 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
DreamMatcher: Appearance Matching Self-Attention for Semantically-Consistent Text-to-Image Personalization
Feb 15, 2024
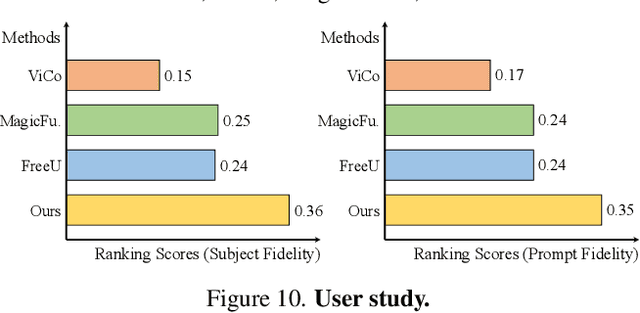
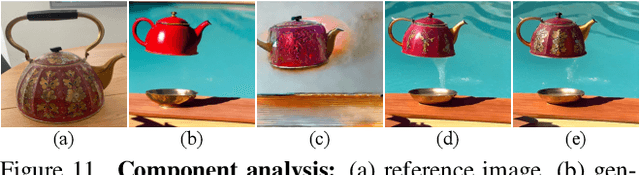

The objective of text-to-image (T2I) personalization is to customize a diffusion model to a user-provided reference concept, generating diverse images of the concept aligned with the target prompts. Conventional methods representing the reference concepts using unique text embeddings often fail to accurately mimic the appearance of the reference. To address this, one solution may be explicitly conditioning the reference images into the target denoising process, known as key-value replacement. However, prior works are constrained to local editing since they disrupt the structure path of the pre-trained T2I model. To overcome this, we propose a novel plug-in method, called DreamMatcher, which reformulates T2I personalization as semantic matching. Specifically, DreamMatcher replaces the target values with reference values aligned by semantic matching, while leaving the structure path unchanged to preserve the versatile capability of pre-trained T2I models for generating diverse structures. We also introduce a semantic-consistent masking strategy to isolate the personalized concept from irrelevant regions introduced by the target prompts. Compatible with existing T2I models, DreamMatcher shows significant improvements in complex scenarios. Intensive analyses demonstrate the effectiveness of our approach.
ProxyDet: Synthesizing Proxy Novel Classes via Classwise Mixup for Open-Vocabulary Object Detection
Dec 19, 2023Open-vocabulary object detection (OVOD) aims to recognize novel objects whose categories are not included in the training set. In order to classify these unseen classes during training, many OVOD frameworks leverage the zero-shot capability of largely pretrained vision and language models, such as CLIP. To further improve generalization on the unseen novel classes, several approaches proposed to additionally train with pseudo region labeling on the external data sources that contain a substantial number of novel category labels beyond the existing training data. Albeit its simplicity, these pseudo-labeling methods still exhibit limited improvement with regard to the truly unseen novel classes that were not pseudo-labeled. In this paper, we present a novel, yet simple technique that helps generalization on the overall distribution of novel classes. Inspired by our observation that numerous novel classes reside within the convex hull constructed by the base (seen) classes in the CLIP embedding space, we propose to synthesize proxy-novel classes approximating novel classes via linear mixup between a pair of base classes. By training our detector with these synthetic proxy-novel classes, we effectively explore the embedding space of novel classes. The experimental results on various OVOD benchmarks such as LVIS and COCO demonstrate superior performance on novel classes compared to the other state-of-the-art methods. Code is available at https://github.com/clovaai/ProxyDet.
Rainbow Memory: Continual Learning with a Memory of Diverse Samples
Mar 31, 2021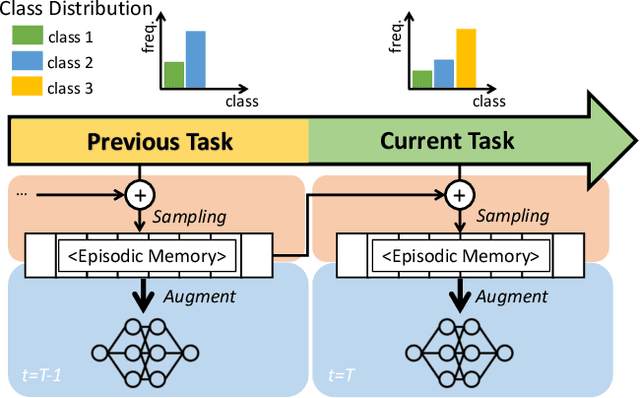
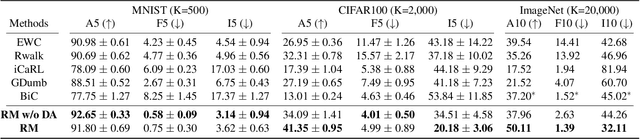
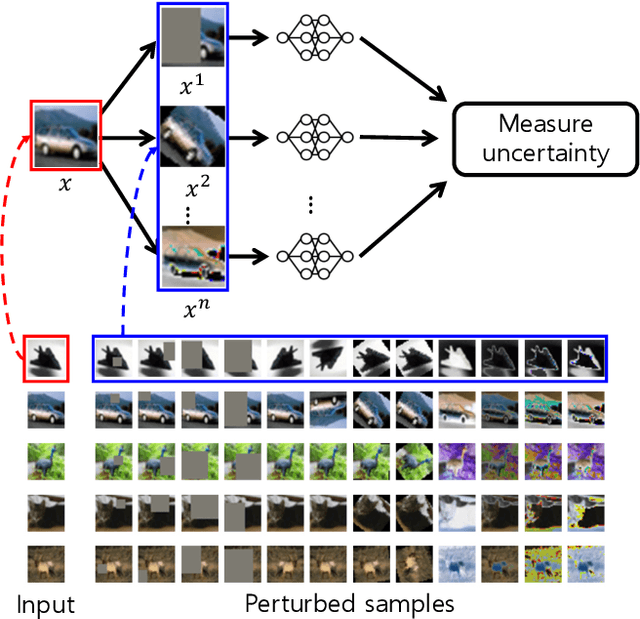
Continual learning is a realistic learning scenario for AI models. Prevalent scenario of continual learning, however, assumes disjoint sets of classes as tasks and is less realistic rather artificial. Instead, we focus on 'blurry' task boundary; where tasks shares classes and is more realistic and practical. To address such task, we argue the importance of diversity of samples in an episodic memory. To enhance the sample diversity in the memory, we propose a novel memory management strategy based on per-sample classification uncertainty and data augmentation, named Rainbow Memory (RM). With extensive empirical validations on MNIST, CIFAR10, CIFAR100, and ImageNet datasets, we show that the proposed method significantly improves the accuracy in blurry continual learning setups, outperforming state of the arts by large margins despite its simplicity. Code and data splits will be available in https://github.com/clovaai/rainbow-memory.
GradPIM: A Practical Processing-in-DRAM Architecture for Gradient Descent
Feb 15, 2021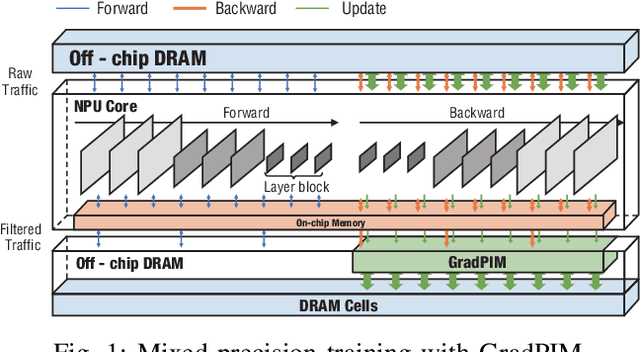
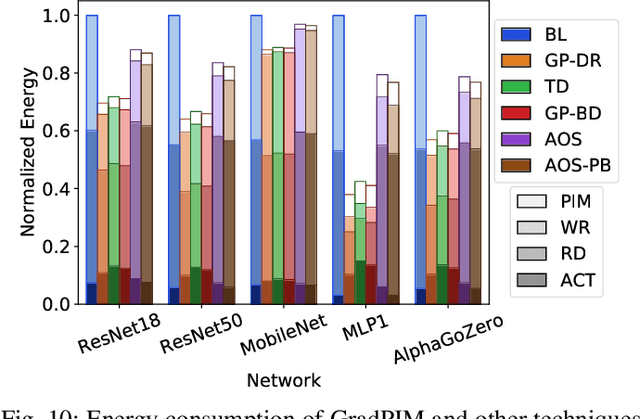
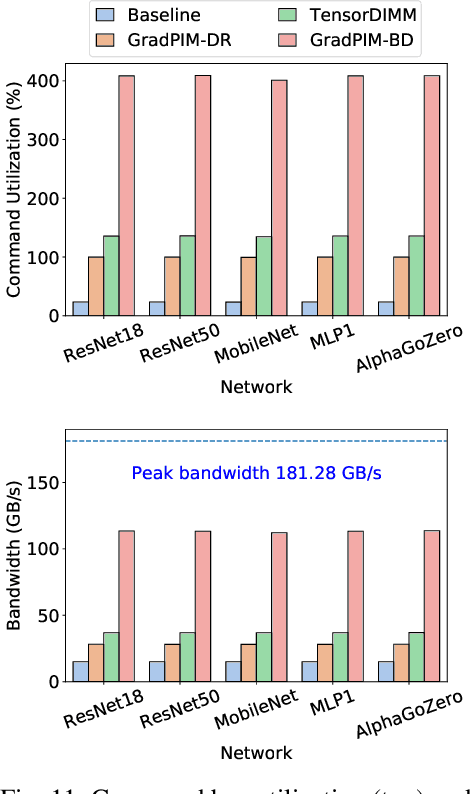
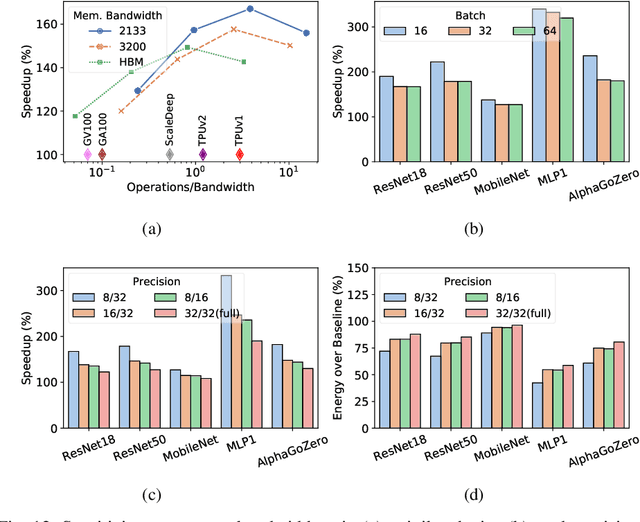
In this paper, we present GradPIM, a processing-in-memory architecture which accelerates parameter updates of deep neural networks training. As one of processing-in-memory techniques that could be realized in the near future, we propose an incremental, simple architectural design that does not invade the existing memory protocol. Extending DDR4 SDRAM to utilize bank-group parallelism makes our operation designs in processing-in-memory (PIM) module efficient in terms of hardware cost and performance. Our experimental results show that the proposed architecture can improve the performance of DNN training and greatly reduce memory bandwidth requirement while posing only a minimal amount of overhead to the protocol and DRAM area.
Efficient Active Learning for Automatic Speech Recognition via Augmented Consistency Regularization
Jun 19, 2020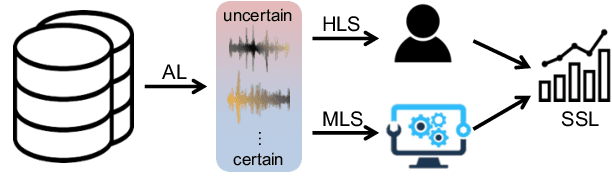
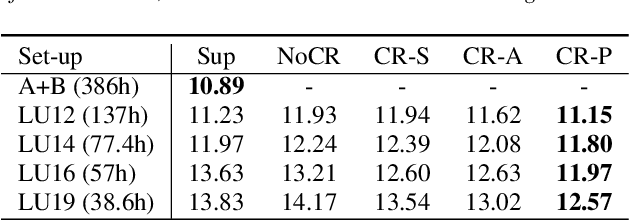
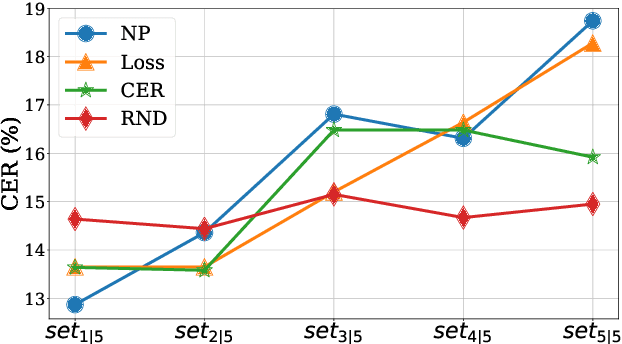
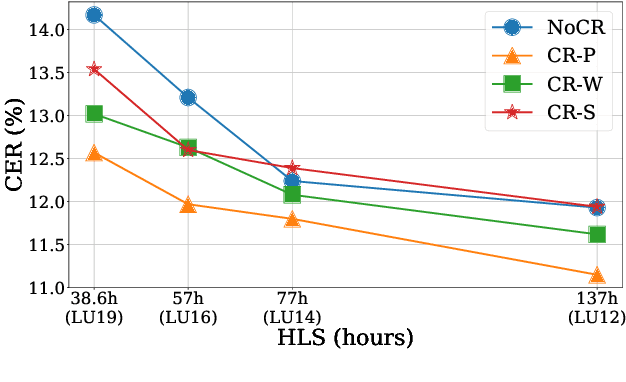
The cost of labeling transcriptions for large speech corpora becomes a bottleneck to maximally enjoy the potential capacity of deep neural network-based automatic speech recognition (ASR) models. Therefore, in this paper, we present a new training scheme that minimizes the labeling cost by adopting the concepts of semi-supervised learning (SSL) and active learning (AL) approaches and making a synergy from them. While AL studies only focus on selecting minimized the number of samples to be labeled with a criterion and taking advantage of such samples, we show that the training efficiency can be further improved by utilizing the unlabeled samples by sophisticatedly designing unsupervised loss that complements the unwanted behavior of supervised loss effectively. Our unsupervised loss is built on Consistency-Regularization (CR) approach, and we propose appropriate augmentation techniques to adopt CR in ASR field successfully. From the qualitative and quantitative experiments on the real-world dataset from deployed end-user voice assistant services, we show that the proposed methods can handle a large number of unlabeled speech data to achieve competitive model performance, with a sustainable amount of human labeling cost.