 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Active Learning for Automatic Speech Recognition via Augmented Consistency Regularization
Paper and Code
Jun 19, 2020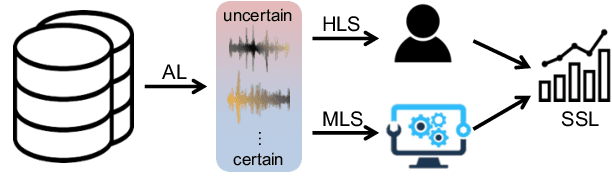
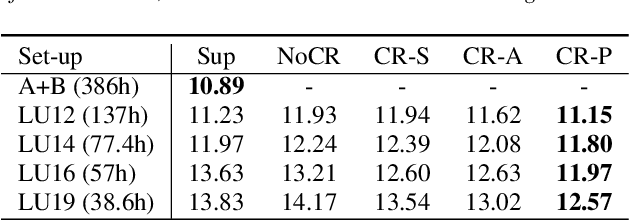
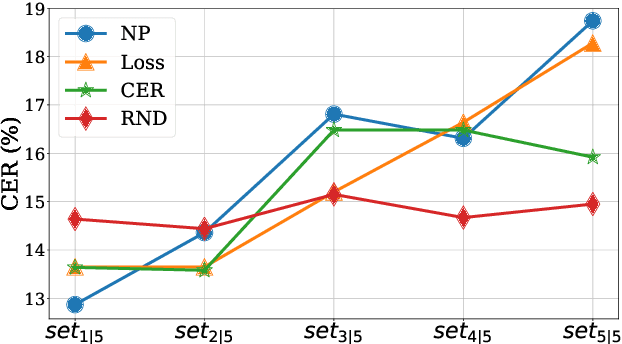
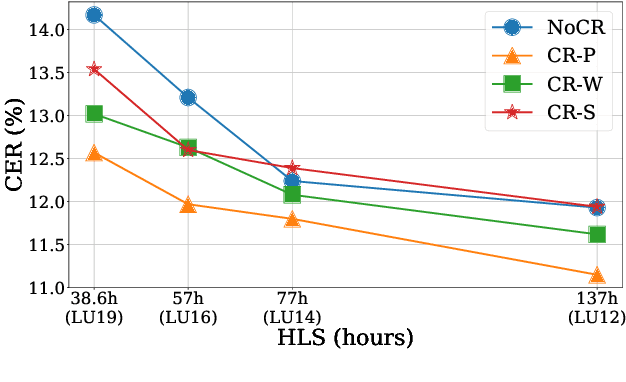
The cost of labeling transcriptions for large speech corpora becomes a bottleneck to maximally enjoy the potential capacity of deep neural network-based automatic speech recognition (ASR) models. Therefore, in this paper, we present a new training scheme that minimizes the labeling cost by adopting the concepts of semi-supervised learning (SSL) and active learning (AL) approaches and making a synergy from them. While AL studies only focus on selecting minimized the number of samples to be labeled with a criterion and taking advantage of such samples, we show that the training efficiency can be further improved by utilizing the unlabeled samples by sophisticatedly designing unsupervised loss that complements the unwanted behavior of supervised loss effectively. Our unsupervised loss is built on Consistency-Regularization (CR) approach, and we propose appropriate augmentation techniques to adopt CR in ASR field successfully. From the qualitative and quantitative experiments on the real-world dataset from deployed end-user voice assistant services, we show that the proposed methods can handle a large number of unlabeled speech data to achieve competitive model performance, with a sustainable amount of human labeling cost.