 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAppearance Matching Adapter for Exemplar-based Semantic Image Synthesis
Dec 04, 2024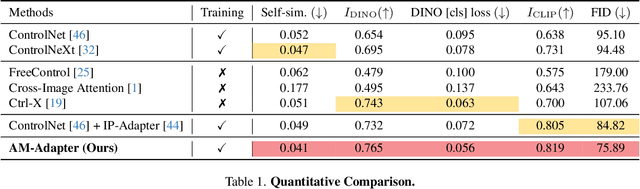

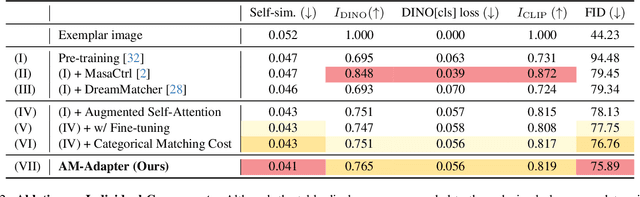

Exemplar-based semantic image synthesis aims to generate images aligned with given semantic content while preserving the appearance of an exemplar image. Conventional structure-guidance models, such as ControlNet, are limited in that they cannot directly utilize exemplar images as input, relying instead solely on text prompts to control appearance. Recent tuning-free approaches address this limitation by transferring local appearance from the exemplar image to the synthesized image through implicit cross-image matching in the augmented self-attention mechanism of pre-trained diffusion models. However, these methods face challenges when applied to content-rich scenes with significant geometric deformations, such as driving scenes. In this paper, we propose the Appearance Matching Adapter (AM-Adapter), a learnable framework that enhances cross-image matching within augmented self-attention by incorporating semantic information from segmentation maps. To effectively disentangle generation and matching processes, we adopt a stage-wise training approach. Initially, we train the structure-guidance and generation networks, followed by training the AM-Adapter while keeping the other networks frozen. During inference, we introduce an automated exemplar retrieval method to efficiently select exemplar image-segmentation pairs. Despite utilizing a limited number of learnable parameters, our method achieves state-of-the-art performance, excelling in both semantic alignment preservation and local appearance fidelity. Extensive ablation studies further validate our design choices. Code and pre-trained weights will be publicly available.: https://cvlab-kaist.github.io/AM-Adapter/