 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUO-VSR: Dual-Stream Distillation for One-Step Video Super-Resolution
Mar 23, 2026Diffusion-based video super-resolution (VSR) has recently achieved remarkable fidelity but still suffers from prohibitive sampling costs. While distribution matching distillation (DMD) can accelerate diffusion models toward one-step generation, directly applying it to VSR often results in training instability alongside degraded and insufficient supervision. To address these issues, we propose DUO-VSR, a three-stage framework built upon a Dual-Stream Distillation strategy that unifies distribution matching and adversarial supervision for one-step VSR. Firstly, a Progressive Guided Distillation Initialization is employed to stabilize subsequent training through trajectory-preserving distillation. Next, the Dual-Stream Distillation jointly optimizes the DMD and Real-Fake Score Feature GAN (RFS-GAN) streams, with the latter providing complementary adversarial supervision leveraging discriminative features from both real and fake score models. Finally, a Preference-Guided Refinement stage further aligns the student with perceptual quality preferences. Extensive experiments demonstrate that DUO-VSR achieves superior visual quality and efficiency over previous one-step VSR approaches.
NOVA: Sparse Control, Dense Synthesis for Pair-Free Video Editing
Mar 03, 2026Recent video editing models have achieved impressive results, but most still require large-scale paired datasets. Collecting such naturally aligned pairs at scale remains highly challenging and constitutes a critical bottleneck, especially for local video editing data. Existing workarounds transfer image editing to video through global motion control for pair-free video editing, but such designs struggle with background and temporal consistency. In this paper, we propose NOVA: Sparse Control \& Dense Synthesis, a new framework for unpaired video editing. Specifically, the sparse branch provides semantic guidance through user-edited keyframes distributed across the video, and the dense branch continuously incorporates motion and texture information from the original video to maintain high fidelity and coherence. Moreover, we introduce a degradation-simulation training strategy that enables the model to learn motion reconstruction and temporal consistency by training on artificially degraded videos, thus eliminating the need for paired data. Our extensive experiments demonstrate that NOVA outperforms existing approaches in edit fidelity, motion preservation, and temporal coherence.
StableWorld: Towards Stable and Consistent Long Interactive Video Generation
Jan 21, 2026In this paper, we explore the overlooked challenge of stability and temporal consistency in interactive video generation, which synthesizes dynamic and controllable video worlds through interactive behaviors such as camera movements and text prompts. Despite remarkable progress in world modeling, current methods still suffer from severe instability and temporal degradation, often leading to spatial drift and scene collapse during long-horizon interactions. To better understand this issue, we initially investigate the underlying causes of instability and identify that the major source of error accumulation originates from the same scene, where generated frames gradually deviate from the initial clean state and propagate errors to subsequent frames. Building upon this observation, we propose a simple yet effective method, \textbf{StableWorld}, a Dynamic Frame Eviction Mechanism. By continuously filtering out degraded frames while retaining geometrically consistent ones, StableWorld effectively prevents cumulative drift at its source, leading to more stable and temporal consistency of interactive generation. Promising results on multiple interactive video models, \eg, Matrix-Game, Open-Oasis, and Hunyuan-GameCraft, demonstrate that StableWorld is model-agnostic and can be applied to different interactive video generation frameworks to substantially improve stability, temporal consistency, and generalization across diverse interactive scenarios.
Rethinking Cross-Modal Interaction in Multimodal Diffusion Transformers
Jun 09, 2025



Multimodal Diffusion Transformers (MM-DiTs) have achieved remarkable progress in text-driven visual generation. However, even state-of-the-art MM-DiT models like FLUX struggle with achieving precise alignment between text prompts and generated content. We identify two key issues in the attention mechanism of MM-DiT, namely 1) the suppression of cross-modal attention due to token imbalance between visual and textual modalities and 2) the lack of timestep-aware attention weighting, which hinder the alignment. To address these issues, we propose \textbf{Temperature-Adjusted Cross-modal Attention (TACA)}, a parameter-efficient method that dynamically rebalances multimodal interactions through temperature scaling and timestep-dependent adjustment. When combined with LoRA fine-tuning, TACA significantly enhances text-image alignment on the T2I-CompBench benchmark with minimal computational overhead. We tested TACA on state-of-the-art models like FLUX and SD3.5, demonstrating its ability to improve image-text alignment in terms of object appearance, attribute binding, and spatial relationships. Our findings highlight the importance of balancing cross-modal attention in improving semantic fidelity in text-to-image diffusion models. Our codes are publicly available at \href{https://github.com/Vchitect/TACA}
RepVideo: Rethinking Cross-Layer Representation for Video Generation
Jan 15, 2025



Video generation has achieved remarkable progress with the introduction of diffusion models, which have significantly improved the quality of generated videos. However, recent research has primarily focused on scaling up model training, while offering limited insights into the direct impact of representations on the video generation process. In this paper, we initially investigate the characteristics of features in intermediate layers, finding substantial variations in attention maps across different layers. These variations lead to unstable semantic representations and contribute to cumulative differences between features, which ultimately reduce the similarity between adjacent frames and negatively affect temporal coherence. To address this, we propose RepVideo, an enhanced representation framework for text-to-video diffusion models. By accumulating features from neighboring layers to form enriched representations, this approach captures more stable semantic information. These enhanced representations are then used as inputs to the attention mechanism, thereby improving semantic expressiveness while ensuring feature consistency across adjacent frames. Extensive experiments demonstrate that our RepVideo not only significantly enhances the ability to generate accurate spatial appearances, such as capturing complex spatial relationships between multiple objects, but also improves temporal consistency in video generation.
FasterCache: Training-Free Video Diffusion Model Acceleration with High Quality
Oct 25, 2024



In this paper, we present \textbf{\textit{FasterCache}}, a novel training-free strategy designed to accelerate the inference of video diffusion models with high-quality generation. By analyzing existing cache-based methods, we observe that \textit{directly reusing adjacent-step features degrades video quality due to the loss of subtle variations}. We further perform a pioneering investigation of the acceleration potential of classifier-free guidance (CFG) and reveal significant redundancy between conditional and unconditional features within the same timestep. Capitalizing on these observations, we introduce FasterCache to substantially accelerate diffusion-based video generation. Our key contributions include a dynamic feature reuse strategy that preserves both feature distinction and temporal continuity, and CFG-Cache which optimizes the reuse of conditional and unconditional outputs to further enhance inference speed without compromising video quality. We empirically evaluate FasterCache on recent video diffusion models. Experimental results show that FasterCache can significantly accelerate video generation (\eg 1.67$\times$ speedup on Vchitect-2.0) while keeping video quality comparable to the baseline, and consistently outperform existing methods in both inference speed and video quality.
ConceptExpress: Harnessing Diffusion Models for Single-image Unsupervised Concept Extraction
Jul 09, 2024



While personalized text-to-image generation has enabled the learning of a single concept from multiple images, a more practical yet challenging scenario involves learning multiple concepts within a single image. However, existing works tackling this scenario heavily rely on extensive human annotations. In this paper, we introduce a novel task named Unsupervised Concept Extraction (UCE) that considers an unsupervised setting without any human knowledge of the concepts. Given an image that contains multiple concepts, the task aims to extract and recreate individual concepts solely relying on the existing knowledge from pretrained diffusion models. To achieve this, we present ConceptExpress that tackles UCE by unleashing the inherent capabilities of pretrained diffusion models in two aspects. Specifically, a concept localization approach automatically locates and disentangles salient concepts by leveraging spatial correspondence from diffusion self-attention; and based on the lookup association between a concept and a conceptual token, a concept-wise optimization process learns discriminative tokens that represent each individual concept. Finally, we establish an evaluation protocol tailored for the UCE task. Extensive experiments demonstrate that ConceptExpress is a promising solution to the UCE task. Our code and data are available at: https://github.com/haoosz/ConceptExpress
PLACE: Adaptive Layout-Semantic Fusion for Semantic Image Synthesis
Mar 04, 2024Recent advancements in large-scale pre-trained text-to-image models have led to remarkable progress in semantic image synthesis. Nevertheless, synthesizing high-quality images with consistent semantics and layout remains a challenge. In this paper, we propose the adaPtive LAyout-semantiC fusion modulE (PLACE) that harnesses pre-trained models to alleviate the aforementioned issues. Specifically, we first employ the layout control map to faithfully represent layouts in the feature space. Subsequently, we combine the layout and semantic features in a timestep-adaptive manner to synthesize images with realistic details. During fine-tuning, we propose the Semantic Alignment (SA) loss to further enhance layout alignment. Additionally, we introduce the Layout-Free Prior Preservation (LFP) loss, which leverages unlabeled data to maintain the priors of pre-trained models, thereby improving the visual quality and semantic consistency of synthesized images. Extensive experiments demonstrate that our approach performs favorably in terms of visual quality, semantic consistency, and layout alignment. The source code and model are available at https://github.com/cszy98/PLACE/tree/main.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022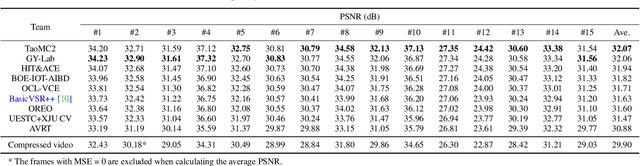
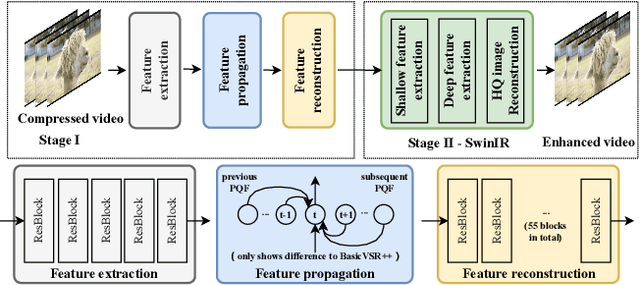
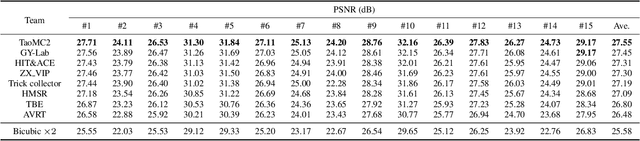

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Semantic-shape Adaptive Feature Modulation for Semantic Image Synthesis
Mar 31, 2022

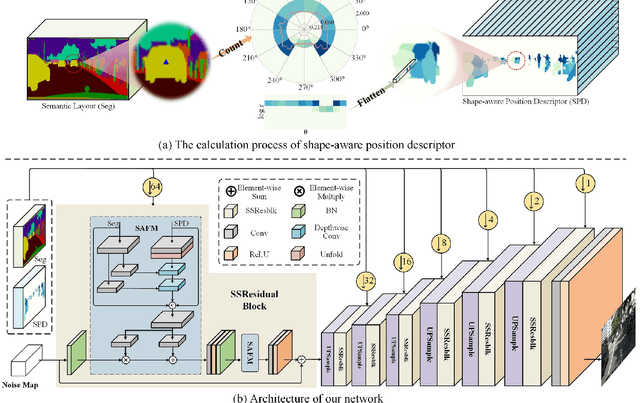
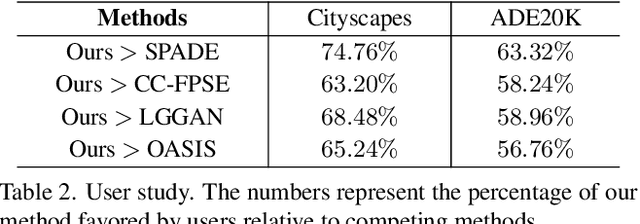
Recent years have witnessed substantial progress in semantic image synthesis, it is still challenging in synthesizing photo-realistic images with rich details. Most previous methods focus on exploiting the given semantic map, which just captures an object-level layout for an image. Obviously, a fine-grained part-level semantic layout will benefit object details generation, and it can be roughly inferred from an object's shape. In order to exploit the part-level layouts, we propose a Shape-aware Position Descriptor (SPD) to describe each pixel's positional feature, where object shape is explicitly encoded into the SPD feature. Furthermore, a Semantic-shape Adaptive Feature Modulation (SAFM) block is proposed to combine the given semantic map and our positional features to produce adaptively modulated features. Extensive experiments demonstrate that the proposed SPD and SAFM significantly improve the generation of objects with rich details. Moreover, our method performs favorably against the SOTA methods in terms of quantitative and qualitative evaluation. The source code and model are available at https://github.com/cszy98/SAFM.