 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilevel-in-Layer Training for Deep Neural Network Regression
Nov 11, 2022A common challenge in regression is that for many problems, the degrees of freedom required for a high-quality solution also allows for overfitting. Regularization is a class of strategies that seek to restrict the range of possible solutions so as to discourage overfitting while still enabling good solutions, and different regularization strategies impose different types of restrictions. In this paper, we present a multilevel regularization strategy that constructs and trains a hierarchy of neural networks, each of which has layers that are wider versions of the previous network's layers. We draw intuition and techniques from the field of Algebraic Multigrid (AMG), traditionally used for solving linear and nonlinear systems of equations, and specifically adapt the Full Approximation Scheme (FAS) for nonlinear systems of equations to the problem of deep learning. Training through V-cycles then encourage the neural networks to build a hierarchical understanding of the problem. We refer to this approach as \emph{multilevel-in-width} to distinguish from prior multilevel works which hierarchically alter the depth of neural networks. The resulting approach is a highly flexible framework that can be applied to a variety of layer types, which we demonstrate with both fully-connected and convolutional layers. We experimentally show with PDE regression problems that our multilevel training approach is an effective regularizer, improving the generalize performance of the neural networks studied.
Multiresolution Convolutional Autoencoders
Apr 10, 2020
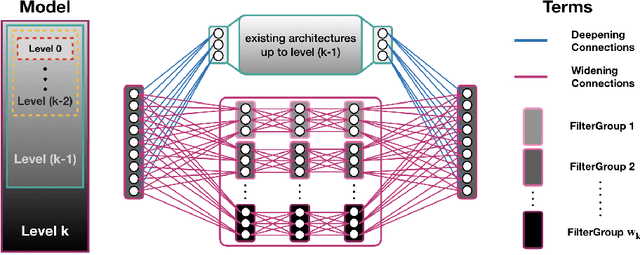
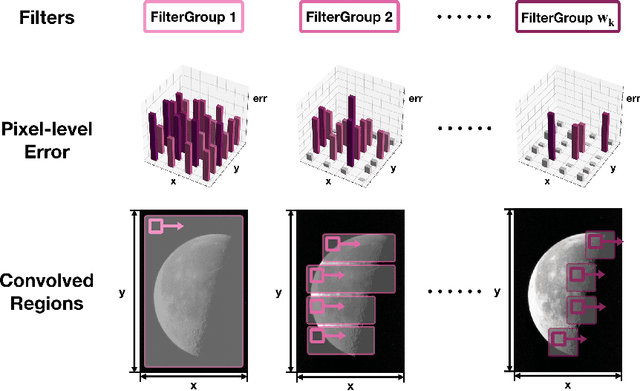

We propose a multi-resolution convolutional autoencoder (MrCAE) architecture that integrates and leverages three highly successful mathematical architectures: (i) multigrid methods, (ii) convolutional autoencoders and (iii) transfer learning. The method provides an adaptive, hierarchical architecture that capitalizes on a progressive training approach for multiscale spatio-temporal data. This framework allows for inputs across multiple scales: starting from a compact (small number of weights) network architecture and low-resolution data, our network progressively deepens and widens itself in a principled manner to encode new information in the higher resolution data based on its current performance of reconstruction. Basic transfer learning techniques are applied to ensure information learned from previous training steps can be rapidly transferred to the larger network. As a result, the network can dynamically capture different scaled features at different depths of the network. The performance gains of this adaptive multiscale architecture are illustrated through a sequence of numerical experiments on synthetic examples and real-world spatial-temporal data.
Unstructured Human Activity Detection from RGBD Images
Feb 14, 2012
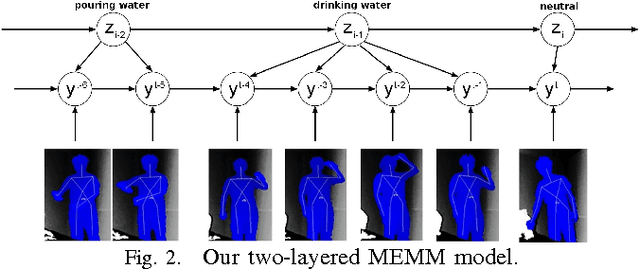


Being able to detect and recognize human activities is essential for several applications, including personal assistive robotics. In this paper, we perform detection and recognition of unstructured human activity in unstructured environments. We use a RGBD sensor (Microsoft Kinect) as the input sensor, and compute a set of features based on human pose and motion, as well as based on image and pointcloud information. Our algorithm is based on a hierarchical maximum entropy Markov model (MEMM), which considers a person's activity as composed of a set of sub-activities. We infer the two-layered graph structure using a dynamic programming approach. We test our algorithm on detecting and recognizing twelve different activities performed by four people in different environments, such as a kitchen, a living room, an office, etc., and achieve good performance even when the person was not seen before in the training set.