 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Quantization: An Effective and Efficient Approach to Quantized Neural Networks
Jun 22, 2017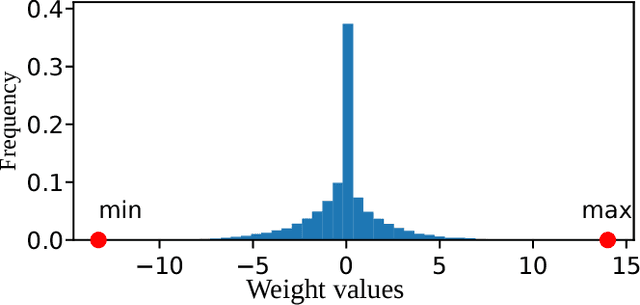
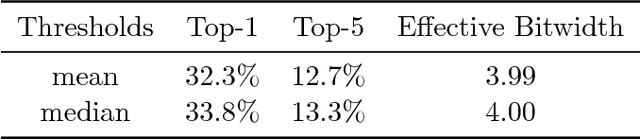
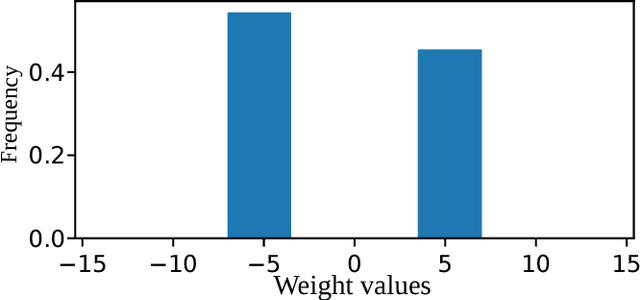

Quantized Neural Networks (QNNs), which use low bitwidth numbers for representing parameters and performing computations, have been proposed to reduce the computation complexity, storage size and memory usage. In QNNs, parameters and activations are uniformly quantized, such that the multiplications and additions can be accelerated by bitwise operations. However, distributions of parameters in Neural Networks are often imbalanced, such that the uniform quantization determined from extremal values may under utilize available bitwidth. In this paper, we propose a novel quantization method that can ensure the balance of distributions of quantized values. Our method first recursively partitions the parameters by percentiles into balanced bins, and then applies uniform quantization. We also introduce computationally cheaper approximations of percentiles to reduce the computation overhead introduced. Overall, our method improves the prediction accuracies of QNNs without introducing extra computation during inference, has negligible impact on training speed, and is applicable to both Convolutional Neural Networks and Recurrent Neural Networks. Experiments on standard datasets including ImageNet and Penn Treebank confirm the effectiveness of our method. On ImageNet, the top-5 error rate of our 4-bit quantized GoogLeNet model is 12.7\%, which is superior to the state-of-the-arts of QNNs.
GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data
May 14, 2017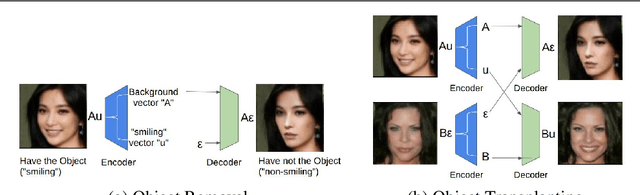
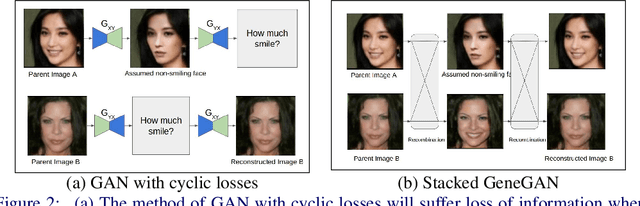
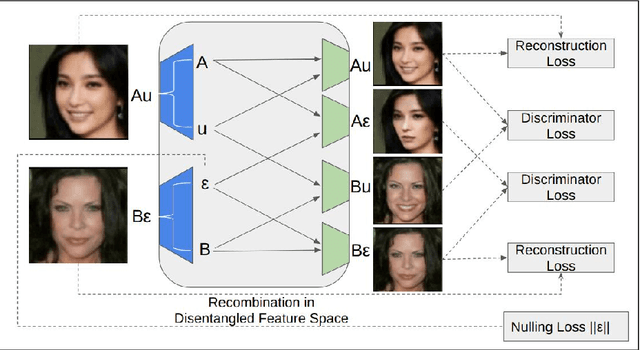

Object Transfiguration replaces an object in an image with another object from a second image. For example it can perform tasks like "putting exactly those eyeglasses from image A on the nose of the person in image B". Usage of exemplar images allows more precise specification of desired modifications and improves the diversity of conditional image generation. However, previous methods that rely on feature space operations, require paired data and/or appearance models for training or disentangling objects from background. In this work, we propose a model that can learn object transfiguration from two unpaired sets of images: one set containing images that "have" that kind of object, and the other set being the opposite, with the mild constraint that the objects be located approximately at the same place. For example, the training data can be one set of reference face images that have eyeglasses, and another set of images that have not, both of which spatially aligned by face landmarks. Despite the weak 0/1 labels, our model can learn an "eyeglasses" subspace that contain multiple representatives of different types of glasses. Consequently, we can perform fine-grained control of generated images, like swapping the glasses in two images by swapping the projected components in the "eyeglasses" subspace, to create novel images of people wearing eyeglasses. Overall, our deterministic generative model learns disentangled attribute subspaces from weakly labeled data by adversarial training. Experiments on CelebA and Multi-PIE datasets validate the effectiveness of the proposed model on real world data, in generating images with specified eyeglasses, smiling, hair styles, and lighting conditions etc. The code is available online.
Effective Quantization Methods for Recurrent Neural Networks
Nov 30, 2016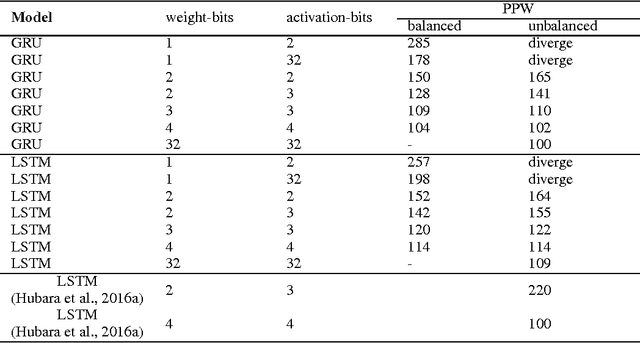
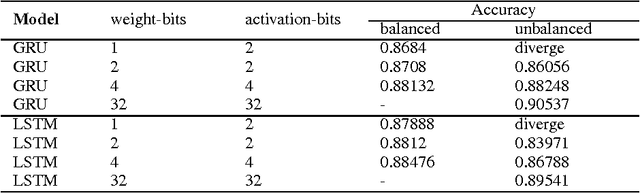
Reducing bit-widths of weights, activations, and gradients of a Neural Network can shrink its storage size and memory usage, and also allow for faster training and inference by exploiting bitwise operations. However, previous attempts for quantization of RNNs show considerable performance degradation when using low bit-width weights and activations. In this paper, we propose methods to quantize the structure of gates and interlinks in LSTM and GRU cells. In addition, we propose balanced quantization methods for weights to further reduce performance degradation. Experiments on PTB and IMDB datasets confirm effectiveness of our methods as performances of our models match or surpass the previous state-of-the-art of quantized RNN.