 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Detecting Robotic Grasps
Paper and Code
Aug 21, 2014


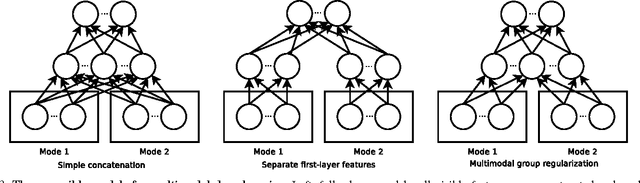
We consider the problem of detecting robotic grasps in an RGB-D view of a scene containing objects. In this work, we apply a deep learning approach to solve this problem, which avoids time-consuming hand-design of features. This presents two main challenges. First, we need to evaluate a huge number of candidate grasps. In order to make detection fast, as well as robust, we present a two-step cascaded structure with two deep networks, where the top detections from the first are re-evaluated by the second. The first network has fewer features, is faster to run, and can effectively prune out unlikely candidate grasps. The second, with more features, is slower but has to run only on the top few detections. Second, we need to handle multimodal inputs well, for which we present a method to apply structured regularization on the weights based on multimodal group regularization. We demonstrate that our method outperforms the previous state-of-the-art methods in robotic grasp detection, and can be used to successfully execute grasps on two different robotic platforms.