 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Grounded Multi-Domain Image Translation via Semantic Difference Guidance
Jan 12, 2026Multi-domain image-to-image translation re quires grounding semantic differences ex pressed in natural language prompts into corresponding visual transformations, while preserving unrelated structural and seman tic content. Existing methods struggle to maintain structural integrity and provide fine grained, attribute-specific control, especially when multiple domains are involved. We propose LACE (Language-grounded Attribute Controllable Translation), built on two compo nents: (1) a GLIP-Adapter that fuses global semantics with local structural features to pre serve consistency, and (2) a Multi-Domain Control Guidance mechanism that explicitly grounds the semantic delta between source and target prompts into per-attribute translation vec tors, aligning linguistic semantics with domain level visual changes. Together, these modules enable compositional multi-domain control with independent strength modulation for each attribute. Experiments on CelebA(Dialog) and BDD100K demonstrate that LACE achieves high visual fidelity, structural preservation, and interpretable domain-specific control, surpass ing prior baselines. This positions LACE as a cross-modal content generation framework bridging language semantics and controllable visual translation.
Appearance Matching Adapter for Exemplar-based Semantic Image Synthesis
Dec 04, 2024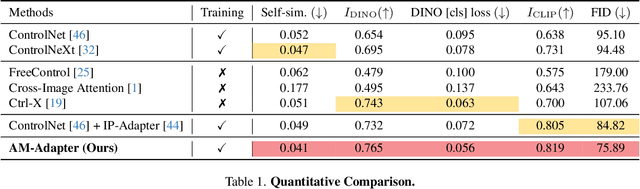

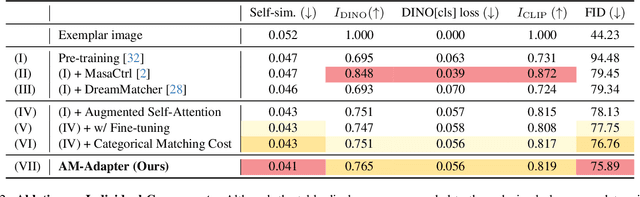

Exemplar-based semantic image synthesis aims to generate images aligned with given semantic content while preserving the appearance of an exemplar image. Conventional structure-guidance models, such as ControlNet, are limited in that they cannot directly utilize exemplar images as input, relying instead solely on text prompts to control appearance. Recent tuning-free approaches address this limitation by transferring local appearance from the exemplar image to the synthesized image through implicit cross-image matching in the augmented self-attention mechanism of pre-trained diffusion models. However, these methods face challenges when applied to content-rich scenes with significant geometric deformations, such as driving scenes. In this paper, we propose the Appearance Matching Adapter (AM-Adapter), a learnable framework that enhances cross-image matching within augmented self-attention by incorporating semantic information from segmentation maps. To effectively disentangle generation and matching processes, we adopt a stage-wise training approach. Initially, we train the structure-guidance and generation networks, followed by training the AM-Adapter while keeping the other networks frozen. During inference, we introduce an automated exemplar retrieval method to efficiently select exemplar image-segmentation pairs. Despite utilizing a limited number of learnable parameters, our method achieves state-of-the-art performance, excelling in both semantic alignment preservation and local appearance fidelity. Extensive ablation studies further validate our design choices. Code and pre-trained weights will be publicly available.: https://cvlab-kaist.github.io/AM-Adapter/
Building Emotional Machines: Recognizing Image Emotions through Deep Neural Networks
Jul 03, 2017
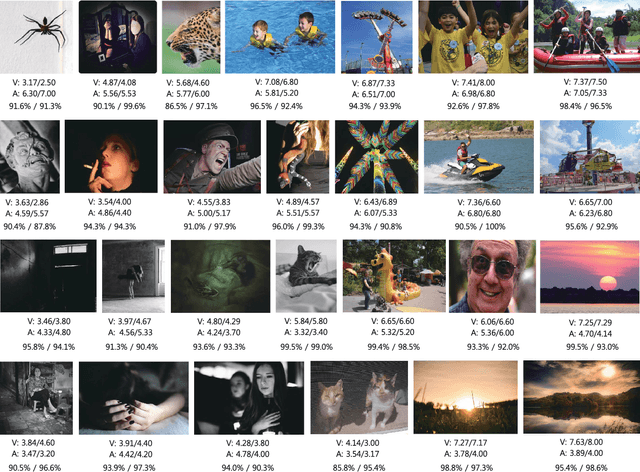


An image is a very effective tool for conveying emotions. Many researchers have investigated in computing the image emotions by using various features extracted from images. In this paper, we focus on two high level features, the object and the background, and assume that the semantic information of images is a good cue for predicting emotion. An object is one of the most important elements that define an image, and we find out through experiments that there is a high correlation between the object and the emotion in images. Even with the same object, there may be slight difference in emotion due to different backgrounds, and we use the semantic information of the background to improve the prediction performance. By combining the different levels of features, we build an emotion based feed forward deep neural network which produces the emotion values of a given image. The output emotion values in our framework are continuous values in the 2-dimensional space (Valence and Arousal), which are more effective than using a few number of emotion categories in describing emotions. Experiments confirm the effectiveness of our network in predicting the emotion of images.