 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoDiTalker: Motion-Disentangled Diffusion Model for High-Fidelity Talking Head Generation
Paper and Code
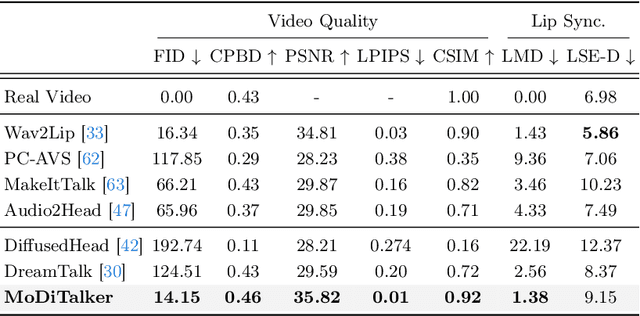
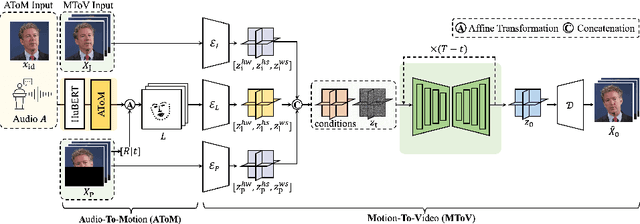

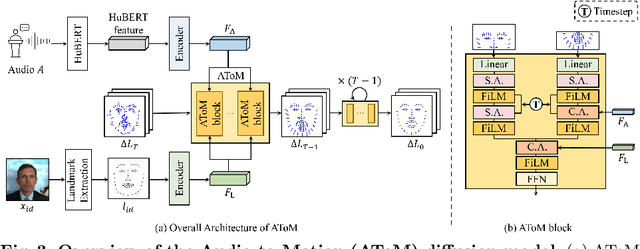
Conventional GAN-based models for talking head generation often suffer from limited quality and unstable training. Recent approaches based on diffusion models aimed to address these limitations and improve fidelity. However, they still face challenges, including extensive sampling times and difficulties in maintaining temporal consistency due to the high stochasticity of diffusion models. To overcome these challenges, we propose a novel motion-disentangled diffusion model for high-quality talking head generation, dubbed MoDiTalker. We introduce the two modules: audio-to-motion (AToM), designed to generate a synchronized lip motion from audio, and motion-to-video (MToV), designed to produce high-quality head video following the generated motion. AToM excels in capturing subtle lip movements by leveraging an audio attention mechanism. In addition, MToV enhances temporal consistency by leveraging an efficient tri-plane representation. Our experiments conducted on standard benchmarks demonstrate that our model achieves superior performance compared to existing models. We also provide comprehensive ablation studies and user study results.