 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients
Feb 02, 2018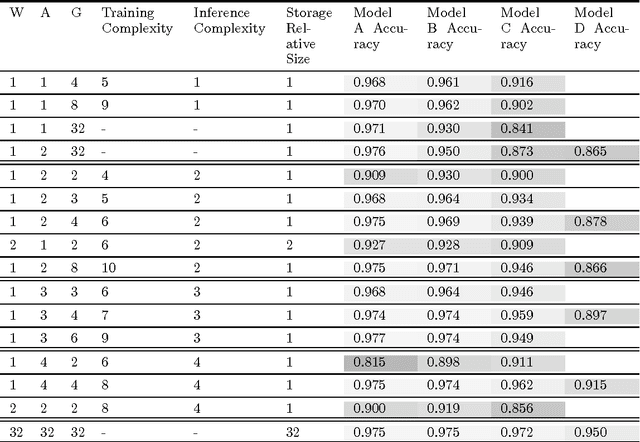
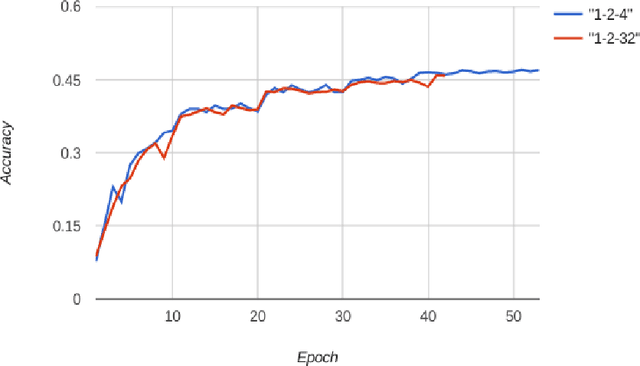
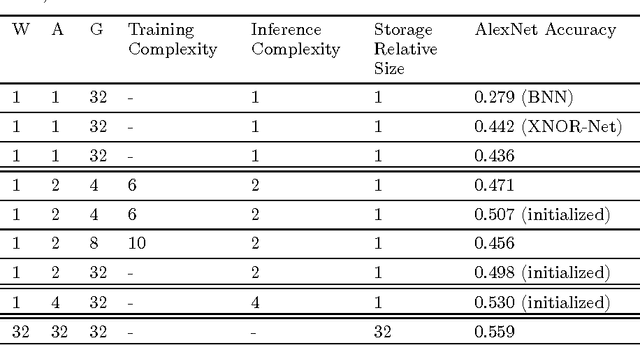
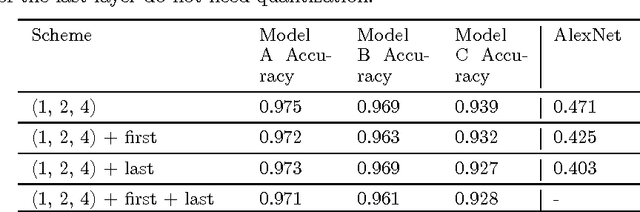
We propose DoReFa-Net, a method to train convolutional neural networks that have low bitwidth weights and activations using low bitwidth parameter gradients. In particular, during backward pass, parameter gradients are stochastically quantized to low bitwidth numbers before being propagated to convolutional layers. As convolutions during forward/backward passes can now operate on low bitwidth weights and activations/gradients respectively, DoReFa-Net can use bit convolution kernels to accelerate both training and inference. Moreover, as bit convolutions can be efficiently implemented on CPU, FPGA, ASIC and GPU, DoReFa-Net opens the way to accelerate training of low bitwidth neural network on these hardware. Our experiments on SVHN and ImageNet datasets prove that DoReFa-Net can achieve comparable prediction accuracy as 32-bit counterparts. For example, a DoReFa-Net derived from AlexNet that has 1-bit weights, 2-bit activations, can be trained from scratch using 6-bit gradients to get 46.1\% top-1 accuracy on ImageNet validation set. The DoReFa-Net AlexNet model is released publicly.
Balanced Quantization: An Effective and Efficient Approach to Quantized Neural Networks
Jun 22, 2017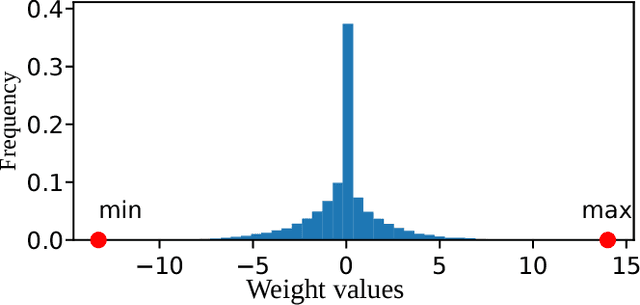
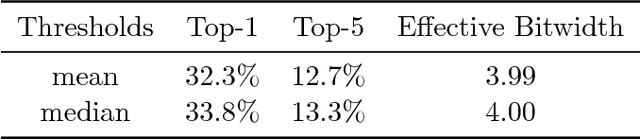

Quantized Neural Networks (QNNs), which use low bitwidth numbers for representing parameters and performing computations, have been proposed to reduce the computation complexity, storage size and memory usage. In QNNs, parameters and activations are uniformly quantized, such that the multiplications and additions can be accelerated by bitwise operations. However, distributions of parameters in Neural Networks are often imbalanced, such that the uniform quantization determined from extremal values may under utilize available bitwidth. In this paper, we propose a novel quantization method that can ensure the balance of distributions of quantized values. Our method first recursively partitions the parameters by percentiles into balanced bins, and then applies uniform quantization. We also introduce computationally cheaper approximations of percentiles to reduce the computation overhead introduced. Overall, our method improves the prediction accuracies of QNNs without introducing extra computation during inference, has negligible impact on training speed, and is applicable to both Convolutional Neural Networks and Recurrent Neural Networks. Experiments on standard datasets including ImageNet and Penn Treebank confirm the effectiveness of our method. On ImageNet, the top-5 error rate of our 4-bit quantized GoogLeNet model is 12.7\%, which is superior to the state-of-the-arts of QNNs.
Effective Quantization Methods for Recurrent Neural Networks
Nov 30, 2016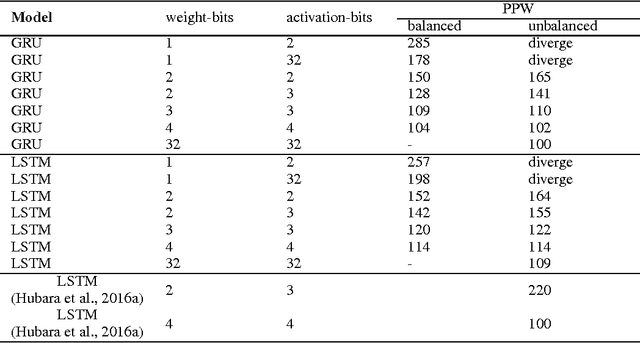
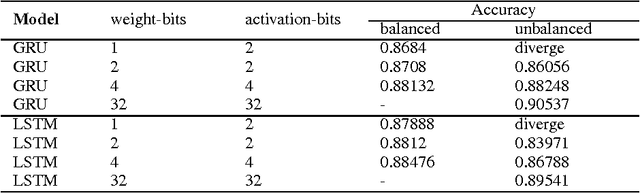
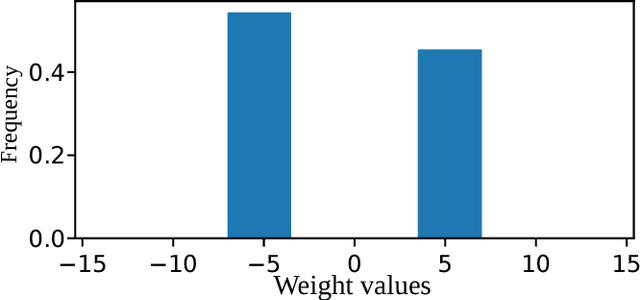
Reducing bit-widths of weights, activations, and gradients of a Neural Network can shrink its storage size and memory usage, and also allow for faster training and inference by exploiting bitwise operations. However, previous attempts for quantization of RNNs show considerable performance degradation when using low bit-width weights and activations. In this paper, we propose methods to quantize the structure of gates and interlinks in LSTM and GRU cells. In addition, we propose balanced quantization methods for weights to further reduce performance degradation. Experiments on PTB and IMDB datasets confirm effectiveness of our methods as performances of our models match or surpass the previous state-of-the-art of quantized RNN.