 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multimodal Embedding: Manipulating Novel Objects with Point-clouds, Language and Trajectories
May 17, 2017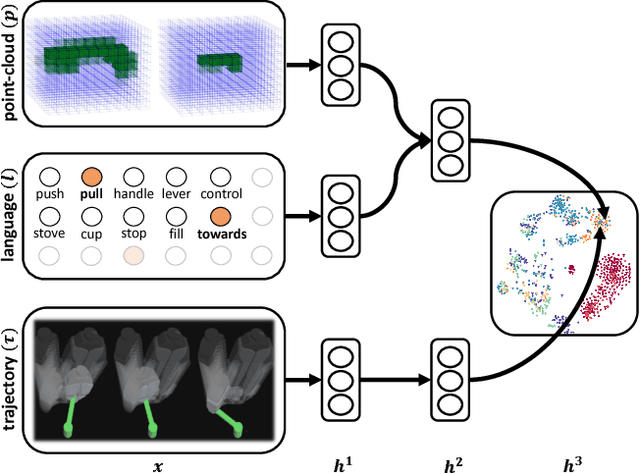
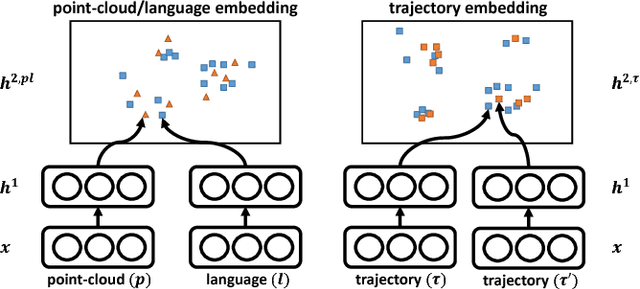
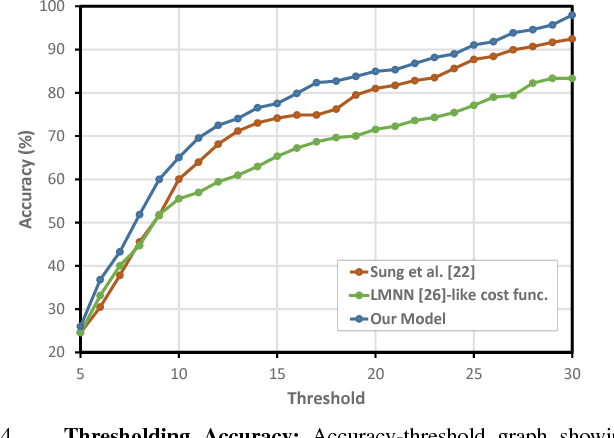
A robot operating in a real-world environment needs to perform reasoning over a variety of sensor modalities such as vision, language and motion trajectories. However, it is extremely challenging to manually design features relating such disparate modalities. In this work, we introduce an algorithm that learns to embed point-cloud, natural language, and manipulation trajectory data into a shared embedding space with a deep neural network. To learn semantically meaningful spaces throughout our network, we use a loss-based margin to bring embeddings of relevant pairs closer together while driving less-relevant cases from different modalities further apart. We use this both to pre-train its lower layers and fine-tune our final embedding space, leading to a more robust representation. We test our algorithm on the task of manipulating novel objects and appliances based on prior experience with other objects. On a large dataset, we achieve significant improvements in both accuracy and inference time over the previous state of the art. We also perform end-to-end experiments on a PR2 robot utilizing our learned embedding space.
Robobarista: Learning to Manipulate Novel Objects via Deep Multimodal Embedding
Jan 12, 2016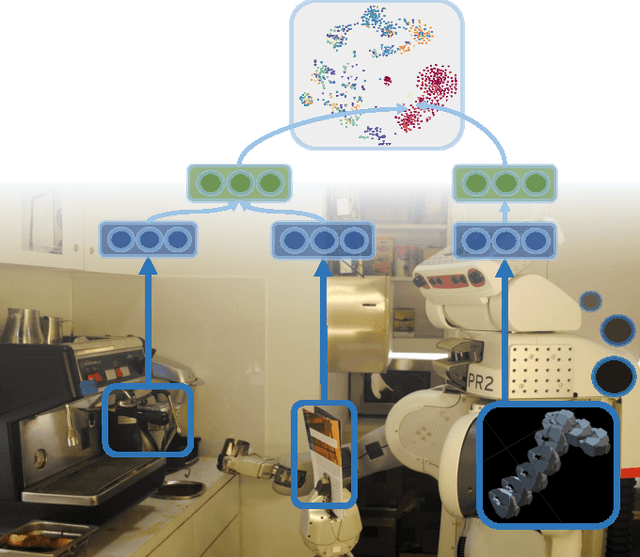

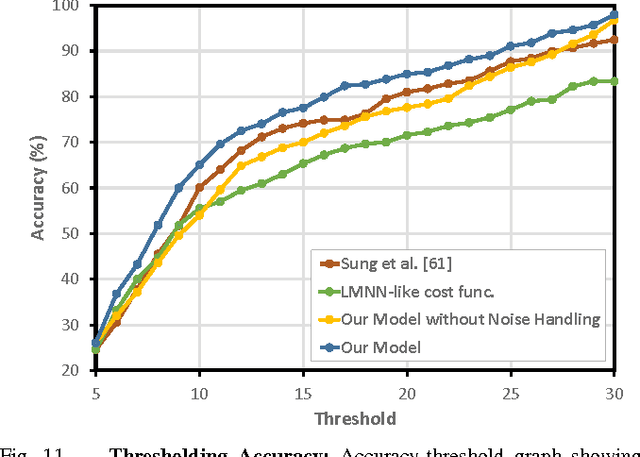
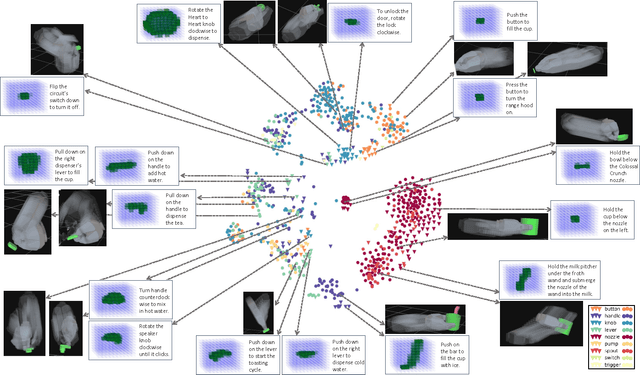
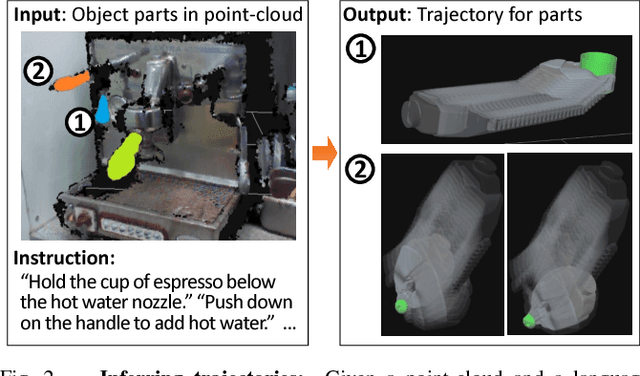
There is a large variety of objects and appliances in human environments, such as stoves, coffee dispensers, juice extractors, and so on. It is challenging for a roboticist to program a robot for each of these object types and for each of their instantiations. In this work, we present a novel approach to manipulation planning based on the idea that many household objects share similarly-operated object parts. We formulate the manipulation planning as a structured prediction problem and learn to transfer manipulation strategy across different objects by embedding point-cloud, natural language, and manipulation trajectory data into a shared embedding space using a deep neural network. In order to learn semantically meaningful spaces throughout our network, we introduce a method for pre-training its lower layers for multimodal feature embedding and a method for fine-tuning this embedding space using a loss-based margin. In order to collect a large number of manipulation demonstrations for different objects, we develop a new crowd-sourcing platform called Robobarista. We test our model on our dataset consisting of 116 objects and appliances with 249 parts along with 250 language instructions, for which there are 1225 crowd-sourced manipulation demonstrations. We further show that our robot with our model can even prepare a cup of a latte with appliances it has never seen before.
Deep Learning for Detecting Robotic Grasps
Aug 21, 2014


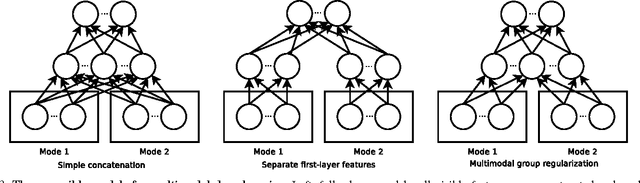
We consider the problem of detecting robotic grasps in an RGB-D view of a scene containing objects. In this work, we apply a deep learning approach to solve this problem, which avoids time-consuming hand-design of features. This presents two main challenges. First, we need to evaluate a huge number of candidate grasps. In order to make detection fast, as well as robust, we present a two-step cascaded structure with two deep networks, where the top detections from the first are re-evaluated by the second. The first network has fewer features, is faster to run, and can effectively prune out unlikely candidate grasps. The second, with more features, is slower but has to run only on the top few detections. Second, we need to handle multimodal inputs well, for which we present a method to apply structured regularization on the weights based on multimodal group regularization. We demonstrate that our method outperforms the previous state-of-the-art methods in robotic grasp detection, and can be used to successfully execute grasps on two different robotic platforms.