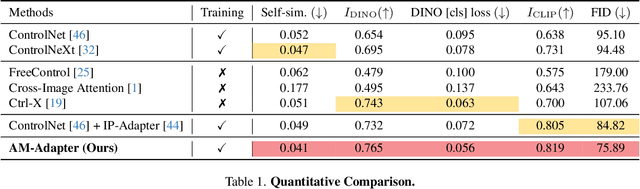

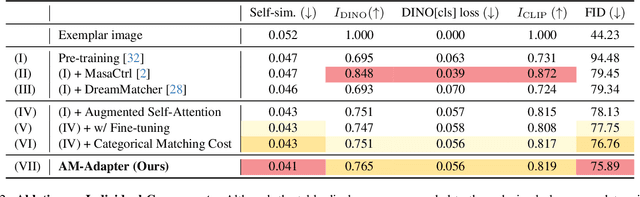

Exemplar-based semantic image synthesis aims to generate images aligned with given semantic content while preserving the appearance of an exemplar image. Conventional structure-guidance models, such as ControlNet, are limited in that they cannot directly utilize exemplar images as input, relying instead solely on text prompts to control appearance. Recent tuning-free approaches address this limitation by transferring local appearance from the exemplar image to the synthesized image through implicit cross-image matching in the augmented self-attention mechanism of pre-trained diffusion models. However, these methods face challenges when applied to content-rich scenes with significant geometric deformations, such as driving scenes. In this paper, we propose the Appearance Matching Adapter (AM-Adapter), a learnable framework that enhances cross-image matching within augmented self-attention by incorporating semantic information from segmentation maps. To effectively disentangle generation and matching processes, we adopt a stage-wise training approach. Initially, we train the structure-guidance and generation networks, followed by training the AM-Adapter while keeping the other networks frozen. During inference, we introduce an automated exemplar retrieval method to efficiently select exemplar image-segmentation pairs. Despite utilizing a limited number of learnable parameters, our method achieves state-of-the-art performance, excelling in both semantic alignment preservation and local appearance fidelity. Extensive ablation studies further validate our design choices. Code and pre-trained weights will be publicly available.: https://cvlab-kaist.github.io/AM-Adapter/
MoDiTalker: Motion-Disentangled Diffusion Model for High-Fidelity Talking Head Generation
Mar 28, 2024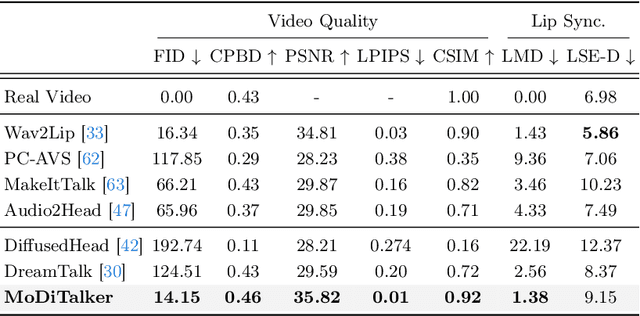
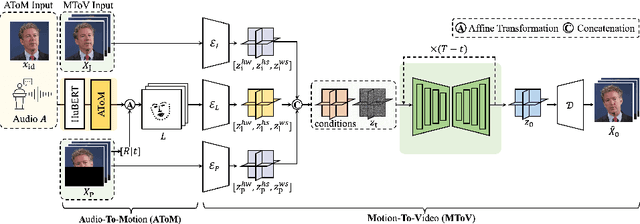

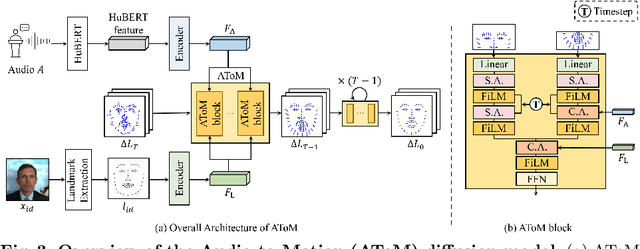
Conventional GAN-based models for talking head generation often suffer from limited quality and unstable training. Recent approaches based on diffusion models aimed to address these limitations and improve fidelity. However, they still face challenges, including extensive sampling times and difficulties in maintaining temporal consistency due to the high stochasticity of diffusion models. To overcome these challenges, we propose a novel motion-disentangled diffusion model for high-quality talking head generation, dubbed MoDiTalker. We introduce the two modules: audio-to-motion (AToM), designed to generate a synchronized lip motion from audio, and motion-to-video (MToV), designed to produce high-quality head video following the generated motion. AToM excels in capturing subtle lip movements by leveraging an audio attention mechanism. In addition, MToV enhances temporal consistency by leveraging an efficient tri-plane representation. Our experiments conducted on standard benchmarks demonstrate that our model achieves superior performance compared to existing models. We also provide comprehensive ablation studies and user study results.
DreamMatcher: Appearance Matching Self-Attention for Semantically-Consistent Text-to-Image Personalization
Feb 15, 2024
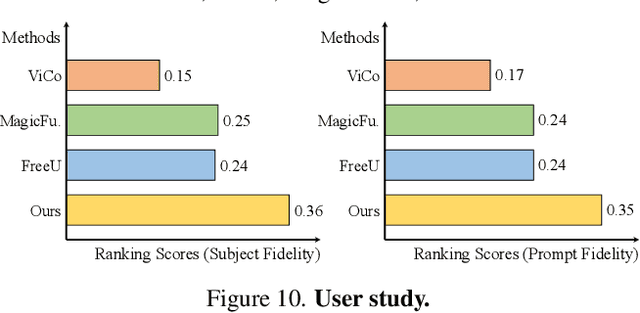
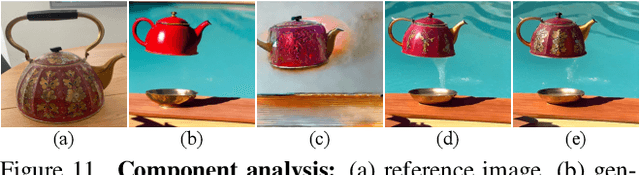

The objective of text-to-image (T2I) personalization is to customize a diffusion model to a user-provided reference concept, generating diverse images of the concept aligned with the target prompts. Conventional methods representing the reference concepts using unique text embeddings often fail to accurately mimic the appearance of the reference. To address this, one solution may be explicitly conditioning the reference images into the target denoising process, known as key-value replacement. However, prior works are constrained to local editing since they disrupt the structure path of the pre-trained T2I model. To overcome this, we propose a novel plug-in method, called DreamMatcher, which reformulates T2I personalization as semantic matching. Specifically, DreamMatcher replaces the target values with reference values aligned by semantic matching, while leaving the structure path unchanged to preserve the versatile capability of pre-trained T2I models for generating diverse structures. We also introduce a semantic-consistent masking strategy to isolate the personalized concept from irrelevant regions introduced by the target prompts. Compatible with existing T2I models, DreamMatcher shows significant improvements in complex scenarios. Intensive analyses demonstrate the effectiveness of our approach.