 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSET: Accurate Latency-Critical NVFP4 Reasoning via Step-Aware Temperature Scaling
Jun 11, 2026Large reasoning models (LRMs) improve complex problem-solving by generating long intermediate reasoning traces, but this substantially increases inference costs. NVFP4 inference offers a promising approach to reduce both computational and memory costs through hardware-supported low-precision execution. However, directly applying NVFP4 to LRMs introduces two practical limitations: reasoning accuracy degrades under quantization, and existing NVFP4 kernels do not fully realize latency benefits in small-batch autoregressive decoding. In this work, we analyze the effect of NVFP4 quantization on token-level uncertainty during reasoning. We show that quantization increases incorrect sampling at low-entropy symbolic tokens, while causing over-concentration on a small set of tokens in high-uncertainty reasoning steps. Based on this observation, we propose \textbf{ReSET}, a reasoning-step entropy-based temperature-scaling method that estimates step-level uncertainty online and adapts the decoding temperature using both token-level and step-level entropy signals. To address the latency gap, we further design a CUDA-core small-$M$ NVFP4 kernel for latency-critical autoregressive decoding. Across reasoning benchmarks and model scales, ReSET improves NVFP4 reasoning accuracy by up to $\sim\!$2 points over the NVFP4 baseline. Our CUDA-core small-$M$ kernel further improves latency-critical decoding, delivering up to $2.5\!\times$ kernel-level speedup over NVFP4 vLLM and approximately $2\!\times$ end-to-end decoding speedup over BF16. Code is available at https://github.com/aiha-lab/ReSET.
GradPIM: A Practical Processing-in-DRAM Architecture for Gradient Descent
Feb 15, 2021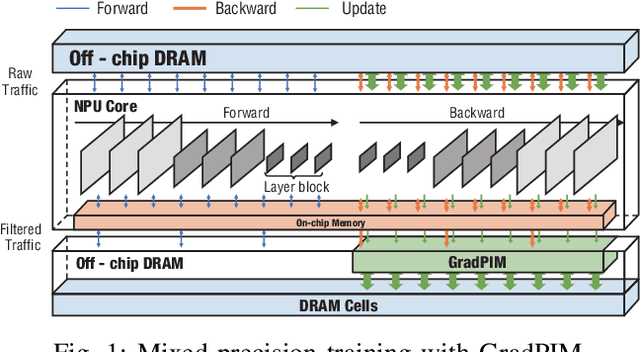
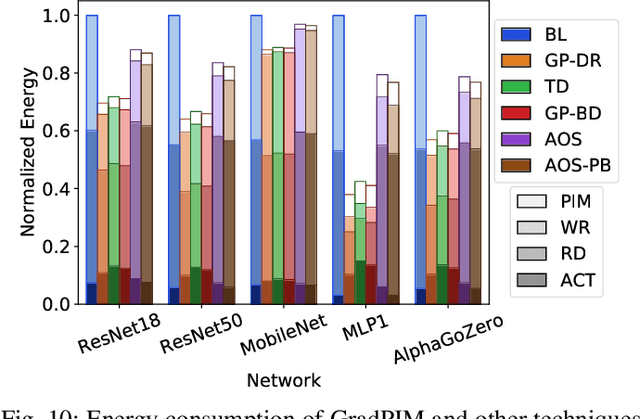
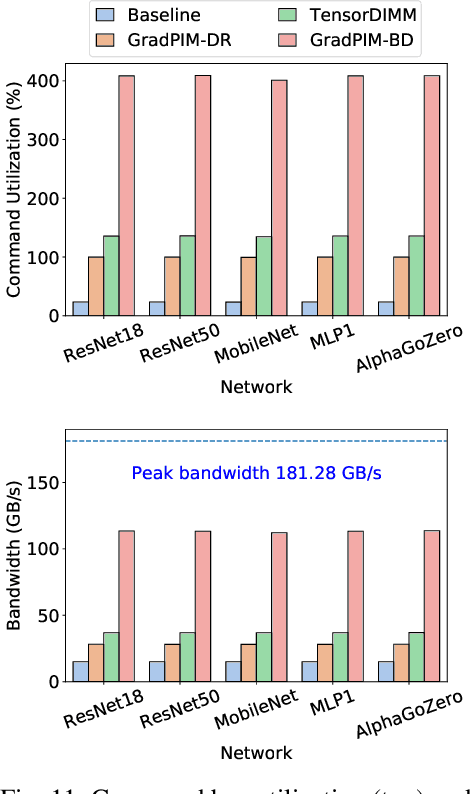
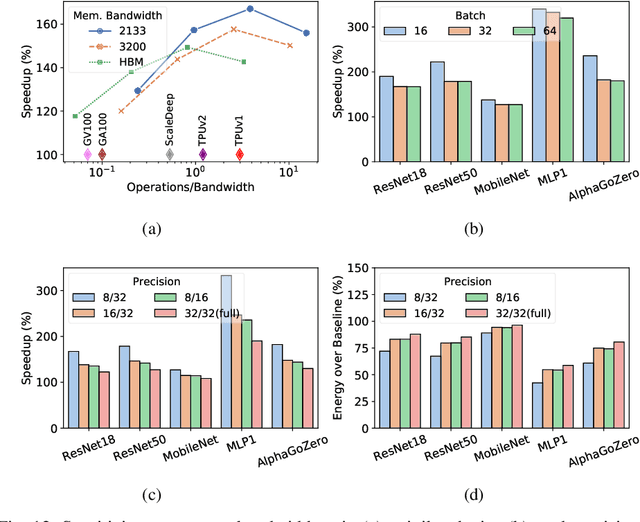
In this paper, we present GradPIM, a processing-in-memory architecture which accelerates parameter updates of deep neural networks training. As one of processing-in-memory techniques that could be realized in the near future, we propose an incremental, simple architectural design that does not invade the existing memory protocol. Extending DDR4 SDRAM to utilize bank-group parallelism makes our operation designs in processing-in-memory (PIM) module efficient in terms of hardware cost and performance. Our experimental results show that the proposed architecture can improve the performance of DNN training and greatly reduce memory bandwidth requirement while posing only a minimal amount of overhead to the protocol and DRAM area.