 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multimodal Embedding: Manipulating Novel Objects with Point-clouds, Language and Trajectories
Paper and Code
May 17, 2017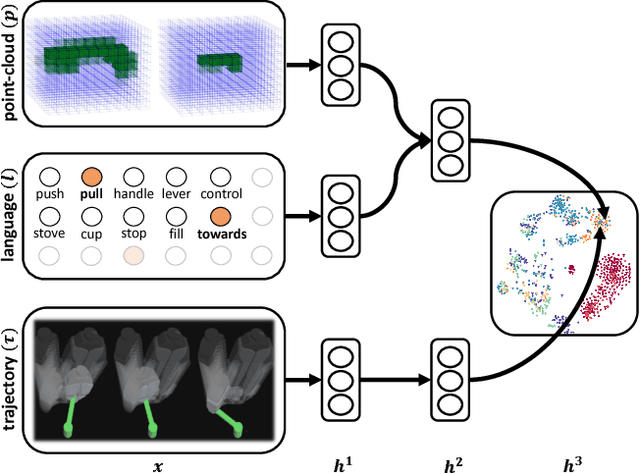
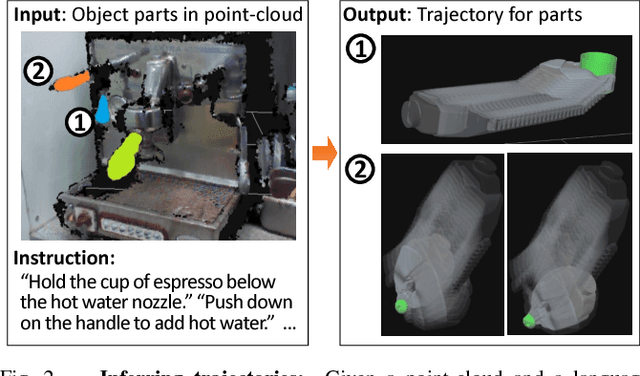
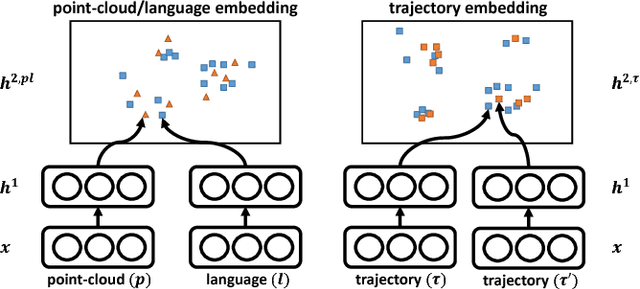
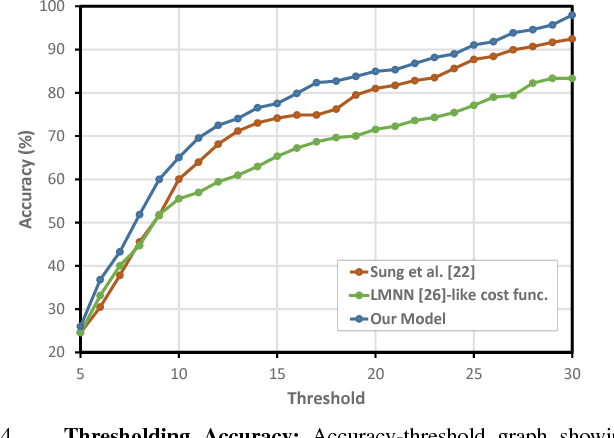
A robot operating in a real-world environment needs to perform reasoning over a variety of sensor modalities such as vision, language and motion trajectories. However, it is extremely challenging to manually design features relating such disparate modalities. In this work, we introduce an algorithm that learns to embed point-cloud, natural language, and manipulation trajectory data into a shared embedding space with a deep neural network. To learn semantically meaningful spaces throughout our network, we use a loss-based margin to bring embeddings of relevant pairs closer together while driving less-relevant cases from different modalities further apart. We use this both to pre-train its lower layers and fine-tune our final embedding space, leading to a more robust representation. We test our algorithm on the task of manipulating novel objects and appliances based on prior experience with other objects. On a large dataset, we achieve significant improvements in both accuracy and inference time over the previous state of the art. We also perform end-to-end experiments on a PR2 robot utilizing our learned embedding space.