 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Wrench Control via Wrench Disturbance Observer for Learning-free Peg-in-hole Assembly
Jan 08, 2026This paper proposes a Dynamic Wrench Disturbance Observer (DW-DOB) designed to achieve highly sensitive zero-wrench control in contact-rich manipulation. By embedding task-space inertia into the observer nominal model, DW-DOB cleanly separates intrinsic dynamic reactions from true external wrenches. This preserves sensitivity to small forces and moments while ensuring robust regulation of contact wrenches. A passivity-based analysis further demonstrates that DW-DOB guarantees stable interactions under dynamic conditions, addressing the shortcomings of conventional observers that fail to compensate for inertial effects. Peg-in-hole experiments at industrial tolerances (H7/h6) validate the approach, yielding deeper and more compliant insertions with minimal residual wrenches and outperforming a conventional wrench disturbance observer and a PD baseline. These results highlight DW-DOB as a practical learning-free solution for high-precision zero-wrench control in contact-rich tasks.
GradPIM: A Practical Processing-in-DRAM Architecture for Gradient Descent
Feb 15, 2021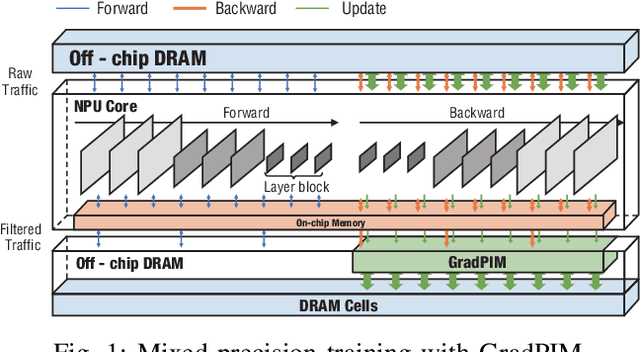
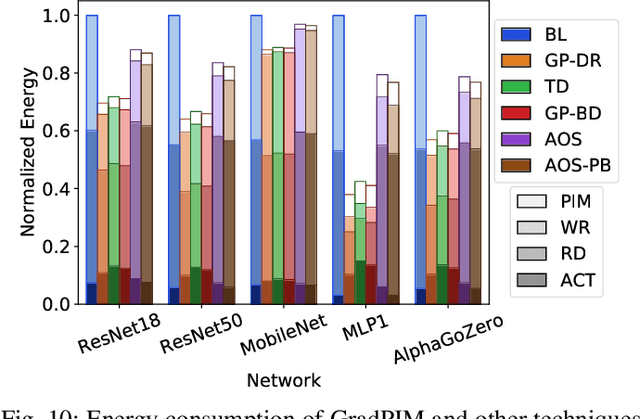
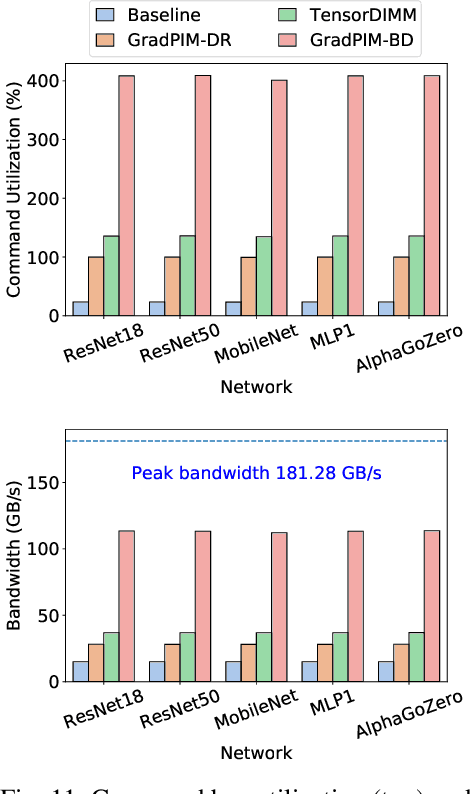
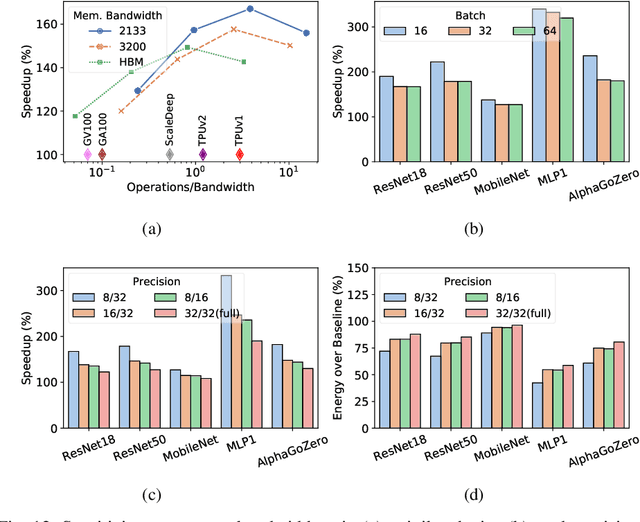
In this paper, we present GradPIM, a processing-in-memory architecture which accelerates parameter updates of deep neural networks training. As one of processing-in-memory techniques that could be realized in the near future, we propose an incremental, simple architectural design that does not invade the existing memory protocol. Extending DDR4 SDRAM to utilize bank-group parallelism makes our operation designs in processing-in-memory (PIM) module efficient in terms of hardware cost and performance. Our experimental results show that the proposed architecture can improve the performance of DNN training and greatly reduce memory bandwidth requirement while posing only a minimal amount of overhead to the protocol and DRAM area.
Autoencoder-Based Incremental Class Learning without Retraining on Old Data
Jul 18, 2019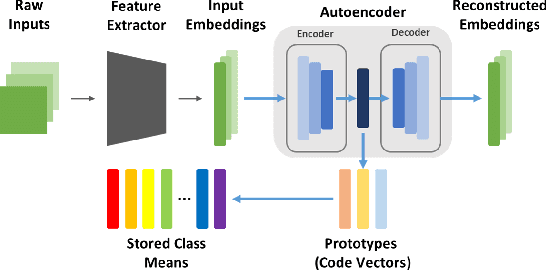

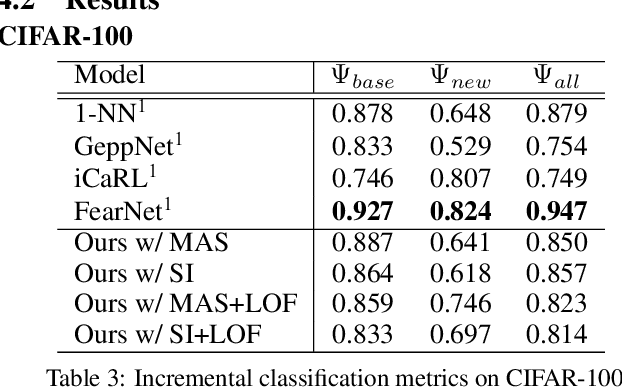
Incremental class learning, a scenario in continual learning context where classes and their training data are sequentially and disjointedly observed, challenges a problem widely known as catastrophic forgetting. In this work, we propose a novel incremental class learning method that can significantly reduce memory overhead compared to previous approaches. Apart from conventional classification scheme using softmax, our model bases on an autoencoder to extract prototypes for given inputs so that no change in its output unit is required. It stores only the mean of prototypes per class to perform metric-based classification, unlike rehearsal approaches which rely on large memory or generative model. To mitigate catastrophic forgetting, regularization methods are applied on our model when a new task is encountered. We evaluate our method by experimenting on CIFAR-100 and CUB-200-2011 and show that its performance is comparable to the state-of-the-art method with much lower additional memory cost.
Network Recasting: A Universal Method for Network Architecture Transformation
Sep 14, 2018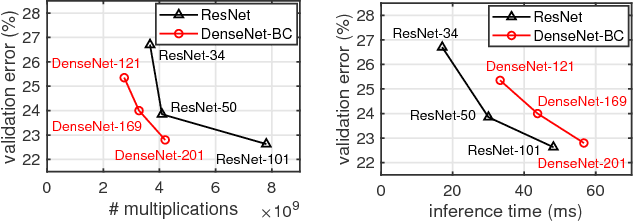
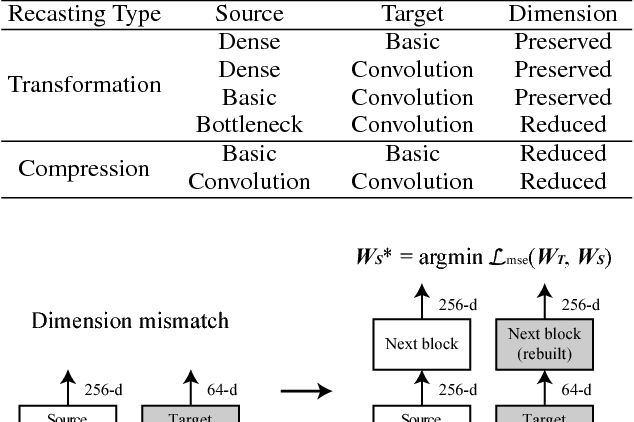
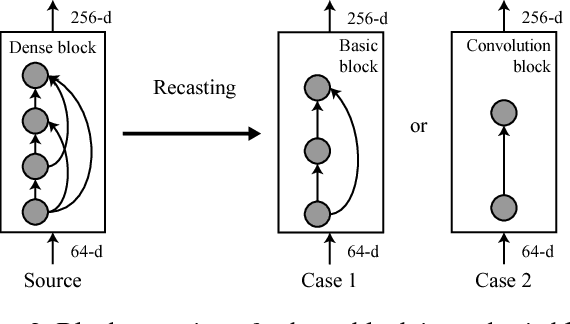
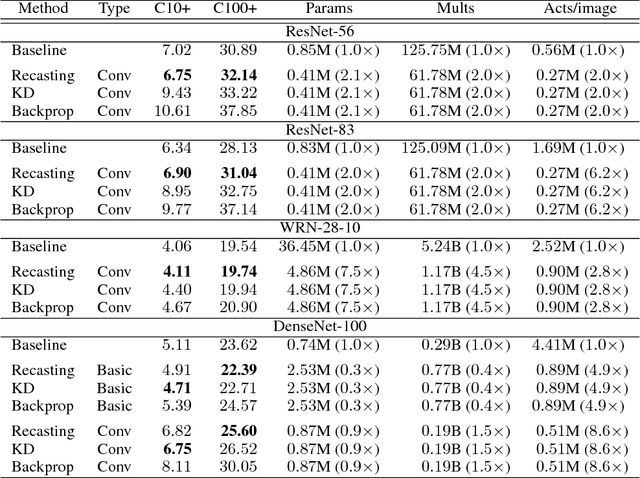
This paper proposes network recasting as a general method for network architecture transformation. The primary goal of this method is to accelerate the inference process through the transformation, but there can be many other practical applications. The method is based on block-wise recasting; it recasts each source block in a pre-trained teacher network to a target block in a student network. For the recasting, a target block is trained such that its output activation approximates that of the source block. Such a block-by-block recasting in a sequential manner transforms the network architecture while preserving the accuracy. This method can be used to transform an arbitrary teacher network type to an arbitrary student network type. It can even generate a mixed-architecture network that consists of two or more types of block. The network recasting can generate a network with fewer parameters and/or activations, which reduce the inference time significantly. Naturally, it can be used for network compression by recasting a trained network into a smaller network of the same type. Our experiments show that it outperforms previous compression approaches in terms of actual speedup on a GPU.