 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalEscaper: A Weakly-supervised Framework with Regional Reconstruction for Scalable Neural TSP Solvers
Feb 18, 2025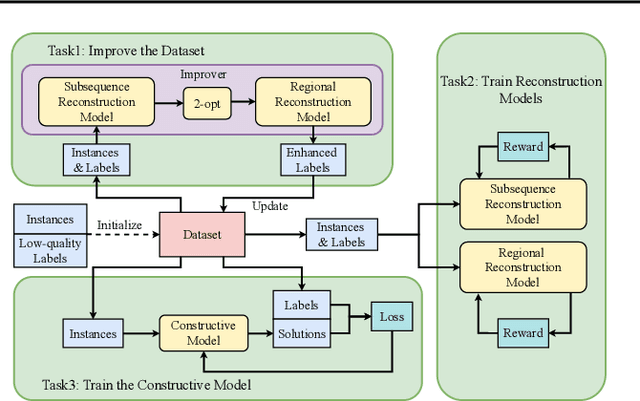
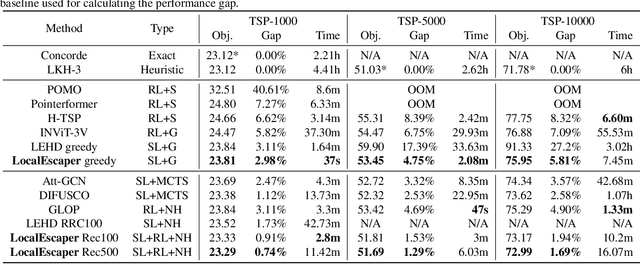
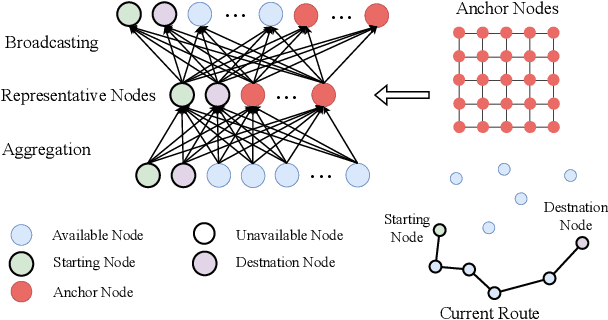
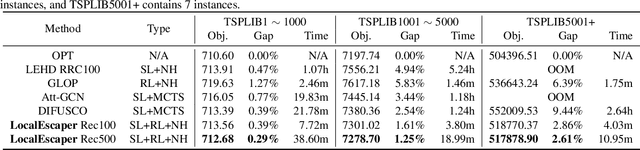
Neural solvers have shown significant potential in solving the Traveling Salesman Problem (TSP), yet current approaches face significant challenges. Supervised learning (SL)-based solvers require large amounts of high-quality labeled data, while reinforcement learning (RL)-based solvers, though less dependent on such data, often suffer from inefficiencies. To address these limitations, we propose LocalEscaper, a novel weakly-supervised learning framework for large-scale TSP. LocalEscaper effectively combines the advantages of both SL and RL, enabling effective training on datasets with low-quality labels. To further enhance solution quality, we introduce a regional reconstruction strategy, which mitigates the problem of local optima, a common issue in existing local reconstruction methods. Additionally, we propose a linear-complexity attention mechanism that reduces computational overhead, enabling the efficient solution of large-scale TSPs without sacrificing performance. Experimental results on both synthetic and real-world datasets demonstrate that LocalEscaper outperforms existing neural solvers, achieving state-of-the-art results. Notably, it sets a new benchmark for scalability and efficiency, solving TSP instances with up to 50,000 cities.
Multi-objective Deep Reinforcement Learning for Mobile Edge Computing
Jul 05, 2023



Mobile edge computing (MEC) is essential for next-generation mobile network applications that prioritize various performance metrics, including delays and energy consumption. However, conventional single-objective scheduling solutions cannot be directly applied to practical systems in which the preferences of these applications (i.e., the weights of different objectives) are often unknown or challenging to specify in advance. In this study, we address this issue by formulating a multi-objective offloading problem for MEC with multiple edges to minimize expected long-term energy consumption and transmission delay while considering unknown preferences as parameters. To address the challenge of unknown preferences, we design a multi-objective (deep) reinforcement learning (MORL)-based resource scheduling scheme with proximal policy optimization (PPO). In addition, we introduce a well-designed state encoding method for constructing features for multiple edges in MEC systems, a sophisticated reward function for accurately computing the utilities of delay and energy consumption. Simulation results demonstrate that our proposed MORL scheme enhances the hypervolume of the Pareto front by up to 233.1% compared to benchmarks. Our full framework is available at https://github.com/gracefulning/mec_morl_multipolicy.